 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Equivariance Meets Mechanistic Interpretability: Equivariant Sparse Autoencoders
Nov 12, 2025



Sparse autoencoders (SAEs) have proven useful in disentangling the opaque activations of neural networks, primarily large language models, into sets of interpretable features. However, adapting them to domains beyond language, such as scientific data with group symmetries, introduces challenges that can hinder their effectiveness. We show that incorporating such group symmetries into the SAEs yields features more useful in downstream tasks. More specifically, we train autoencoders on synthetic images and find that a single matrix can explain how their activations transform as the images are rotated. Building on this, we develop adaptively equivariant SAEs that can adapt to the base model's level of equivariance. These adaptive SAEs discover features that lead to superior probing performance compared to regular SAEs, demonstrating the value of incorporating symmetries in mechanistic interpretability tools.
Gender Bias in Explainability: Investigating Performance Disparity in Post-hoc Methods
May 02, 2025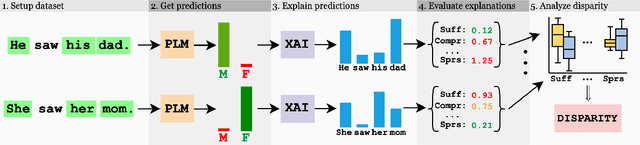


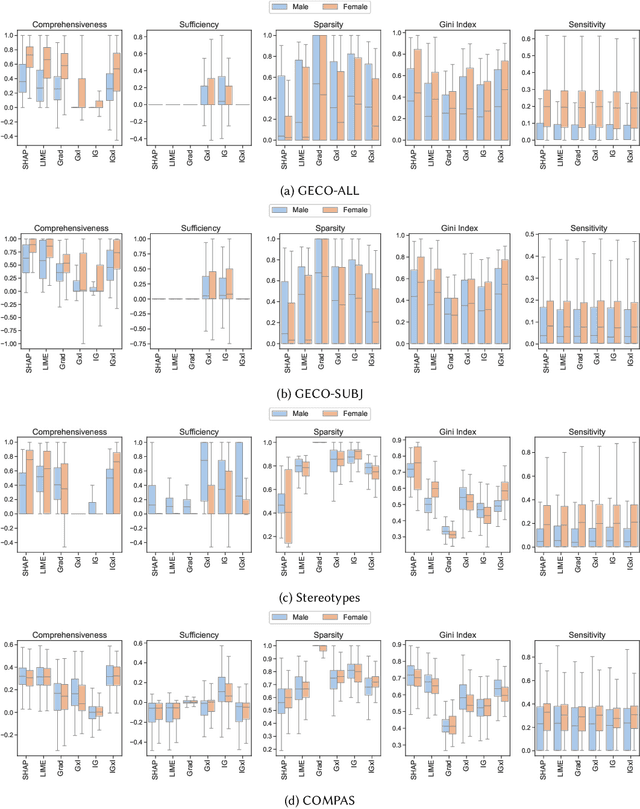
While research on applications and evaluations of explanation methods continues to expand, fairness of the explanation methods concerning disparities in their performance across subgroups remains an often overlooked aspect. In this paper, we address this gap by showing that, across three tasks and five language models, widely used post-hoc feature attribution methods exhibit significant gender disparity with respect to their faithfulness, robustness, and complexity. These disparities persist even when the models are pre-trained or fine-tuned on particularly unbiased datasets, indicating that the disparities we observe are not merely consequences of biased training data. Our results highlight the importance of addressing disparities in explanations when developing and applying explainability methods, as these can lead to biased outcomes against certain subgroups, with particularly critical implications in high-stakes contexts. Furthermore, our findings underscore the importance of incorporating the fairness of explanations, alongside overall model fairness and explainability, as a requirement in regulatory frameworks.
Poisoning $\times$ Evasion: Symbiotic Adversarial Robustness for Graph Neural Networks
Dec 09, 2023

