 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonUppRoad: A Framework of Formal Modelling, Verifying, Learning, and Visualisation of Autonomous Vehicles
Aug 02, 2024



Combining machine learning and formal methods (FMs) provides a possible solution to overcome the safety issue of autonomous driving (AD) vehicles. However, there are gaps to be bridged before this combination becomes practically applicable and useful. In an attempt to facilitate researchers in both FMs and AD areas, this paper proposes a framework that combines two well-known tools, namely CommonRoad and UPPAAL. On the one hand, CommonRoad can be enhanced by the rigorous semantics of models in UPPAAL, which enables a systematic and comprehensive understanding of the AD system's behaviour and thus strengthens the safety of the system. On the other hand, controllers synthesised by UPPAAL can be visualised by CommonRoad in real-world road networks, which facilitates AD vehicle designers greatly adopting formal models in system design. In this framework, we provide automatic model conversions between CommonRoad and UPPAAL. Therefore, users only need to program in Python and the framework takes care of the formal models, learning, and verification in the backend. We perform experiments to demonstrate the applicability of our framework in various AD scenarios, discuss the advantages of solving motion planning in our framework, and show the scalability limit and possible solutions.
Efficient Shield Synthesis via State-Space Transformation
Jul 29, 2024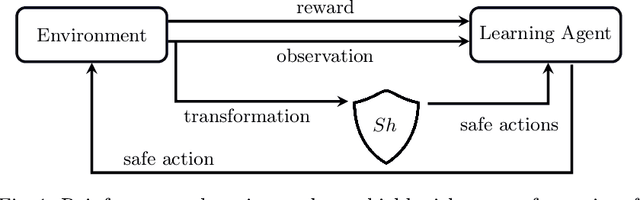
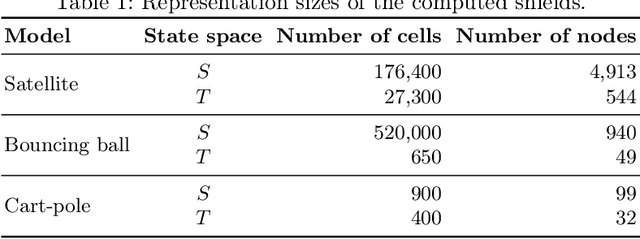
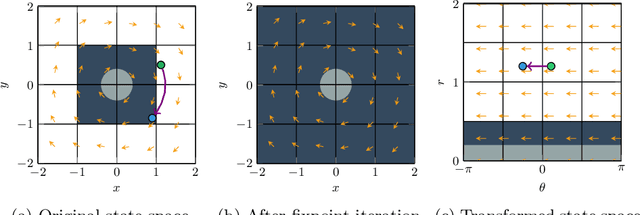

We consider the problem of synthesizing safety strategies for control systems, also known as shields. Since the state space is infinite, shields are typically computed over a finite-state abstraction, with the most common abstraction being a rectangular grid. However, for many systems, such a grid does not align well with the safety property or the system dynamics. That is why a coarse grid is rarely sufficient, but a fine grid is typically computationally infeasible to obtain. In this paper, we show that appropriate state-space transformations can still allow to use a coarse grid at almost no computational overhead. We demonstrate in three case studies that our transformation-based synthesis outperforms a standard synthesis by several orders of magnitude. In the first two case studies, we use domain knowledge to select a suitable transformation. In the third case study, we instead report on results in engineering a transformation without domain knowledge.
A Principled Framework for Evaluating on Typologically Diverse Languages
Jul 06, 2024Beyond individual languages, multilingual natural language processing (NLP) research increasingly aims to develop models that perform well across languages generally. However, evaluating these systems on all the world's languages is practically infeasible. To attain generalizability, representative language sampling is essential. Previous work argues that generalizable multilingual evaluation sets should contain languages with diverse typological properties. However, 'typologically diverse' language samples have been found to vary considerably in this regard, and popular sampling methods are flawed and inconsistent. We present a language sampling framework for selecting highly typologically diverse languages given a sampling frame, informed by language typology. We compare sampling methods with a range of metrics and find that our systematic methods consistently retrieve more typologically diverse language selections than previous methods in NLP. Moreover, we provide evidence that this affects generalizability in multilingual model evaluation, emphasizing the importance of diverse language sampling in NLP evaluation.