 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-TRAIL: A Commonsense World Framework for Trajectory Planning in Autonomous Driving
Mar 31, 2026Trajectory planning for autonomous driving increasingly leverages large language models (LLMs) for commonsense reasoning, yet LLM outputs are inherently unreliable, posing risks in safety-critical applications. We propose C-TRAIL, a framework built on a Commonsense World that couples LLM-derived commonsense with a trust mechanism to guide trajectory planning. C-TRAIL operates through a closed-loop Recall, Plan, and Update cycle: the Recall module queries an LLM for semantic relations and quantifies their reliability via a dual-trust mechanism; the Plan module injects trust-weighted commonsense into Monte Carlo Tree Search (MCTS) through a Dirichlet trust policy; and the Update module adaptively refines trust scores and policy parameters from environmental feedback. Experiments on four simulated scenarios in Highway-env and two real-world levelXData datasets (highD, rounD) show that C-TRAIL consistently outperforms state-of-the-art baselines, reducing ADE by 40.2%, FDE by 51.7%, and improving SR by 16.9 percentage points on average. The source code is available at https://github.com/ZhihongCui/CTRAIL.
FEAT: A Linear-Complexity Foundation Model for Extremely Large Structured Data
Mar 17, 2026Structured data is foundational to healthcare, finance, e-commerce, and scientific data management. Large structured-data models (LDMs) extend the foundation model paradigm to unify heterogeneous datasets for tasks such as classification, regression, and decision support. However, existing LDMs face major limitations. First, most rely on sample-wise self-attention, whose O(N^2) complexity limits the sample count. Second, linear sequence models often degrade representations due to hidden-state compression and artificial causal bias. Third, synthetic-only pre-training often fails to match real-world distributions. We propose FEAT, a linear-complexity foundation model for extremely large structured data. FEAT introduces a multi-layer dual-axis architecture that replaces quadratic attention with hybrid linear encoding. The architecture combines adaptive-fusion bi-Mamba-2 (AFBM) for local sample dependencies and convolutional gated linear attention (Conv-GLA) for global memory. This design enables linear-complexity cross-sample modeling while preserving expressive representations. To improve robustness, FEAT adopts a hybrid structural causal model pipeline and a stable reconstruction objective. Experiments on 11 real-world datasets show that FEAT consistently outperforms baselines in zero-shot performance, while scaling linearly and achieving up to 40x faster inference.
TCRL: Temporal-Coupled Adversarial Training for Robust Constrained Reinforcement Learning in Worst-Case Scenarios
Feb 13, 2026Constrained Reinforcement Learning (CRL) aims to optimize decision-making policies under constraint conditions, making it highly applicable to safety-critical domains such as autonomous driving, robotics, and power grid management. However, existing robust CRL approaches predominantly focus on single-step perturbations and temporally independent adversarial models, lacking explicit modeling of robustness against temporally coupled perturbations. To tackle these challenges, we propose TCRL, a novel temporal-coupled adversarial training framework for robust constrained reinforcement learning (TCRL) in worst-case scenarios. First, TCRL introduces a worst-case-perceived cost constraint function that estimates safety costs under temporally coupled perturbations without the need to explicitly model adversarial attackers. Second, TCRL establishes a dual-constraint defense mechanism on the reward to counter temporally coupled adversaries while maintaining reward unpredictability. Experimental results demonstrate that TCRL consistently outperforms existing methods in terms of robustness against temporally coupled perturbation attacks across a variety of CRL tasks.
CLEAR: A Knowledge-Centric Vessel Trajectory Analysis Platform
Feb 09, 2026Vessel trajectory data from the Automatic Identification System (AIS) is used widely in maritime analytics. Yet, analysis is difficult for non-expert users due to the incompleteness and complexity of AIS data. We present CLEAR, a knowledge-centric vessel trajectory analysis platform that aims to overcome these barriers. By leveraging the reasoning and generative capabilities of Large Language Models (LLMs), CLEAR transforms raw AIS data into complete, interpretable, and easily explorable vessel trajectories through a Structured Data-derived Knowledge Graph (SD-KG). As part of the demo, participants can configure parameters to automatically download and process AIS data, observe how trajectories are completed and annotated, inspect both raw and imputed segments together with their SD-KG evidence, and interactively explore the SD-KG through a dedicated graph viewer, gaining an intuitive and transparent understanding of vessel movements.
