 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalizing and Guaranteeing* Human-Robot Interaction
Jun 30, 2020
Robot capabilities are maturing across domains, from self-driving cars, to bipeds and drones. As a result, robots will soon no longer be confined to safety-controlled industrial settings; instead, they will directly interact with the general public. The growing field of Human-Robot Interaction (HRI) studies various aspects of this scenario - from social norms to joint action to human-robot teams and more. Researchers in HRI have made great strides in developing models, methods, and algorithms for robots acting with and around humans, but these "computational HRI" models and algorithms generally do not come with formal guarantees and constraints on their operation. To enable human-interactive robots to move from the lab to real-world deployments, we must address this gap. This article provides an overview of verification, validation and synthesis techniques used to create demonstrably trustworthy systems, describes several HRI domains that could benefit from such techniques, and provides a roadmap for the challenges and the research needed to create formalized and guaranteed human-robot interaction.
Safe Reinforcement Learning via Shielding
Sep 03, 2017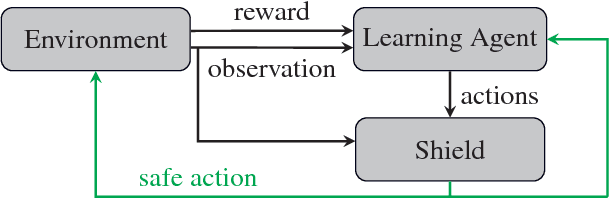
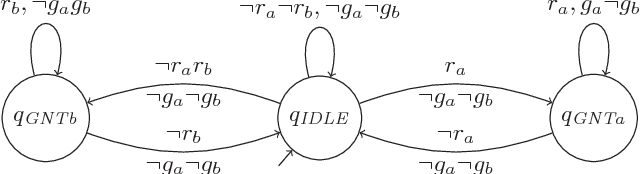
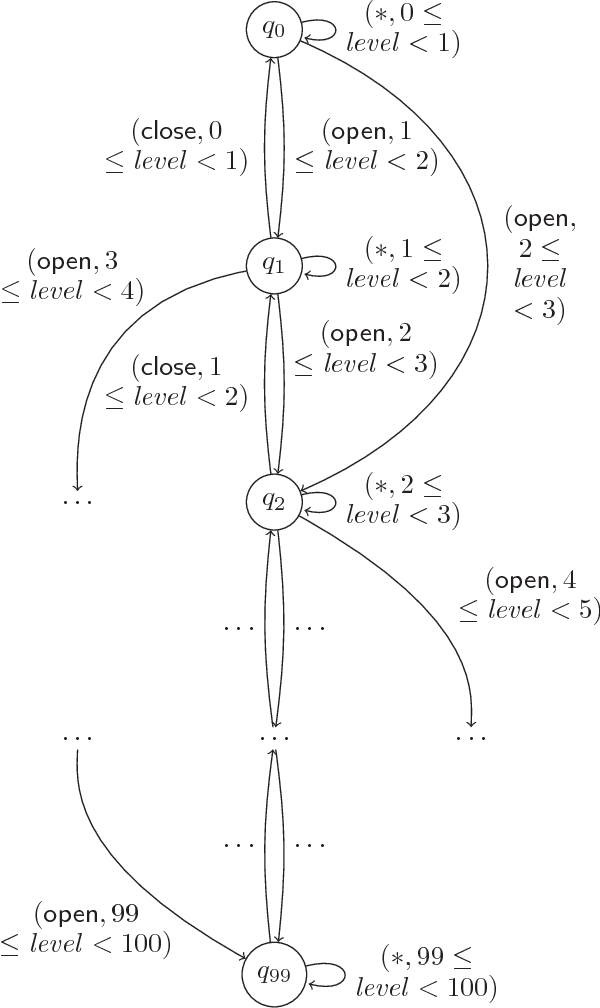
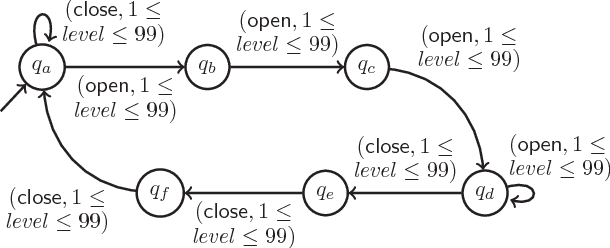
Reinforcement learning algorithms discover policies that maximize reward, but do not necessarily guarantee safety during learning or execution phases. We introduce a new approach to learn optimal policies while enforcing properties expressed in temporal logic. To this end, given the temporal logic specification that is to be obeyed by the learning system, we propose to synthesize a reactive system called a shield. The shield is introduced in the traditional learning process in two alternative ways, depending on the location at which the shield is implemented. In the first one, the shield acts each time the learning agent is about to make a decision and provides a list of safe actions. In the second way, the shield is introduced after the learning agent. The shield monitors the actions from the learner and corrects them only if the chosen action causes a violation of the specification. We discuss which requirements a shield must meet to preserve the convergence guarantees of the learner. Finally, we demonstrate the versatility of our approach on several challenging reinforcement learning scenarios.