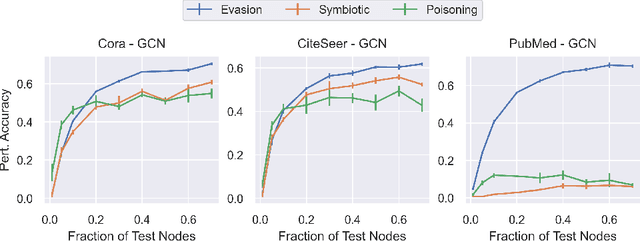

It is well-known that deep learning models are vulnerable to small input perturbations. Such perturbed instances are called adversarial examples. Adversarial examples are commonly crafted to fool a model either at training time (poisoning) or test time (evasion). In this work, we study the symbiosis of poisoning and evasion. We show that combining both threat models can substantially improve the devastating efficacy of adversarial attacks. Specifically, we study the robustness of Graph Neural Networks (GNNs) under structure perturbations and devise a memory-efficient adaptive end-to-end attack for the novel threat model using first-order optimization.
Detecting ChatGPT: A Survey of the State of Detecting ChatGPT-Generated Text
Sep 14, 2023

While recent advancements in the capabilities and widespread accessibility of generative language models, such as ChatGPT (OpenAI, 2022), have brought about various benefits by generating fluent human-like text, the task of distinguishing between human- and large language model (LLM) generated text has emerged as a crucial problem. These models can potentially deceive by generating artificial text that appears to be human-generated. This issue is particularly significant in domains such as law, education, and science, where ensuring the integrity of text is of the utmost importance. This survey provides an overview of the current approaches employed to differentiate between texts generated by humans and ChatGPT. We present an account of the different datasets constructed for detecting ChatGPT-generated text, the various methods utilized, what qualitative analyses into the characteristics of human versus ChatGPT-generated text have been performed, and finally, summarize our findings into general insights
Defense Mechanisms Against Training-Hijacking Attacks in Split Learning
Feb 16, 2023



