 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefense Mechanisms Against Training-Hijacking Attacks in Split Learning
Feb 16, 2023



Distributed deep learning frameworks enable more efficient and privacy-aware training of deep neural networks across multiple clients. Split learning achieves this by splitting a neural network between a client and a server such that the client computes the initial set of layers, and the server computes the rest. However, this method introduces a unique attack vector for a malicious server attempting to recover the client's private inputs: the server can direct the client model towards learning any task of its choice, e.g. towards outputting easily invertible values. With a concrete example already proposed (Pasquini et al., ACM CCS '21), such \textit{training-hijacking} attacks present a significant risk for the data privacy of split learning clients. We propose two methods for a split learning client to detect if it is being targeted by a training-hijacking attack or not. We experimentally evaluate our methods' effectiveness, compare them with other potential solutions, and discuss various points related to their use. Our conclusion is that by using the method that best suits their use case, split learning clients can consistently detect training-hijacking attacks and thus keep the information gained by the attacker at a minimum.
SplitGuard: Detecting and Mitigating Training-Hijacking Attacks in Split Learning
Aug 23, 2021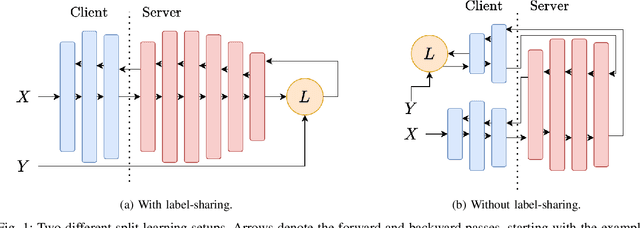
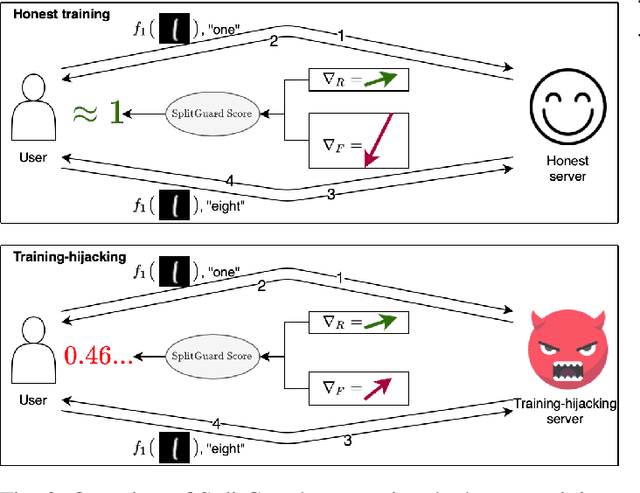
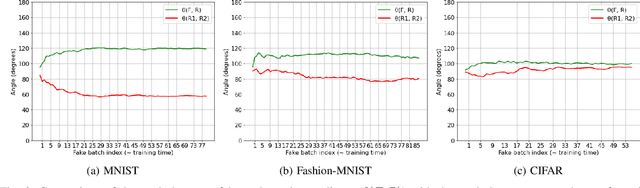
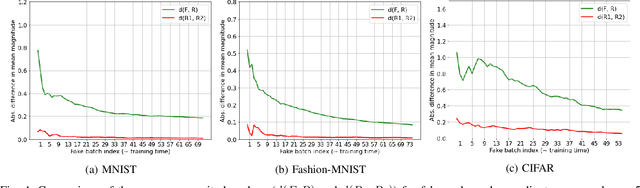
Distributed deep learning frameworks, such as split learning, have recently been proposed to enable a group of participants to collaboratively train a deep neural network without sharing their raw data. Split learning in particular achieves this goal by dividing a neural network between a client and a server so that the client computes the initial set of layers, and the server computes the rest. However, this method introduces a unique attack vector for a malicious server attempting to steal the client's private data: the server can direct the client model towards learning a task of its choice. With a concrete example already proposed, such training-hijacking attacks present a significant risk for the data privacy of split learning clients. In this paper, we propose SplitGuard, a method by which a split learning client can detect whether it is being targeted by a training-hijacking attack or not. We experimentally evaluate its effectiveness, and discuss in detail various points related to its use. We conclude that SplitGuard can effectively detect training-hijacking attacks while minimizing the amount of information recovered by the adversaries.
UnSplit: Data-Oblivious Model Inversion, Model Stealing, and Label Inference Attacks Against Split Learning
Aug 20, 2021
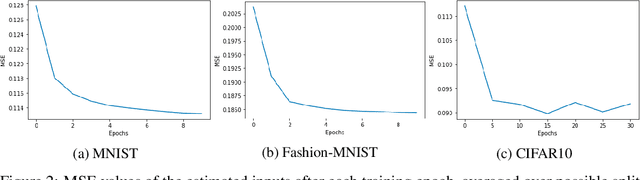
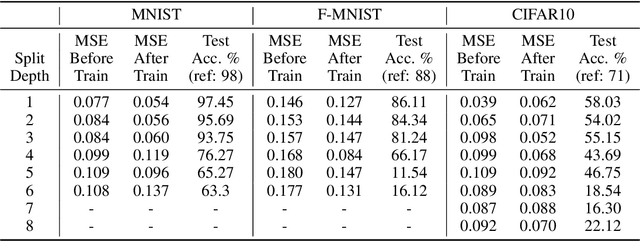
Training deep neural networks requires large scale data, which often forces users to work in a distributed or outsourced setting, accompanied with privacy concerns. Split learning framework aims to address this concern by splitting up the model among the client and the server. The idea is that since the server does not have access to client's part of the model, the scheme supposedly provides privacy. We show that this is not true via two novel attacks. (1) We show that an honest-but-curious split learning server, equipped only with the knowledge of the client neural network architecture, can recover the input samples and also obtain a functionally similar model to the client model, without the client being able to detect the attack. (2) Furthermore, we show that if split learning is used naively to protect the training labels, the honest-but-curious server can infer the labels with perfect accuracy. We test our attacks using three benchmark datasets and investigate various properties of the overall system that affect the attacks' effectiveness. Our results show that plaintext split learning paradigm can pose serious security risks and provide no more than a false sense of security.