 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggressive or Imperceptible, or Both: Network Pruning Assisted Hybrid Byzantines in Federated Learning
Apr 09, 2024
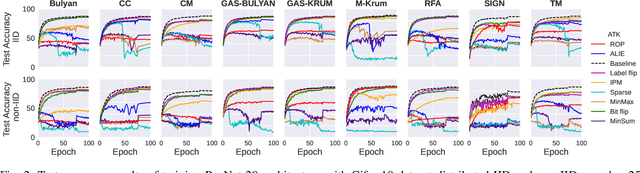
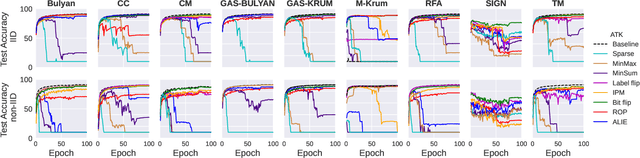
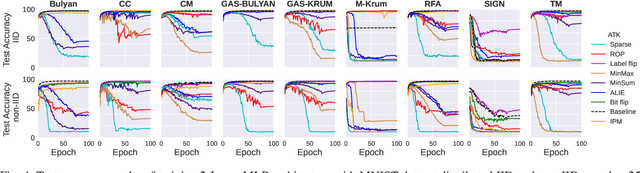
Federated learning (FL) has been introduced to enable a large number of clients, possibly mobile devices, to collaborate on generating a generalized machine learning model thanks to utilizing a larger number of local samples without sharing to offer certain privacy to collaborating clients. However, due to the participation of a large number of clients, it is often difficult to profile and verify each client, which leads to a security threat that malicious participants may hamper the accuracy of the trained model by conveying poisoned models during the training. Hence, the aggregation framework at the parameter server also needs to minimize the detrimental effects of these malicious clients. A plethora of attack and defence strategies have been analyzed in the literature. However, often the Byzantine problem is analyzed solely from the outlier detection perspective, being oblivious to the topology of neural networks (NNs). In the scope of this work, we argue that by extracting certain side information specific to the NN topology, one can design stronger attacks. Hence, inspired by the sparse neural networks, we introduce a hybrid sparse Byzantine attack that is composed of two parts: one exhibiting a sparse nature and attacking only certain NN locations with higher sensitivity, and the other being more silent but accumulating over time, where each ideally targets a different type of defence mechanism, and together they form a strong but imperceptible attack. Finally, we show through extensive simulations that the proposed hybrid Byzantine attack is effective against 8 different defence methods.
Process-and-Forward: Deep Joint Source-Channel Coding Over Cooperative Relay Networks
Mar 15, 2024



This paper introduces an innovative deep joint source-channel coding (DeepJSCC) approach to image transmission over a cooperative relay channel. The relay either amplifies and forwards a scaled version of its received signal, referred to as DeepJSCC-AF, or leverages neural networks to extract relevant features about the source signal before forwarding it to the destination, which we call DeepJSCC-PF (Process-and-Forward). In the full-duplex scheme, inspired by the block Markov coding (BMC) concept, we introduce a novel block transmission strategy built upon novel vision transformer architecture. In the proposed scheme, the source transmits information in blocks, and the relay updates its knowledge about the input signal after each block and generates its own signal to be conveyed to the destination. To enhance practicality, we introduce an adaptive transmission model, which allows a single trained DeepJSCC model to adapt seamlessly to various channel qualities, making it a versatile solution. Simulation results demonstrate the superior performance of our proposed DeepJSCC compared to the state-of-the-art BPG image compression algorithm, even when operating at the maximum achievable rate of conventional decode-and-forward and compress-and-forward protocols, for both half-duplex and full-duplex relay scenarios.