Distributed deep learning frameworks enable more efficient and privacy-aware training of deep neural networks across multiple clients. Split learning achieves this by splitting a neural network between a client and a server such that the client computes the initial set of layers, and the server computes the rest. However, this method introduces a unique attack vector for a malicious server attempting to recover the client's private inputs: the server can direct the client model towards learning any task of its choice, e.g. towards outputting easily invertible values. With a concrete example already proposed (Pasquini et al., ACM CCS '21), such \textit{training-hijacking} attacks present a significant risk for the data privacy of split learning clients. We propose two methods for a split learning client to detect if it is being targeted by a training-hijacking attack or not. We experimentally evaluate our methods' effectiveness, compare them with other potential solutions, and discuss various points related to their use. Our conclusion is that by using the method that best suits their use case, split learning clients can consistently detect training-hijacking attacks and thus keep the information gained by the attacker at a minimum.
SplitGuard: Detecting and Mitigating Training-Hijacking Attacks in Split Learning
Aug 23, 2021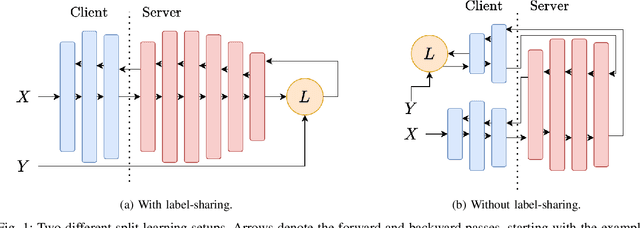
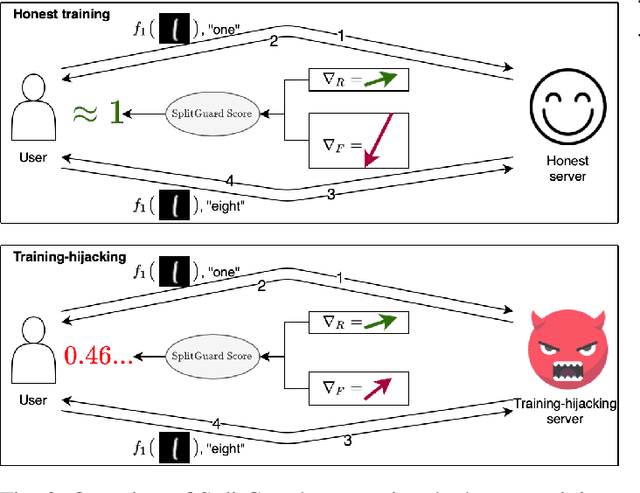
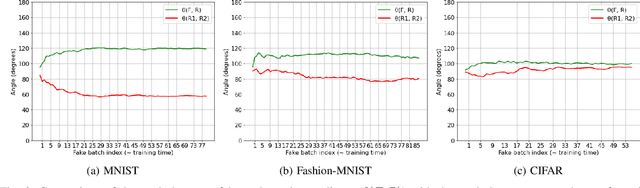
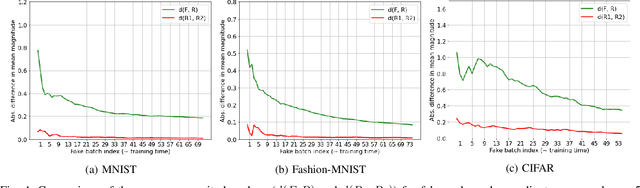
Distributed deep learning frameworks, such as split learning, have recently been proposed to enable a group of participants to collaboratively train a deep neural network without sharing their raw data. Split learning in particular achieves this goal by dividing a neural network between a client and a server so that the client computes the initial set of layers, and the server computes the rest. However, this method introduces a unique attack vector for a malicious server attempting to steal the client's private data: the server can direct the client model towards learning a task of its choice. With a concrete example already proposed, such training-hijacking attacks present a significant risk for the data privacy of split learning clients. In this paper, we propose SplitGuard, a method by which a split learning client can detect whether it is being targeted by a training-hijacking attack or not. We experimentally evaluate its effectiveness, and discuss in detail various points related to its use. We conclude that SplitGuard can effectively detect training-hijacking attacks while minimizing the amount of information recovered by the adversaries.
UnSplit: Data-Oblivious Model Inversion, Model Stealing, and Label Inference Attacks Against Split Learning
Aug 20, 2021
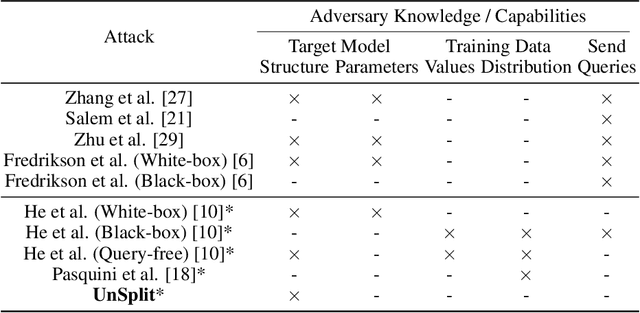
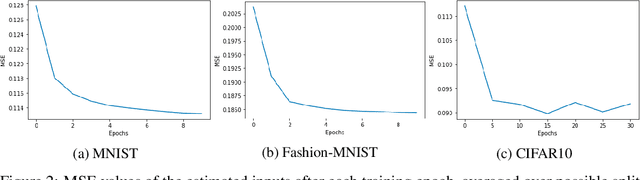
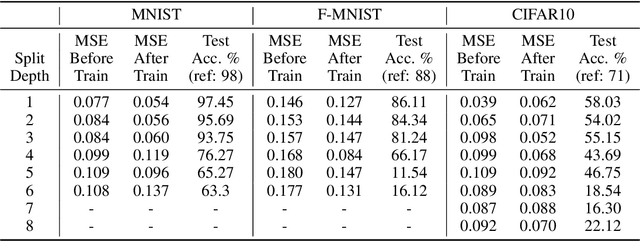
Training deep neural networks requires large scale data, which often forces users to work in a distributed or outsourced setting, accompanied with privacy concerns. Split learning framework aims to address this concern by splitting up the model among the client and the server. The idea is that since the server does not have access to client's part of the model, the scheme supposedly provides privacy. We show that this is not true via two novel attacks. (1) We show that an honest-but-curious split learning server, equipped only with the knowledge of the client neural network architecture, can recover the input samples and also obtain a functionally similar model to the client model, without the client being able to detect the attack. (2) Furthermore, we show that if split learning is used naively to protect the training labels, the honest-but-curious server can infer the labels with perfect accuracy. We test our attacks using three benchmark datasets and investigate various properties of the overall system that affect the attacks' effectiveness. Our results show that plaintext split learning paradigm can pose serious security risks and provide no more than a false sense of security.