Formal Verification of Piece-Wise Linear Feed-Forward Neural Networks
Aug 02, 2017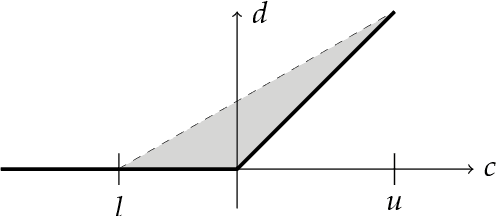
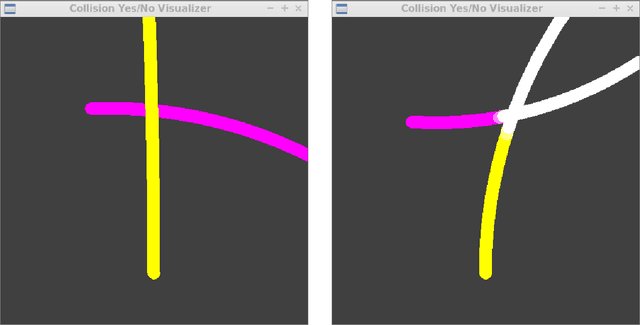
We present an approach for the verification of feed-forward neural networks in which all nodes have a piece-wise linear activation function. Such networks are often used in deep learning and have been shown to be hard to verify for modern satisfiability modulo theory (SMT) and integer linear programming (ILP) solvers. The starting point of our approach is the addition of a global linear approximation of the overall network behavior to the verification problem that helps with SMT-like reasoning over the network behavior. We present a specialized verification algorithm that employs this approximation in a search process in which it infers additional node phases for the non-linear nodes in the network from partial node phase assignments, similar to unit propagation in classical SAT solving. We also show how to infer additional conflict clauses and safe node fixtures from the results of the analysis steps performed during the search. The resulting approach is evaluated on collision avoidance and handwritten digit recognition case studies.