VISTA: Knowledge-Driven Interpretable Vessel Trajectory Imputation via Large Language Models
Jan 11, 2026The Automatic Identification System provides critical information for maritime navigation and safety, yet its trajectories are often incomplete due to signal loss or deliberate tampering. Existing imputation methods emphasize trajectory recovery, paying limited attention to interpretability and failing to provide underlying knowledge that benefits downstream tasks such as anomaly detection and route planning. We propose knowledge-driven interpretable vessel trajectory imputation (VISTA), the first trajectory imputation framework that offers interpretability while simultaneously providing underlying knowledge to support downstream analysis. Specifically, we first define underlying knowledge as a combination of Structured Data-derived Knowledge (SDK) distilled from AIS data and Implicit LLM Knowledge acquired from large-scale Internet corpora. Second, to manage and leverage the SDK effectively at scale, we develop a data-knowledge-data loop that employs a Structured Data-derived Knowledge Graph for SDK extraction and knowledge-driven trajectory imputation. Third, to efficiently process large-scale AIS data, we introduce a workflow management layer that coordinates the end-to-end pipeline, enabling parallel knowledge extraction and trajectory imputation with anomaly handling and redundancy elimination. Experiments on two large AIS datasets show that VISTA is capable of state-of-the-art imputation accuracy and computational efficiency, improving over state-of-the-art baselines by 5%-94% and reducing time cost by 51%-93%, while producing interpretable knowledge cues that benefit downstream tasks. The source code and implementation details of VISTA are publicly available.
Moon: A Modality Conversion-based Efficient Multivariate Time Series Anomaly Detection
Oct 02, 2025Multivariate time series (MTS) anomaly detection identifies abnormal patterns where each timestamp contains multiple variables. Existing MTS anomaly detection methods fall into three categories: reconstruction-based, prediction-based, and classifier-based methods. However, these methods face two key challenges: (1) Unsupervised learning methods, such as reconstruction-based and prediction-based methods, rely on error thresholds, which can lead to inaccuracies; (2) Semi-supervised methods mainly model normal data and often underuse anomaly labels, limiting detection of subtle anomalies;(3) Supervised learning methods, such as classifier-based approaches, often fail to capture local relationships, incur high computational costs, and are constrained by the scarcity of labeled data. To address these limitations, we propose Moon, a supervised modality conversion-based multivariate time series anomaly detection framework. Moon enhances the efficiency and accuracy of anomaly detection while providing detailed anomaly analysis reports. First, Moon introduces a novel multivariate Markov Transition Field (MV-MTF) technique to convert numeric time series data into image representations, capturing relationships across variables and timestamps. Since numeric data retains unique patterns that cannot be fully captured by image conversion alone, Moon employs a Multimodal-CNN to integrate numeric and image data through a feature fusion model with parameter sharing, enhancing training efficiency. Finally, a SHAP-based anomaly explainer identifies key variables contributing to anomalies, improving interpretability. Extensive experiments on six real-world MTS datasets demonstrate that Moon outperforms six state-of-the-art methods by up to 93% in efficiency, 4% in accuracy and, 10.8% in interpretation performance.
Advancing Knowledge Tracing by Exploring Follow-up Performance Trends
Aug 11, 2025


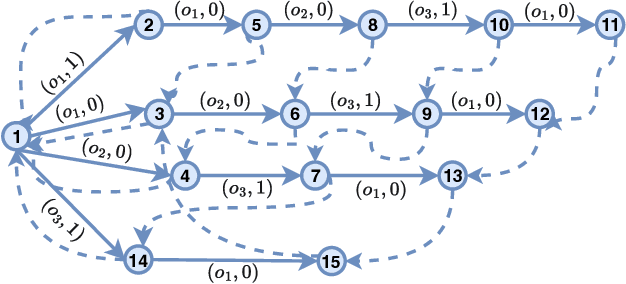
Intelligent Tutoring Systems (ITS), such as Massive Open Online Courses, offer new opportunities for human learning. At the core of such systems, knowledge tracing (KT) predicts students' future performance by analyzing their historical learning activities, enabling an accurate evaluation of students' knowledge states over time. We show that existing KT methods often encounter correlation conflicts when analyzing the relationships between historical learning sequences and future performance. To address such conflicts, we propose to extract so-called Follow-up Performance Trends (FPTs) from historical ITS data and to incorporate them into KT. We propose a method called Forward-Looking Knowledge Tracing (FINER) that combines historical learning sequences with FPTs to enhance student performance prediction accuracy. FINER constructs learning patterns that facilitate the retrieval of FPTs from historical ITS data in linear time; FINER includes a novel similarity-aware attention mechanism that aggregates FPTs based on both frequency and contextual similarity; and FINER offers means of combining FPTs and historical learning sequences to enable more accurate prediction of student future performance. Experiments on six real-world datasets show that FINER can outperform ten state-of-the-art KT methods, increasing accuracy by 8.74% to 84.85%.
