 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggressive or Imperceptible, or Both: Network Pruning Assisted Hybrid Byzantines in Federated Learning
Apr 09, 2024
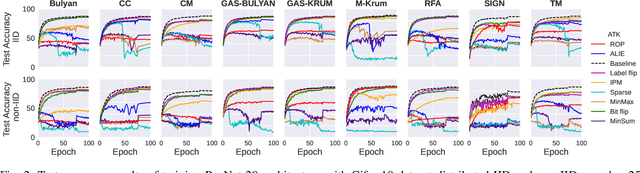
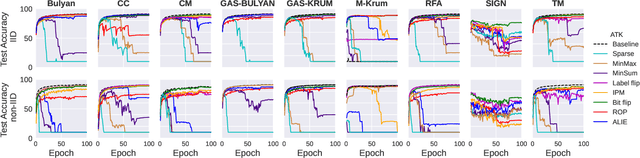
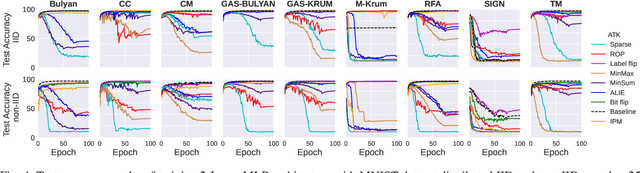
Federated learning (FL) has been introduced to enable a large number of clients, possibly mobile devices, to collaborate on generating a generalized machine learning model thanks to utilizing a larger number of local samples without sharing to offer certain privacy to collaborating clients. However, due to the participation of a large number of clients, it is often difficult to profile and verify each client, which leads to a security threat that malicious participants may hamper the accuracy of the trained model by conveying poisoned models during the training. Hence, the aggregation framework at the parameter server also needs to minimize the detrimental effects of these malicious clients. A plethora of attack and defence strategies have been analyzed in the literature. However, often the Byzantine problem is analyzed solely from the outlier detection perspective, being oblivious to the topology of neural networks (NNs). In the scope of this work, we argue that by extracting certain side information specific to the NN topology, one can design stronger attacks. Hence, inspired by the sparse neural networks, we introduce a hybrid sparse Byzantine attack that is composed of two parts: one exhibiting a sparse nature and attacking only certain NN locations with higher sensitivity, and the other being more silent but accumulating over time, where each ideally targets a different type of defence mechanism, and together they form a strong but imperceptible attack. Finally, we show through extensive simulations that the proposed hybrid Byzantine attack is effective against 8 different defence methods.
Defense Mechanisms Against Training-Hijacking Attacks in Split Learning
Feb 16, 2023



Distributed deep learning frameworks enable more efficient and privacy-aware training of deep neural networks across multiple clients. Split learning achieves this by splitting a neural network between a client and a server such that the client computes the initial set of layers, and the server computes the rest. However, this method introduces a unique attack vector for a malicious server attempting to recover the client's private inputs: the server can direct the client model towards learning any task of its choice, e.g. towards outputting easily invertible values. With a concrete example already proposed (Pasquini et al., ACM CCS '21), such \textit{training-hijacking} attacks present a significant risk for the data privacy of split learning clients. We propose two methods for a split learning client to detect if it is being targeted by a training-hijacking attack or not. We experimentally evaluate our methods' effectiveness, compare them with other potential solutions, and discuss various points related to their use. Our conclusion is that by using the method that best suits their use case, split learning clients can consistently detect training-hijacking attacks and thus keep the information gained by the attacker at a minimum.