Transformer-aided Wireless Image Transmission with Channel Feedback
Jun 15, 2023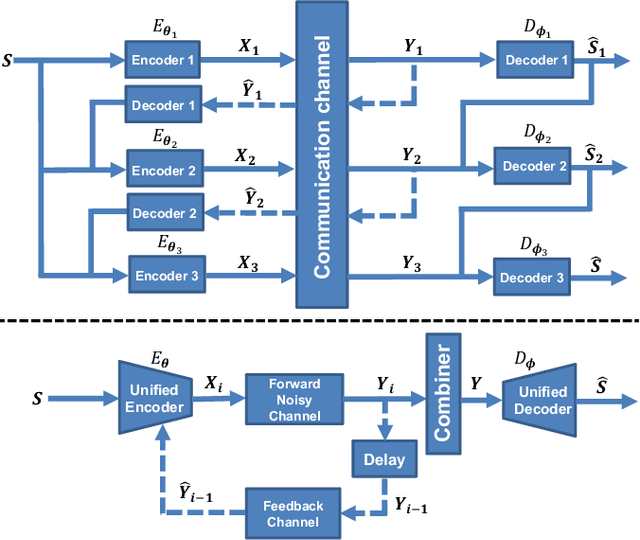



This paper presents a novel wireless image transmission paradigm that can exploit feedback from the receiver, called DeepJSCC-ViT-f. We consider a block feedback channel model, where the transmitter receives noiseless/noisy channel output feedback after each block. The proposed scheme employs a single encoder to facilitate transmission over multiple blocks, refining the receiver's estimation at each block. Specifically, the unified encoder of DeepJSCC-ViT-f can leverage the semantic information from the source image, and acquire channel state information and the decoder's current belief about the source image from the feedback signal to generate coded symbols at each block. Numerical experiments show that our DeepJSCC-ViT-f scheme achieves state-of-the-art transmission performance with robustness to noise in the feedback link. Additionally, DeepJSCC-ViT-f can adapt to the channel condition directly through feedback without the need for separate channel estimation. We further extend the scope of the DeepJSCC-ViT-f approach to include the broadcast channel, which enables the transmitter to generate broadcast codes in accordance with signal semantics and channel feedback from individual receivers.
Do not Interfere but Cooperate: A Fully Learnable Code Design for Multi-Access Channels with Feedback
Jun 01, 2023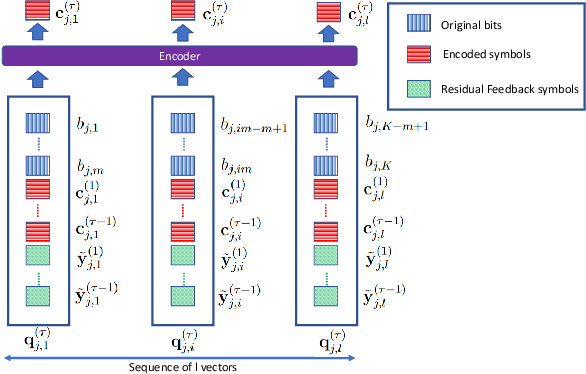
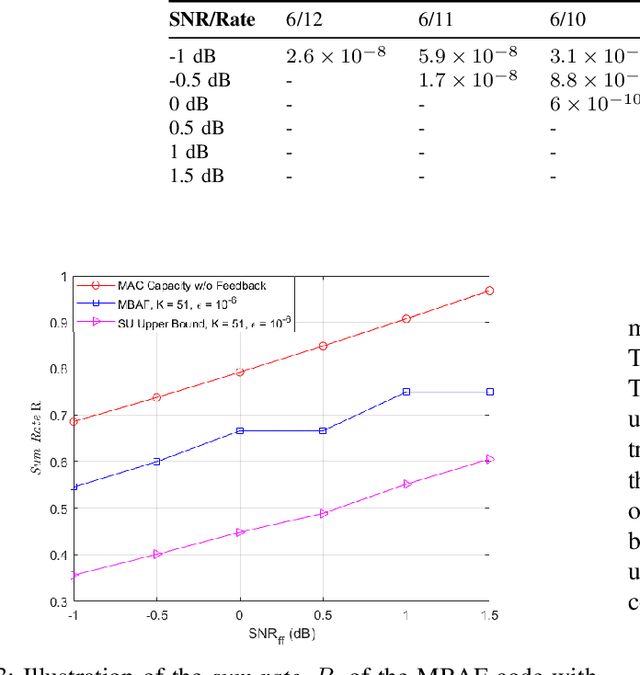

Data-driven deep learning based code designs, including low-complexity neural decoders for existing codes, or end-to-end trainable auto-encoders have exhibited impressive results, particularly in scenarios for which we do not have high-performing structured code designs. However, the vast majority of existing data-driven solutions for channel coding focus on a point-to-point scenario. In this work, we consider a multiple access channel (MAC) with feedback and try to understand whether deep learning-based designs are capable of enabling coordination and cooperation among the encoders as well as allowing error correction. Simulation results show that the proposed multi-access block attention feedback (MBAF) code improves the upper bound of the achievable rate of MAC without feedback in finite block length regime.