Risk-Averse $ω$-regular Markov Decision Process Control
May 02, 2017
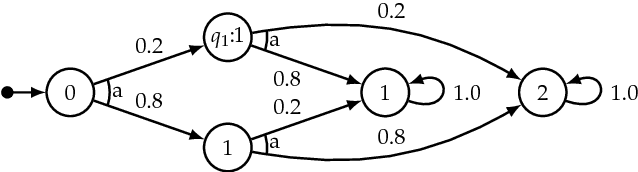

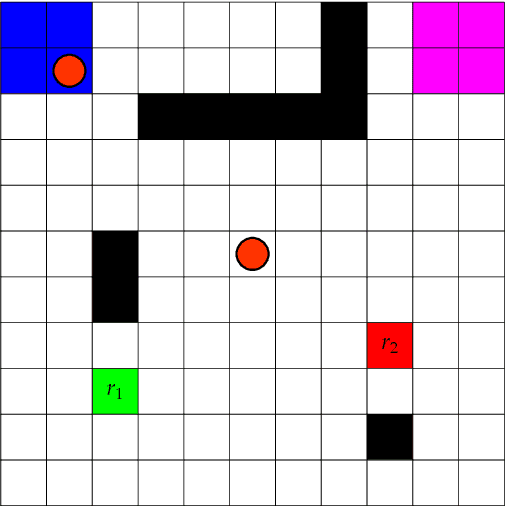
Many control problems in environments that can be modeled as Markov decision processes (MDPs) concern infinite-time horizon specifications. The classical aim in this context is to compute a control policy that maximizes the probability of satisfying the specification. In many scenarios, there is however a non-zero probability of failure in every step of the system's execution. For infinite-time horizon specifications, this implies that the specification is violated with probability 1 in the long run no matter what policy is chosen, which prevents previous policy computation methods from being useful in these scenarios. In this paper, we introduce a new optimization criterion for MDP policies that captures the task of working towards the satisfaction of some infinite-time horizon $\omega$-regular specification. The new criterion is applicable to MDPs in which the violation of the specification cannot be avoided in the long run. We give an algorithm to compute policies that are optimal in this criterion and show that it captures the ideas of optimism and risk-averseness in MDP control: while the computed policies are optimistic in that a MDP run enters a failure state relatively late, they are risk-averse by always maximizing the probability to reach their respective next goal state. We give results on two robot control scenarios to validate the usability of risk-averse MDP policies.
Dynamics-Based Reactive Synthesis and Automated Revisions for High-Level Robot Control
Jan 13, 2016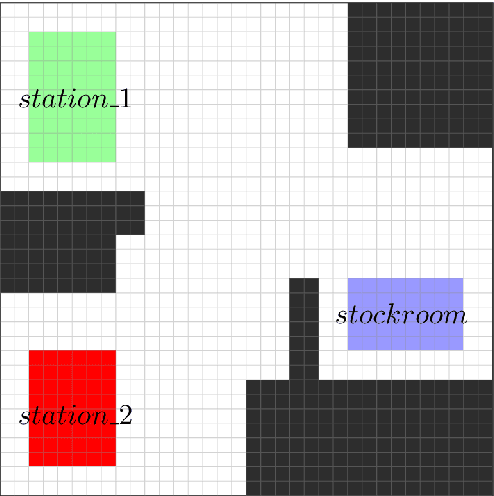
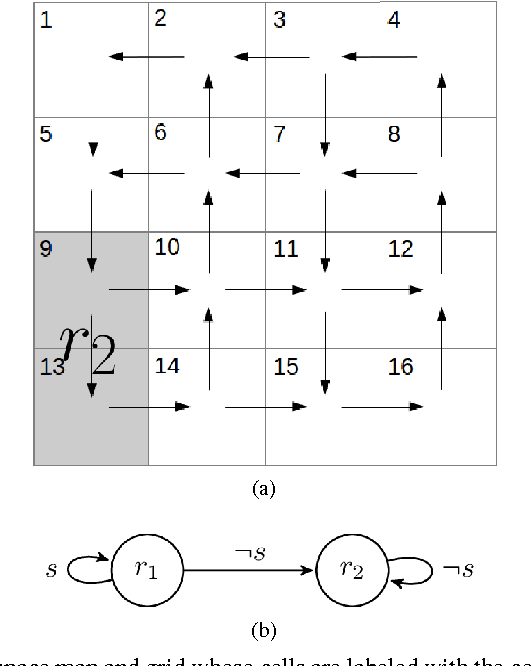
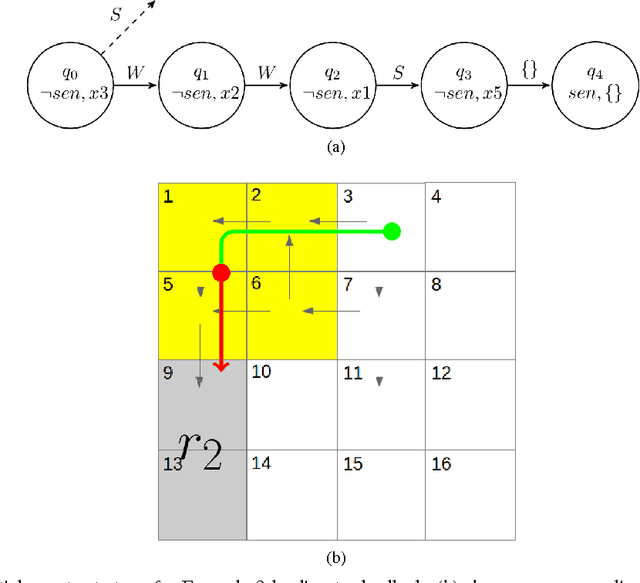
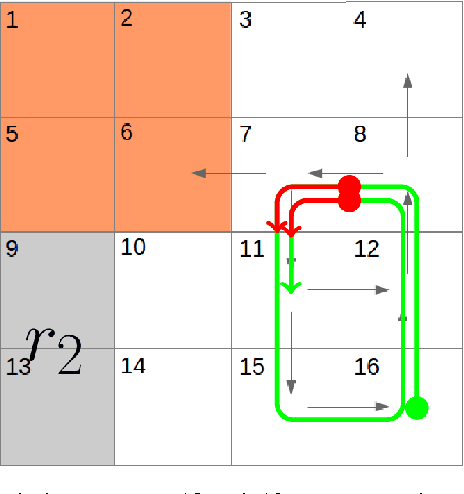
