 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomata Learning meets Shielding
Dec 04, 2022Safety is still one of the major research challenges in reinforcement learning (RL). In this paper, we address the problem of how to avoid safety violations of RL agents during exploration in probabilistic and partially unknown environments. Our approach combines automata learning for Markov Decision Processes (MDPs) and shield synthesis in an iterative approach. Initially, the MDP representing the environment is unknown. The agent starts exploring the environment and collects traces. From the collected traces, we passively learn MDPs that abstractly represent the safety-relevant aspects of the environment. Given a learned MDP and a safety specification, we construct a shield. For each state-action pair within a learned MDP, the shield computes exact probabilities on how likely it is that executing the action results in violating the specification from the current state within the next $k$ steps. After the shield is constructed, the shield is used during runtime and blocks any actions that induce a too large risk from the agent. The shielded agent continues to explore the environment and collects new data on the environment. Iteratively, we use the collected data to learn new MDPs with higher accuracy, resulting in turn in shields able to prevent more safety violations. We implemented our approach and present a detailed case study of a Q-learning agent exploring slippery Gridworlds. In our experiments, we show that as the agent explores more and more of the environment during training, the improved learned models lead to shields that are able to prevent many safety violations.
Active Learning of Markov Decision Processes using Baum-Welch algorithm (Extended)
Oct 06, 2021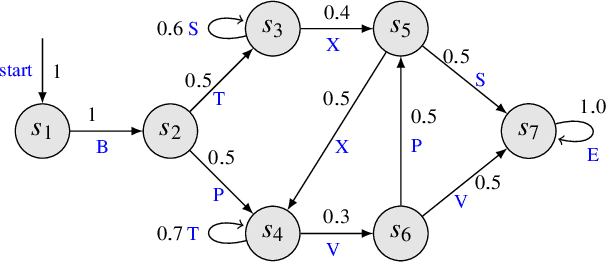
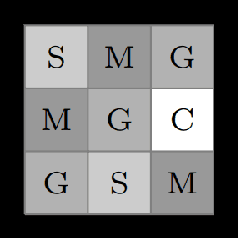
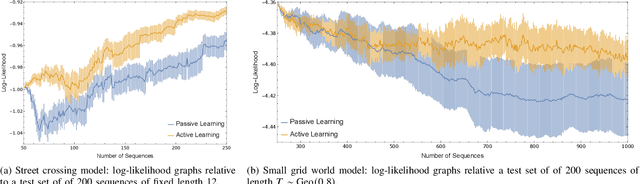
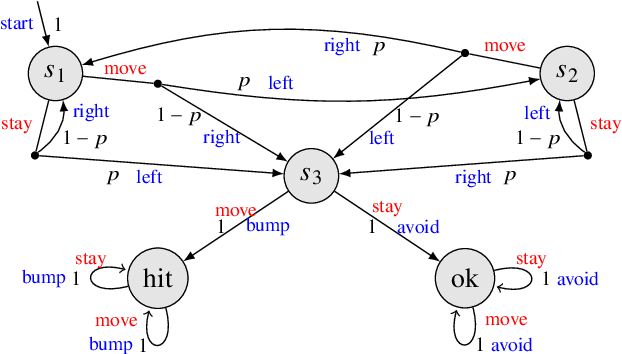
Cyber-physical systems (CPSs) are naturally modelled as reactive systems with nondeterministic and probabilistic dynamics. Model-based verification techniques have proved effective in the deployment of safety-critical CPSs. Central for a successful application of such techniques is the construction of an accurate formal model for the system. Manual construction can be a resource-demanding and error-prone process, thus motivating the design of automata learning algorithms to synthesise a system model from observed system behaviours. This paper revisits and adapts the classic Baum-Welch algorithm for learning Markov decision processes and Markov chains. For the case of MDPs, which typically demand more observations, we present a model-based active learning sampling strategy that choses examples which are most informative w.r.t.\ the current model hypothesis. We empirically compare our approach with state-of-the-art tools and demonstrate that the proposed active learning procedure can significantly reduce the number of observations required to obtain accurate models.