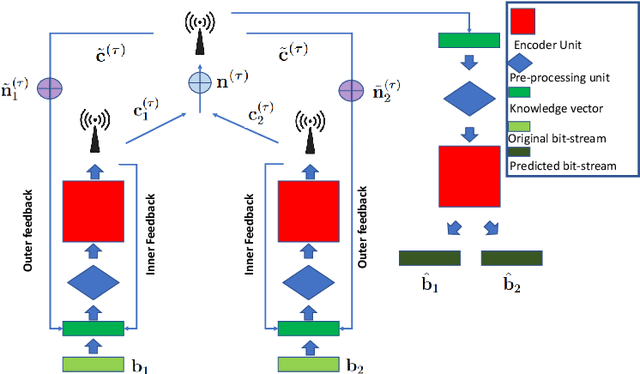
Feedback is Good, Active Feedback is Better: Block Attention Active Feedback Codes
Nov 03, 2022


Deep neural network (DNN)-assisted channel coding designs, such as low-complexity neural decoders for existing codes, or end-to-end neural-network-based auto-encoder designs are gaining interest recently due to their improved performance and flexibility; particularly for communication scenarios in which high-performing structured code designs do not exist. Communication in the presence of feedback is one such communication scenario, and practical code design for feedback channels has remained an open challenge in coding theory for many decades. Recently, DNN-based designs have shown impressive results in exploiting feedback. In particular, generalized block attention feedback (GBAF) codes, which utilizes the popular transformer architecture, achieved significant improvement in terms of the block error rate (BLER) performance. However, previous works have focused mainly on passive feedback, where the transmitter observes a noisy version of the signal at the receiver. In this work, we show that GBAF codes can also be used for channels with active feedback. We implement a pair of transformer architectures, at the transmitter and the receiver, which interact with each other sequentially, and achieve a new state-of-the-art BLER performance, especially in the low SNR regime.
Byzantines can also Learn from History: Fall of Centered Clipping in Federated Learning
Aug 21, 2022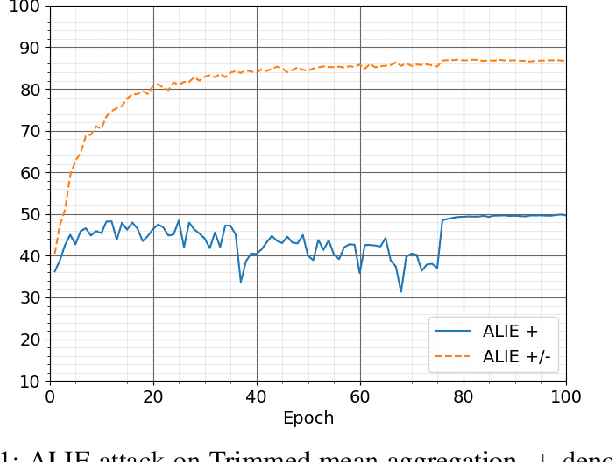
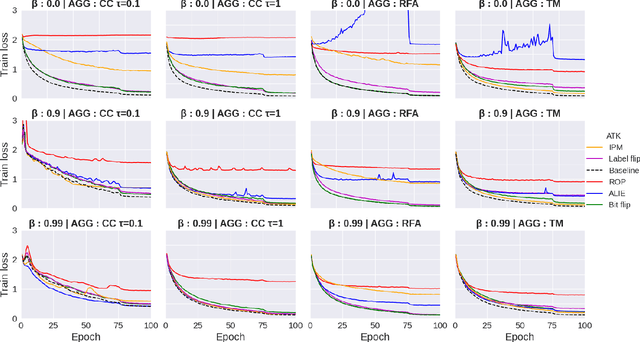
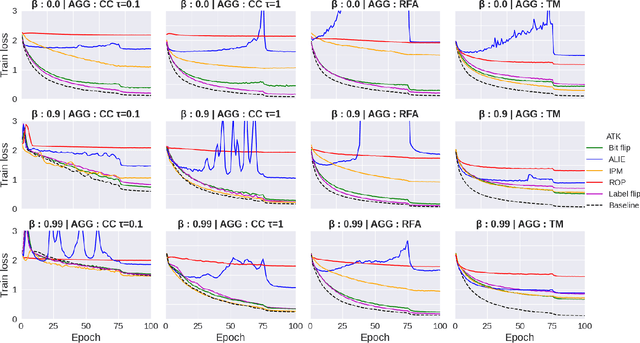
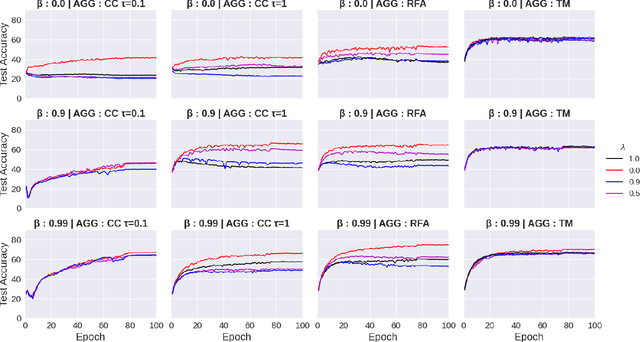
The increasing popularity of the federated learning framework due to its success in a wide range of collaborative learning tasks also induces certain security concerns regarding the learned model due to the possibility of malicious clients participating in the learning process. Hence, the objective is to neutralize the impact of the malicious participants and to ensure the