 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrect-by-synthesis reinforcement learning with temporal logic constraints
Paper and Code
Mar 05, 2015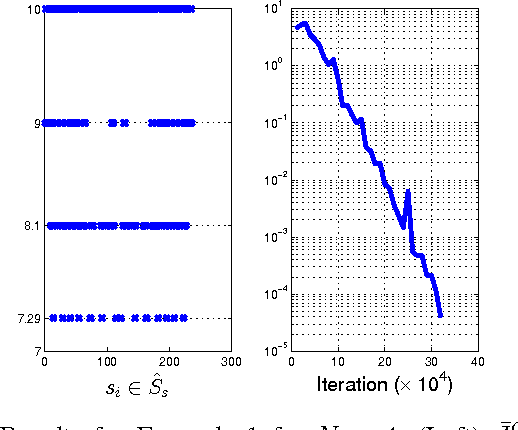

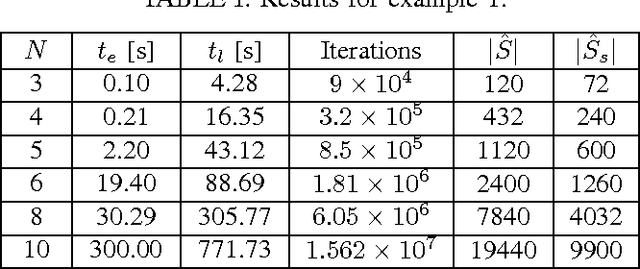

We consider a problem on the synthesis of reactive controllers that optimize some a priori unknown performance criterion while interacting with an uncontrolled environment such that the system satisfies a given temporal logic specification. We decouple the problem into two subproblems. First, we extract a (maximally) permissive strategy for the system, which encodes multiple (possibly all) ways in which the system can react to the adversarial environment and satisfy the specifications. Then, we quantify the a priori unknown performance criterion as a (still unknown) reward function and compute an optimal strategy for the system within the operating envelope allowed by the permissive strategy by using the so-called maximin-Q learning algorithm. We establish both correctness (with respect to the temporal logic specifications) and optimality (with respect to the a priori unknown performance criterion) of this two-step technique for a fragment of temporal logic specifications. For specifications beyond this fragment, correctness can still be preserved, but the learned strategy may be sub-optimal. We present an algorithm to the overall problem, and demonstrate its use and computational requirements on a set of robot motion planning examples.