Byzantines can also Learn from History: Fall of Centered Clipping in Federated Learning
Aug 21, 2022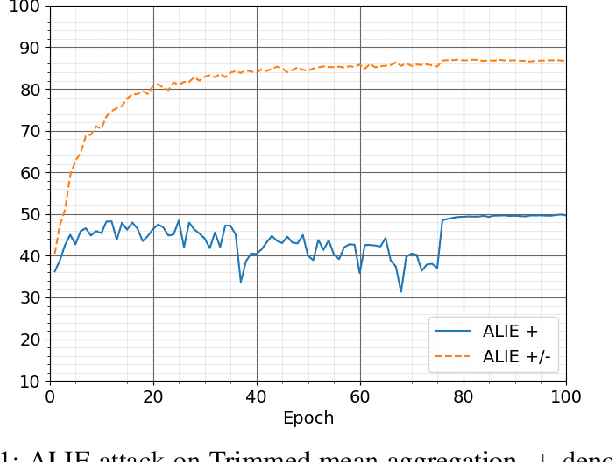
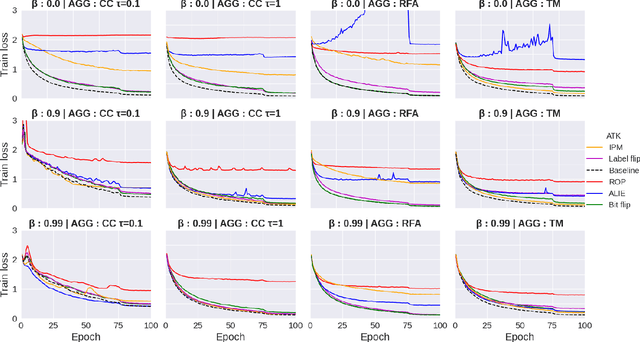
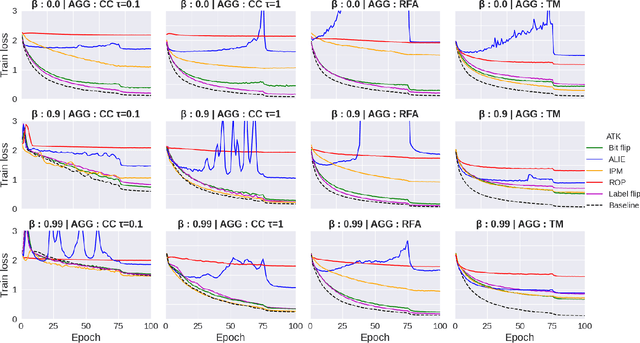
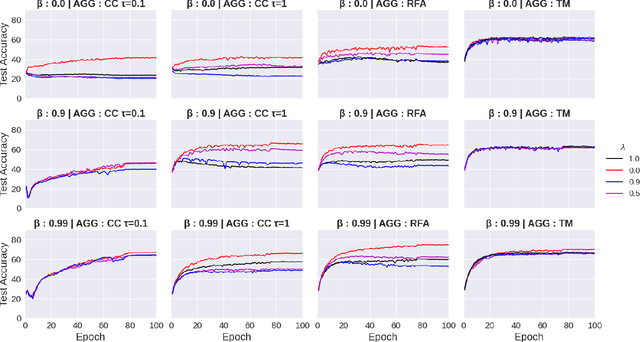
The increasing popularity of the federated learning framework due to its success in a wide range of collaborative learning tasks also induces certain security concerns regarding the learned model due to the possibility of malicious clients participating in the learning process. Hence, the objective is to neutralize the impact of the malicious participants and to ensure the final model is trustable. One common observation regarding the Byzantine attacks is that the higher the variance among the clients' models/updates, the more space for attacks to be hidden. To this end, it has been recently shown that by utilizing momentum, thus reducing the variance, it is possible to weaken the strength of the known Byzantine attacks. The Centered Clipping framework (ICML 2021) has further shown that, besides reducing the variance, the momentum term from the previous iteration can be used as a reference point to neutralize the Byzantine attacks and show impressive performance against well-known attacks. However, in the scope of this work, we show that the centered clipping framework has certain vulnerabilities, and existing attacks can be revised based on these vulnerabilities to circumvent the centered clipping defense. Hence, we introduce a strategy to design an attack to circumvent the centered clipping framework and numerically illustrate its effectiveness against centered clipping as well as other known defense strategies by reducing test accuracy to 5-40 on best-case scenarios.