final model is trustable. One common observation regarding the Byzantine attacks is that the higher the variance among the clients' models/updates, the more space for attacks to be hidden. To this end, it has been recently shown that by utilizing momentum, thus reducing the variance, it is possible to weaken the strength of the known Byzantine attacks. The Centered Clipping framework (ICML 2021) has further shown that, besides reducing the variance, the momentum term from the previous iteration can be used as a reference point to neutralize the Byzantine attacks and show impressive performance against well-known attacks. However, in the scope of this work, we show that the centered clipping framework has certain vulnerabilities, and existing attacks can be revised based on these vulnerabilities to circumvent the centered clipping defense. Hence, we introduce a strategy to design an attack to circumvent the centered clipping framework and numerically illustrate its effectiveness against centered clipping as well as other known defense strategies by reducing test accuracy to 5-40 on best-case scenarios.
All you need is feedback: Communication with block attention feedback codes
Jun 19, 2022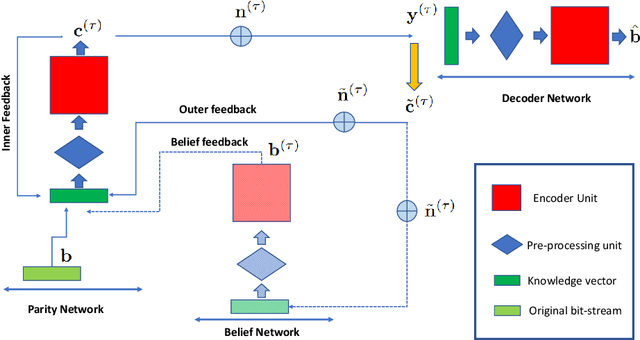
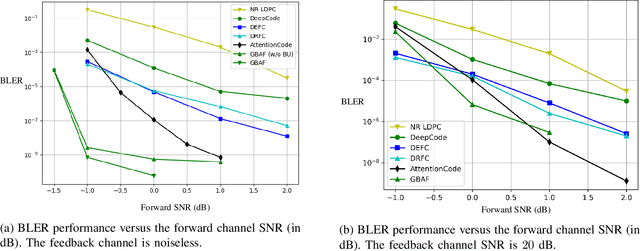


Deep learning based channel code designs have recently gained interest as an alternative to conventional coding algorithms, particularly for channels for which existing codes do not provide effective solutions. Communication over a feedback channel is one such problem, for which promising results have recently been obtained by employing various deep learning architectures. In this paper, we introduce a novel learning-aided code design for feedback channels, called generalized block attention feedback (GBAF) codes, which i) employs a modular architecture that can be implemented using different neural network architectures; ii) provides order-of-magnitude improvements in the probability of error compared to existing designs; and iii) can transmit at desired code rates.
