 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTypologically Informed Parameter Aggregation
Jan 23, 2026Massively multilingual language models enable cross-lingual generalization but underperform on low-resource and unseen languages. While adapter-based fine-tuning offers a parameter-efficient solution, training language-specific adapters at scale remains costly. We introduce Typologically Informed Parameter Aggregation (TIPA), a training-free method that constructs proxy language adapters by aggregating existing ones, weighted by typological similarity. Integrated into the MAD-X framework, these proxies enable zero-shot cross-lingual transfer without additional training. We evaluate TIPA on five NLP tasks and over 230 languages. TIPA consistently outperforms or matches baselines such as English-only fine-tuning or selecting the typologically closest language adapter. We see the largest gains for languages lacking dedicated adapters. Our results demonstrate that typologically informed aggregation provides a viable alternative to language-specific modules without any training needed.
Form and Meaning in Intrinsic Multilingual Evaluations
Jan 15, 2026Intrinsic evaluation metrics for conditional language models, such as perplexity or bits-per-character, are widely used in both mono- and multilingual settings. These metrics are rather straightforward to use and compare in monolingual setups, but rest on a number of assumptions in multilingual setups. One such assumption is that comparing the perplexity of CLMs on parallel sentences is indicative of their quality since the information content (here understood as the semantic meaning) is the same. However, the metrics are inherently measuring information content in the information-theoretic sense. We make this and other such assumptions explicit and discuss their implications. We perform experiments with six metrics on two multi-parallel corpora both with mono- and multilingual models. Ultimately, we find that current metrics are not universally comparable. We look at the form-meaning debate to provide some explanation for this.
On the Interplay between Positional Encodings, Morphological Complexity, and Word Order Flexibility
Nov 11, 2025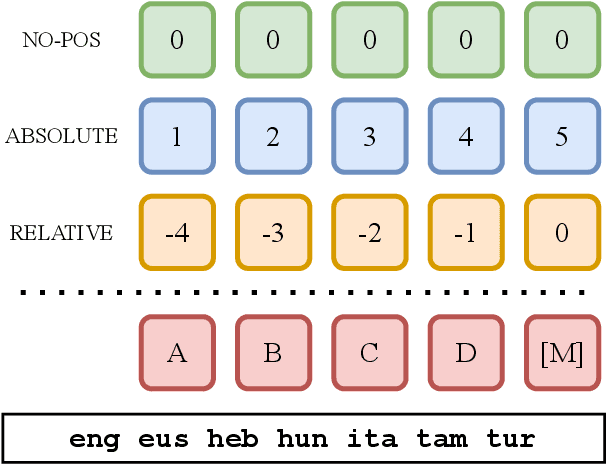
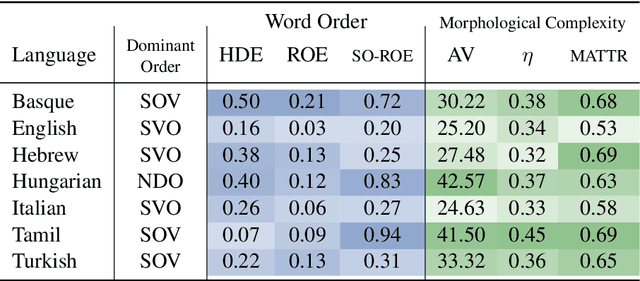

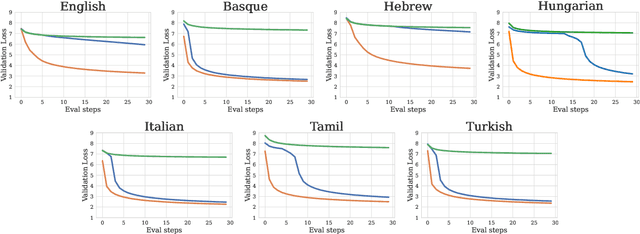
Language model architectures are predominantly first created for English and subsequently applied to other languages. It is an open question whether this architectural bias leads to degraded performance for languages that are structurally different from English. We examine one specific architectural choice: positional encodings, through the lens of the trade-off hypothesis: the supposed interplay between morphological complexity and word order flexibility. This hypothesis posits a trade-off between the two: a more morphologically complex language can have a more flexible word order, and vice-versa. Positional encodings are a direct target to investigate the implications of this hypothesis in relation to language modelling. We pretrain monolingual model variants with absolute, relative, and no positional encodings for seven typologically diverse languages and evaluate them on four downstream tasks. Contrary to previous findings, we do not observe a clear interaction between position encodings and morphological complexity or word order flexibility, as measured by various proxies. Our results show that the choice of tasks, languages, and metrics are essential for drawing stable conclusions
The Roles of English in Evaluating Multilingual Language Models
Dec 11, 2024Multilingual natural language processing is getting increased attention, with numerous models, benchmarks, and methods being released for many languages. English is often used in multilingual evaluation to prompt language models (LMs), mainly to overcome the lack of instruction tuning data in other languages. In this position paper, we lay out two roles of English in multilingual LM evaluations: as an interface and as a natural language. We argue that these roles have different goals: task performance versus language understanding. This discrepancy is highlighted with examples from datasets and evaluation setups. Numerous works explicitly use English as an interface to boost task performance. We recommend to move away from this imprecise method and instead focus on furthering language understanding.
How Good is Your Wikipedia?
Nov 08, 2024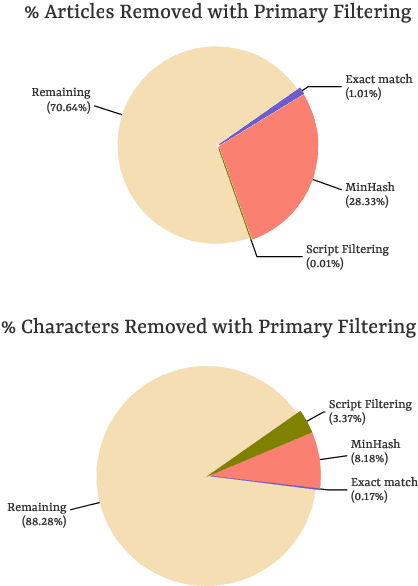