MH-GIN: Multi-scale Heterogeneous Graph-based Imputation Network for AIS Data (Extended Version)
Jul 27, 2025Location-tracking data from the Automatic Identification System, much of which is publicly available, plays a key role in a range of maritime safety and monitoring applications. However, the data suffers from missing values that hamper downstream applications. Imputing the missing values is challenging because the values of different heterogeneous attributes are updated at diverse rates, resulting in the occurrence of multi-scale dependencies among attributes. Existing imputation methods that assume similar update rates across attributes are unable to capture and exploit such dependencies, limiting their imputation accuracy. We propose MH-GIN, a Multi-scale Heterogeneous Graph-based Imputation Network that aims improve imputation accuracy by capturing multi-scale dependencies. Specifically, MH-GIN first extracts multi-scale temporal features for each attribute while preserving their intrinsic heterogeneous characteristics. Then, it constructs a multi-scale heterogeneous graph to explicitly model dependencies between heterogeneous attributes to enable more accurate imputation of missing values through graph propagation. Experimental results on two real-world datasets find that MH-GIN is capable of an average 57% reduction in imputation errors compared to state-of-the-art methods, while maintaining computational efficiency. The source code and implementation details of MH-GIN are publicly available https://github.com/hyLiu1994/MH-GIN.
Exploring the Generalizability of Geomagnetic Navigation: A Deep Reinforcement Learning approach with Policy Distillation
Feb 07, 2025



The advancement in autonomous vehicles has empowered navigation and exploration in unknown environments. Geomagnetic navigation for autonomous vehicles has drawn increasing attention with its independence from GPS or inertial navigation devices. While geomagnetic navigation approaches have been extensively investigated, the generalizability of learned geomagnetic navigation strategies remains unexplored. The performance of a learned strategy can degrade outside of its source domain where the strategy is learned, due to a lack of knowledge about the geomagnetic characteristics in newly entered areas. This paper explores the generalization of learned geomagnetic navigation strategies via deep reinforcement learning (DRL). Particularly, we employ DRL agents to learn multiple teacher models from distributed domains that represent dispersed navigation strategies, and amalgamate the teacher models for generalizability across navigation areas. We design a reward shaping mechanism in training teacher models where we integrate both potential-based and intrinsic-motivated rewards. The designed reward shaping can enhance the exploration efficiency of the DRL agent and improve the representation of the teacher models. Upon the gained teacher models, we employ multi-teacher policy distillation to merge the policies learned by individual teachers, leading to a navigation strategy with generalizability across navigation domains. We conduct numerical simulations, and the results demonstrate an effective transfer of the learned DRL model from a source domain to new navigation areas. Compared to existing evolutionary-based geomagnetic navigation methods, our approach provides superior performance in terms of navigation length, duration, heading deviation, and success rate in cross-domain navigation.
Digital Twin-Empowered Voltage Control for Power Systems
Dec 09, 2024


Emerging digital twin technology has the potential to revolutionize voltage control in power systems. However, the state-of-the-art digital twin method suffers from low computational and sampling efficiency, which hinders its applications. To address this issue, we propose a Gumbel-Consistency Digital Twin (GC-DT) method that enhances voltage control with improved computational and sampling efficiency. First, the proposed method incorporates a Gumbel-based strategy improvement that leverages the Gumbel-top trick to enhance non-repetitive sampling actions and reduce the reliance on Monte Carlo Tree Search simulations, thereby improving computational efficiency. Second, a consistency loss function aligns predicted hidden states with actual hidden states in the latent space, which increases both prediction accuracy and sampling efficiency. Experiments on IEEE 123-bus, 34-bus, and 13-bus systems demonstrate that the proposed GC-DT outperforms the state-of-the-art DT method in both computational and sampling efficiency.