AttentionCode: Ultra-Reliable Feedback Codes for Short-Packet Communications
May 30, 2022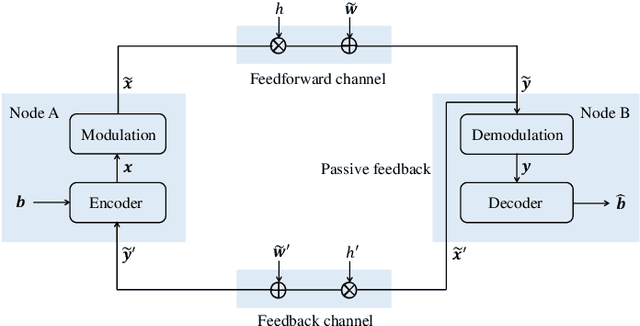


Ultra-reliable short-packet communication is a major challenge in future wireless networks with critical applications. To achieve ultra-reliable communications beyond 99.999%, this paper envisions a new interaction-based communication paradigm that exploits the feedback from the receiver for the sixth generation (6G) communication networks and beyond. We present AttentionCode, a new class of feedback codes leveraging deep learning (DL) technologies. The underpinnings of AttentionCode are three architectural innovations: AttentionNet, input restructuring, and adaptation to fading channels, accompanied by several training methods, including large-batch training, distributed learning, look-ahead optimizer, training-test signal-to-noise ratio (SNR) mismatch, and curriculum learning. The training methods can potentially be generalized to other wireless communication applications with machine learning. Numerical experiments verify that AttentionCode establishes a new state of the art among all DL-based feedback codes in both additive white Gaussian noise (AWGN) channels and fading channels. In AWGN channels with noiseless feedback, for example, AttentionCode achieves a block error rate (BLER) of $10^{-7}$ when the forward channel SNR is 0dB for a block size of 50 bits, demonstrating the potential of AttentionCode to provide ultra-reliable short-packet communications for 6G.
Semi-Decentralized Federated Learning with Collaborative Relaying
May 23, 2022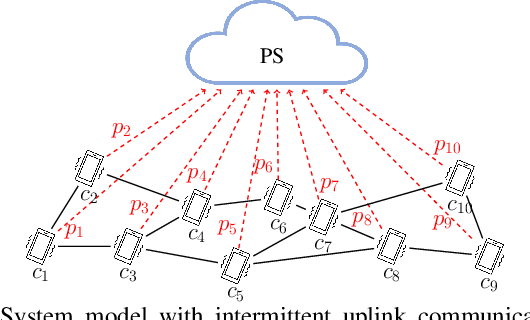
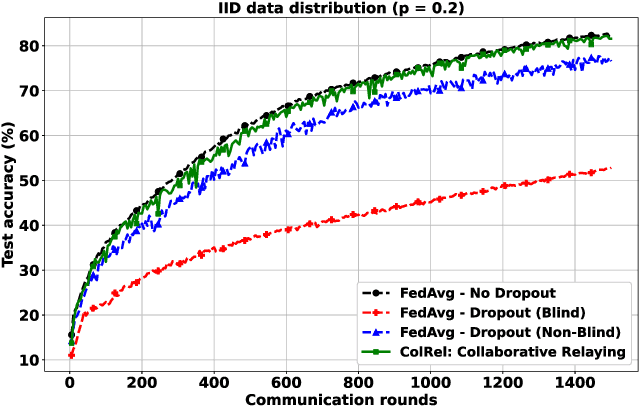
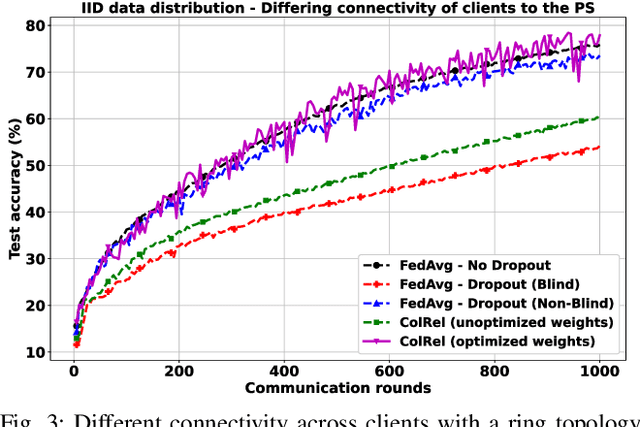
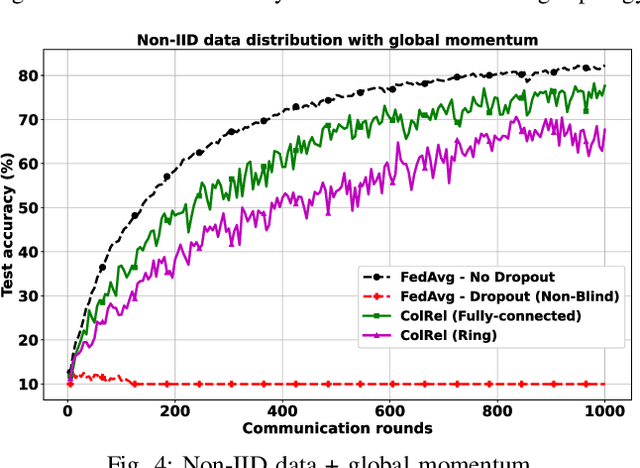