The aim of this work is to address issues where formal specifications cannot be realized on a given dynamical system subjected to a changing environment. Such failures occur whenever the dynamics of the system restrict the robot in such a way that the environment may prevent the robot from progressing safely to its goals. We provide a framework that automatically synthesizes revisions to such specifications that restrict the assumed behaviors of the environment and the behaviors of the system. We provide a means for explaining such modifications to the user in a concise, easy-to-understand manner. Integral to the framework is a new algorithm for synthesizing controllers for reactive specifications that include a discrete representation of the robot's dynamics. The new approach is demonstrated with a complex task implemented using a unicycle model.
Correct-by-synthesis reinforcement learning with temporal logic constraints
Mar 05, 2015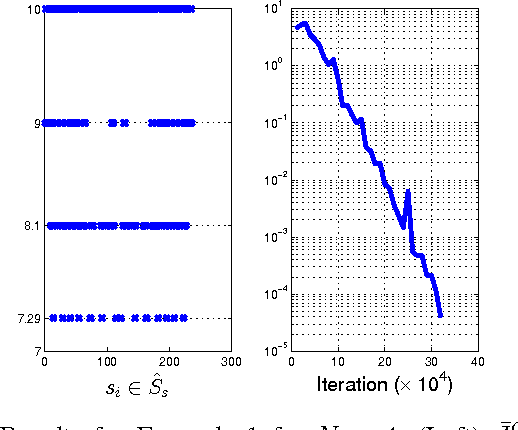


We consider a problem on the synthesis of reactive controllers that optimize some a priori unknown performance criterion while interacting with an uncontrolled environment such that the system satisfies a given temporal logic specification. We decouple the problem into two subproblems. First, we extract a (maximally) permissive strategy for the system, which encodes multiple (possibly all) ways in which the system can react to the adversarial environment and satisfy the specifications. Then, we quantify the a priori unknown performance criterion as a (still unknown) reward function and compute an optimal strategy for the system within the operating envelope allowed by the permissive strategy by using the so-called maximin-Q learning algorithm. We establish both correctness (with respect to the temporal logic specifications) and optimality (with respect to the a priori unknown performance criterion) of this two-step technique for a fragment of temporal logic specifications. For specifications beyond this fragment, correctness can still be preserved, but the learned strategy may be sub-optimal. We present an algorithm to the overall problem, and demonstrate its use and computational requirements on a set of robot motion planning examples.