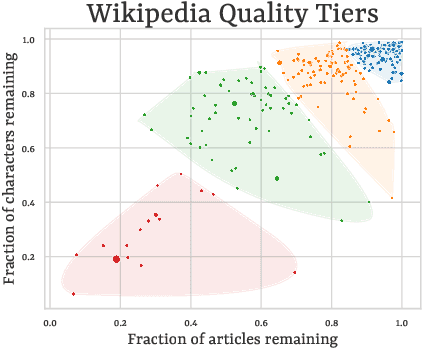
Wikipedia's perceived high quality and broad language coverage have established it as a fundamental resource in multilingual NLP. In the context of low-resource languages, however, these quality assumptions are increasingly being scrutinised. This paper critically examines the data quality of Wikipedia in a non-English setting by subjecting it to various quality filtering techniques, revealing widespread issues such as a high percentage of one-line articles and duplicate articles. We evaluate the downstream impact of quality filtering on Wikipedia and find that data quality pruning is an effective means for resource-efficient training without hurting performance, especially for low-resource languages. Moreover, we advocate for a shift in perspective from seeking a general definition of data quality towards a more language- and task-specific one. Ultimately, we aim for this study to serve as a guide to using Wikipedia for pretraining in a multilingual setting.
A Principled Framework for Evaluating on Typologically Diverse Languages
Jul 06, 2024Beyond individual languages, multilingual natural language processing (NLP) research increasingly aims to develop models that perform well across languages generally. However, evaluating these systems on all the world's languages is practically infeasible. To attain generalizability, representative language sampling is essential. Previous work argues that generalizable multilingual evaluation sets should contain languages with diverse typological properties. However, 'typologically diverse' language samples have been found to vary considerably in this regard, and popular sampling methods are flawed and inconsistent. We present a language sampling framework for selecting highly typologically diverse languages given a sampling frame, informed by language typology. We compare sampling methods with a range of metrics and find that our systematic methods consistently retrieve more typologically diverse language selections than previous methods in NLP. Moreover, we provide evidence that this affects generalizability in multilingual model evaluation, emphasizing the importance of diverse language sampling in NLP evaluation.
Engineering Conversational Search Systems: A Review of Applications, Architectures, and Functional Components
Jul 01, 2024Conversational search systems enable information retrieval via natural language interactions, with the goal of maximizing users' information gain over multiple dialogue turns. The increasing prevalence of conversational interfaces adopting this search paradigm challenges traditional information retrieval approaches, stressing the importance of better understanding the engineering process of developing these systems. We undertook a systematic literature review to investigate the links between theoretical studies and technical implementations of conversational search systems. Our review identifies real-world application scenarios, system architectures, and functional components. We consolidate our results by presenting a layered architecture framework and explaining the core functions of conversational search systems. Furthermore, we reflect on our findings in light of the rapid progress in large language models, discussing their capabilities, limitations, and directions for future research.
What is 'Typological Diversity' in NLP?
Feb 14, 2024



The NLP research community has devoted increased attention to languages beyond English, resulting in considerable improvements for multilingual NLP. However, these improvements only apply to a small subset of the world's languages. Aiming to extend this, an increasing number of papers aspires to enhance generalizable multilingual performance across languages. To this end, linguistic typology is commonly used to motivate language selection, on the basis that a broad typological sample ought to imply generalization across a broad range of languages. These selections are often described as being 'typologically diverse'. In this work, we systematically investigate NLP research that includes claims regarding 'typological diversity'. We find there are no set definitions or criteria for such claims. We introduce metrics to approximate the diversity of language selection along several axes and find that the results vary considerably across papers. Crucially, we show that skewed language selection can lead to overestimated multilingual performance. We recommend future work to include an operationalization of 'typological diversity' that empirically justifies the diversity of language samples.
Detecting ChatGPT: A Survey of the State of Detecting ChatGPT-Generated Text
Sep 14, 2023

While recent advancements in the capabilities and widespread accessibility of generative language models, such as ChatGPT (OpenAI, 2022), have brought about various benefits by generating fluent human-like text, the task of distinguishing between human- and large language model (LLM) generated text has emerged as a crucial problem. These models can potentially deceive by generating artificial text that appears to be human-generated. This issue is particularly significant in domains such as law, education, and science, where ensuring the integrity of text is of the utmost importance. This survey provides an overview of the current approaches employed to differentiate between texts generated by humans and ChatGPT. We present an account of the different datasets constructed for detecting ChatGPT-generated text, the various methods utilized, what qualitative analyses into the characteristics of human versus ChatGPT-generated text have been performed, and finally, summarize our findings into general insights