SplitGuard: Detecting and Mitigating Training-Hijacking Attacks in Split Learning
Aug 23, 2021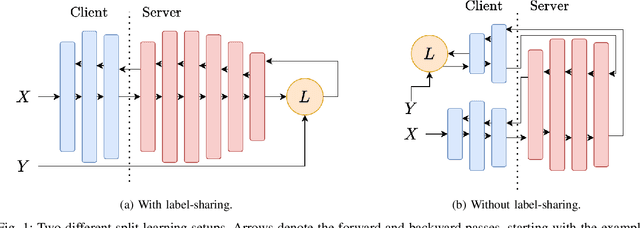
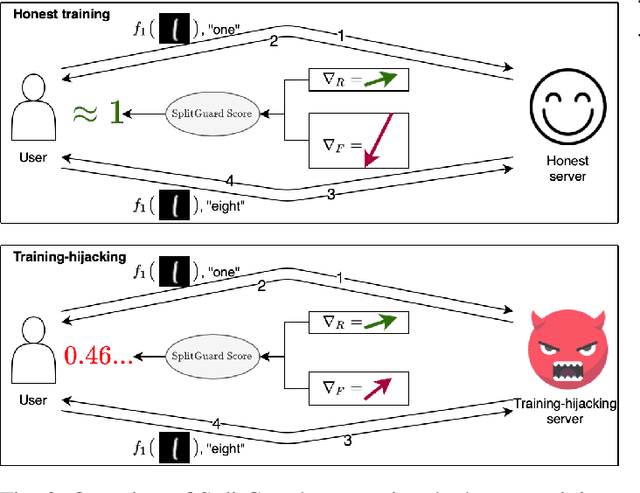
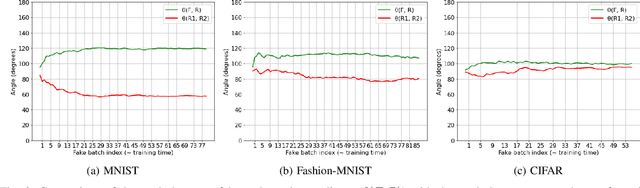
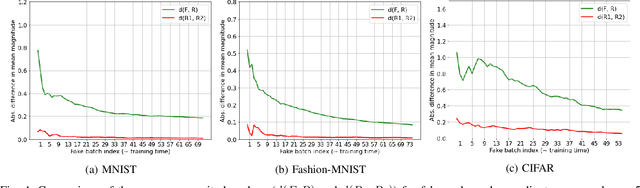
Distributed deep learning frameworks, such as split learning, have recently been proposed to enable a group of participants to collaboratively train a deep neural network without sharing their raw data. Split learning in particular achieves this goal by dividing a neural network between a client and a server so that the client computes the initial set of layers, and the server computes the rest. However, this method introduces a unique attack vector for a malicious server attempting to steal the client's private data: the server can direct the client model towards learning a task of its choice. With a concrete example already proposed, such training-hijacking attacks present a significant risk for the data privacy of split learning clients. In this paper, we propose SplitGuard, a method by which a split learning client can detect whether it is being targeted by a training-hijacking attack or not. We experimentally evaluate its effectiveness, and discuss in detail various points related to its use. We conclude that SplitGuard can effectively detect training-hijacking attacks while minimizing the amount of information recovered by the adversaries.
UnSplit: Data-Oblivious Model Inversion, Model Stealing, and Label Inference Attacks Against Split Learning
Aug 20, 2021
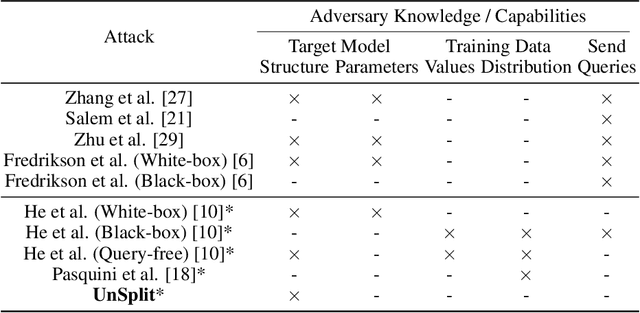
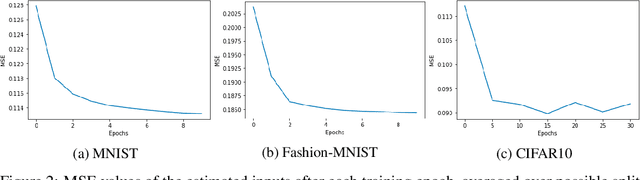
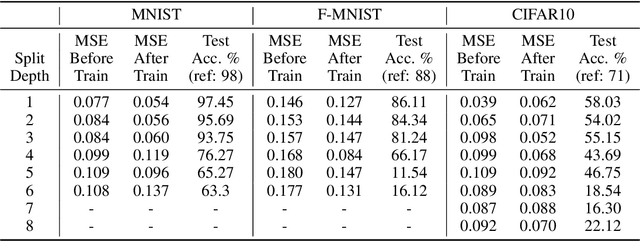
Training deep neural networks requires large scale data, which often forces users to work in a distributed or outsourced setting, accompanied with privacy concerns. Split learning framework aims to address this concern by splitting up the model among the client and the server. The idea is that since the server does not have access to client's part of the model, the scheme supposedly provides privacy. We show that this is not true via two novel attacks. (1) We show that an honest-but-curious split learning server, equipped only with the knowledge of the client neural network architecture, can recover the input samples and also obtain a functionally similar model to the client model, without the client being able to detect the attack. (2) Furthermore, we show that if split learning is used naively to protect the training labels, the honest-but-curious server can infer the labels with perfect accuracy. We test our attacks using three benchmark datasets and investigate various properties of the overall system that affect the attacks' effectiveness. Our results show that plaintext split learning paradigm can pose serious security risks and provide no more than a false sense of security.