 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShielded Reinforcement Learning for Hybrid Systems
Aug 28, 2023Safe and optimal controller synthesis for switched-controlled hybrid systems, which combine differential equations and discrete changes of the system's state, is known to be intricately hard. Reinforcement learning has been leveraged to construct near-optimal controllers, but their behavior is not guaranteed to be safe, even when it is encouraged by reward engineering. One way of imposing safety to a learned controller is to use a shield, which is correct by design. However, obtaining a shield for non-linear and hybrid environments is itself intractable. In this paper, we propose the construction of a shield using the so-called barbaric method, where an approximate finite representation of an underlying partition-based two-player safety game is extracted via systematically picked samples of the true transition function. While hard safety guarantees are out of reach, we experimentally demonstrate strong statistical safety guarantees with a prototype implementation and UPPAAL STRATEGO. Furthermore, we study the impact of the synthesized shield when applied as either a pre-shield (applied before learning a controller) or a post-shield (only applied after learning a controller). We experimentally demonstrate superiority of the pre-shielding approach. We apply our technique on a range of case studies, including two industrial examples, and further study post-optimization of the post-shielding approach.
It's Time to Play Safe: Shield Synthesis for Timed Systems
Jun 30, 2020
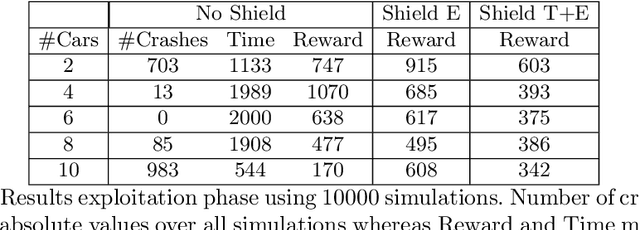
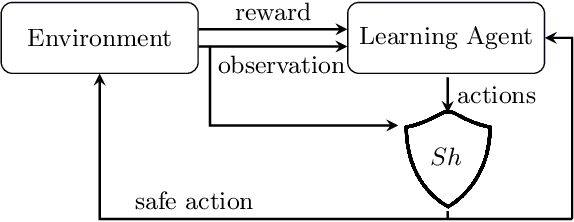
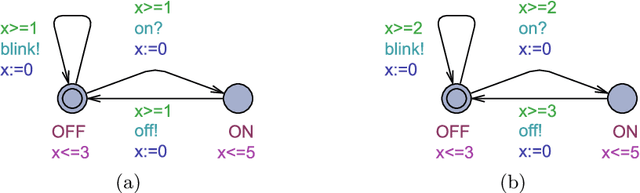
Erroneous behaviour in safety critical real-time systems may inflict serious consequences. In this paper, we show how to synthesize timed shields from timed safety properties given as timed automata. A timed shield enforces the safety of a running system while interfering with the system as little as possible. We present timed post-shields and timed pre-shields. A timed pre-shield is placed before the system and provides a set of safe outputs. This set restricts the choices of the system. A timed post-shield is implemented after the system. It monitors the system and corrects the system's output only if necessary. We further extend the timed post-shield construction to provide a guarantee on the recovery phase, i.e., the time between a specification violation and the point at which full control can be handed back to the system. In our experimental results, we use timed post-shields to ensure the safety in a reinforcement learning setting for controlling a platoon of cars, during the learning and execution phase, and study the effect.
Approximating Euclidean by Imprecise Markov Decision Processes
Jun 26, 2020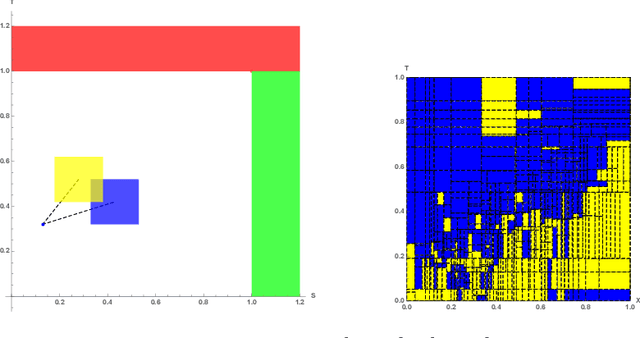
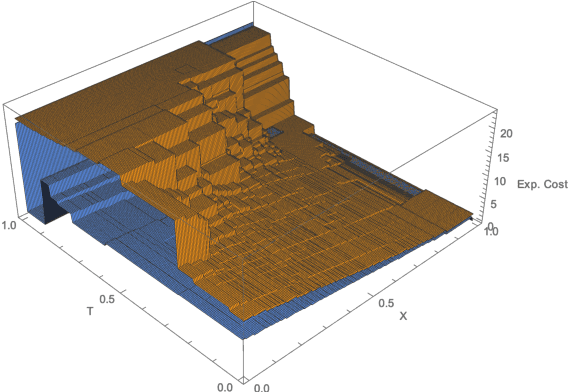
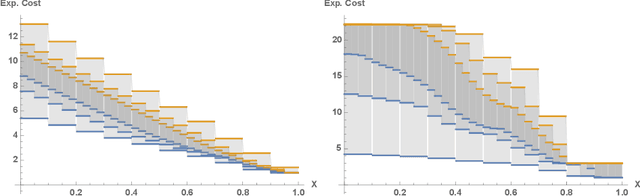
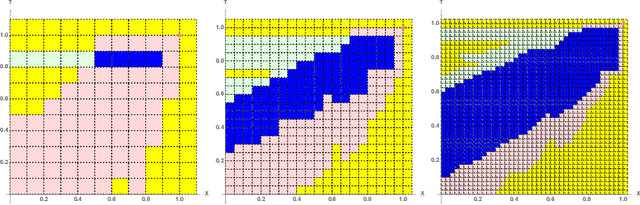
Euclidean Markov decision processes are a powerful tool for modeling control problems under uncertainty over continuous domains. Finite state imprecise, Markov decision processes can be used to approximate the behavior of these infinite models. In this paper we address two questions: first, we investigate what kind of approximation guarantees are obtained when the Euclidean process is approximated by finite state approximations induced by increasingly fine partitions of the continuous state space. We show that for cost functions over finite time horizons the approximations become arbitrarily precise. Second, we use imprecise Markov decision process approximations as a tool to analyse and validate cost functions and strategies obtained by reinforcement learning. We find that, on the one hand, our new theoretical results validate basic design choices of a previously proposed reinforcement learning approach. On the other hand, the imprecise Markov decision process approximations reveal some inaccuracies in the learned cost functions.