 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByzantines can also Learn from History: Fall of Centered Clipping in Federated Learning
Paper and Code
Aug 21, 2022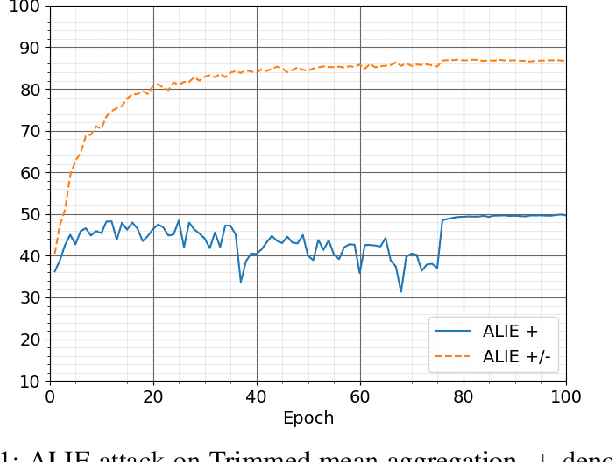
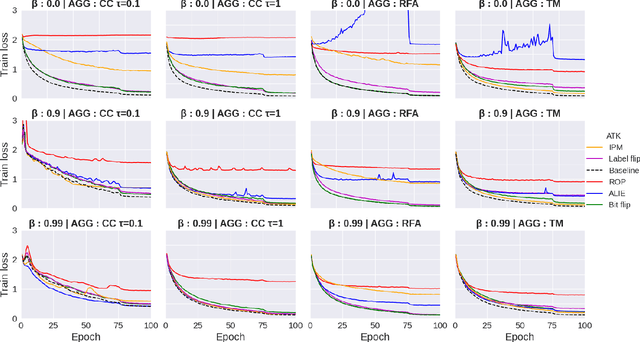
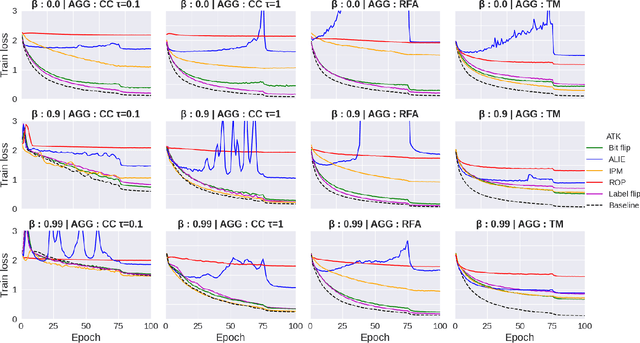
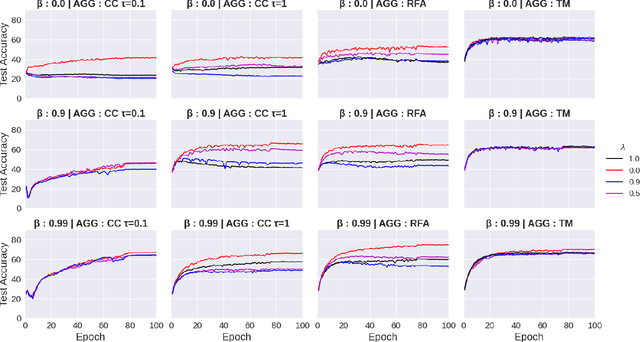
The increasing popularity of the federated learning framework due to its success in a wide range of collaborative learning tasks also induces certain security concerns regarding the learned model due to the possibility of malicious clients participating in the learning process. Hence, the objective is to neutralize the impact of the malicious participants and to ensure the final model is trustable. One common observation regarding the Byzantine attacks is that the higher the variance among the clients' models/updates, the more space for attacks to be hidden. To this end, it has been recently shown that by utilizing momentum, thus reducing the variance, it is possible to weaken the strength of the known Byzantine attacks. The Centered Clipping framework (ICML 2021) has further shown that, besides reducing the variance, the momentum term from the previous iteration can be used as a reference point to neutralize the Byzantine attacks and show impressive performance against well-known attacks. However, in the scope of this work, we show that the centered clipping framework has certain vulnerabilities, and existing attacks can be revised based on these vulnerabilities to circumvent the centered clipping defense. Hence, we introduce a strategy to design an attack to circumvent the centered clipping framework and numerically illustrate its effectiveness against centered clipping as well as other known defense strategies by reducing test accuracy to 5-40 on best-case scenarios.