We present a semi-decentralized federated learning algorithm wherein clients collaborate by relaying their neighbors' local updates to a central parameter server (PS). At every communication round to the PS, each client computes a local consensus of the updates from its neighboring clients and eventually transmits a weighted average of its own update and those of its neighbors to the PS. We appropriately optimize these averaging weights to ensure that the global update at the PS is unbiased and to reduce the variance of the global update at the PS, consequently improving the rate of convergence. Numerical simulations substantiate our theoretical claims and demonstrate settings with intermittent connectivity between the clients and the PS, where our proposed algorithm shows an improved convergence rate and accuracy in comparison with the federated averaging algorithm.
Federated Spatial Reuse Optimization in Next-Generation Decentralized IEEE 802.11 WLANs
Mar 20, 2022

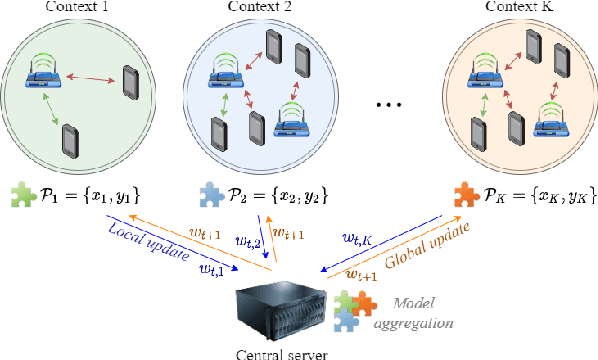
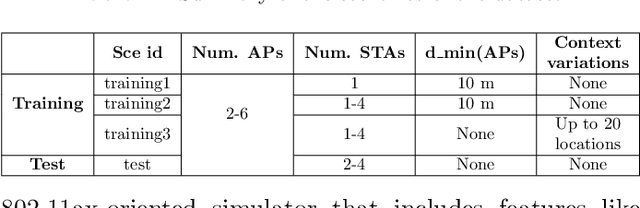
As wireless standards evolve, more complex functionalities are introduced to address the increasing requirements in terms of throughput, latency, security, and efficiency. To unleash the potential of such new features, artificial intelligence (AI) and machine learning (ML) are currently being exploited for deriving models and protocols from data, rather than by hand-programming. In this paper, we explore the feasibility of applying ML in next-generation wireless local area networks (WLANs). More specifically, we focus on the IEEE 802.11ax spatial reuse (SR) problem and predict its performance through federated learning (FL) models. The set of FL solutions overviewed in this work is part of the 2021 International Telecommunication Union (ITU) AI for 5G Challenge.