 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Averse $ω$-regular Markov Decision Process Control
Paper and Code
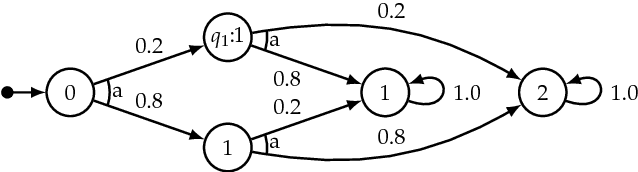

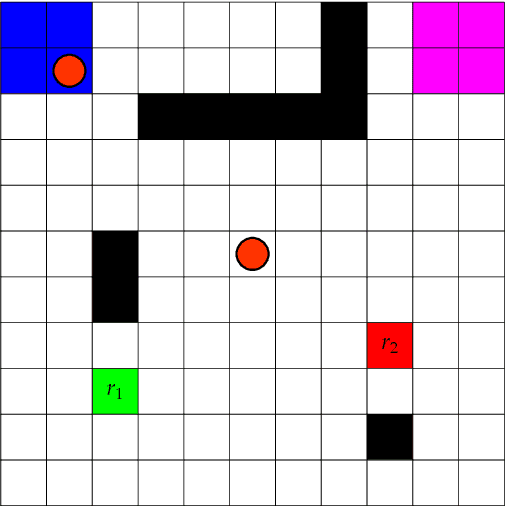
Many control problems in environments that can be modeled as Markov decision processes (MDPs) concern infinite-time horizon specifications. The classical aim in this context is to compute a control policy that maximizes the probability of satisfying the specification. In many scenarios, there is however a non-zero probability of failure in every step of the system's execution. For infinite-time horizon specifications, this implies that the specification is violated with probability 1 in the long run no matter what policy is chosen, which prevents previous policy computation methods from being useful in these scenarios. In this paper, we introduce a new optimization criterion for MDP policies that captures the task of working towards the satisfaction of some infinite-time horizon $\omega$-regular specification. The new criterion is applicable to MDPs in which the violation of the specification cannot be avoided in the long run. We give an algorithm to compute policies that are optimal in this criterion and show that it captures the ideas of optimism and risk-averseness in MDP control: while the computed policies are optimistic in that a MDP run enters a failure state relatively late, they are risk-averse by always maximizing the probability to reach their respective next goal state. We give results on two robot control scenarios to validate the usability of risk-averse MDP policies.