 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggressive or Imperceptible, or Both: Network Pruning Assisted Hybrid Byzantines in Federated Learning
Apr 09, 2024
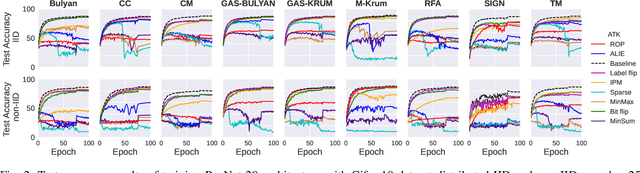
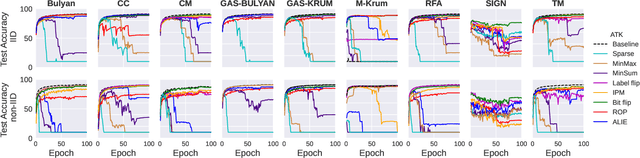
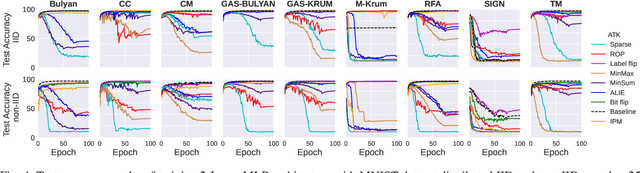
Federated learning (FL) has been introduced to enable a large number of clients, possibly mobile devices, to collaborate on generating a generalized machine learning model thanks to utilizing a larger number of local samples without sharing to offer certain privacy to collaborating clients. However, due to the participation of a large number of clients, it is often difficult to profile and verify each client, which leads to a security threat that malicious participants may hamper the accuracy of the trained model by conveying poisoned models during the training. Hence, the aggregation framework at the parameter server also needs to minimize the detrimental effects of these malicious clients. A plethora of attack and defence strategies have been analyzed in the literature. However, often the Byzantine problem is analyzed solely from the outlier detection perspective, being oblivious to the topology of neural networks (NNs). In the scope of this work, we argue that by extracting certain side information specific to the NN topology, one can design stronger attacks. Hence, inspired by the sparse neural networks, we introduce a hybrid sparse Byzantine attack that is composed of two parts: one exhibiting a sparse nature and attacking only certain NN locations with higher sensitivity, and the other being more silent but accumulating over time, where each ideally targets a different type of defence mechanism, and together they form a strong but imperceptible attack. Finally, we show through extensive simulations that the proposed hybrid Byzantine attack is effective against 8 different defence methods.
Byzantines can also Learn from History: Fall of Centered Clipping in Federated Learning
Aug 21, 2022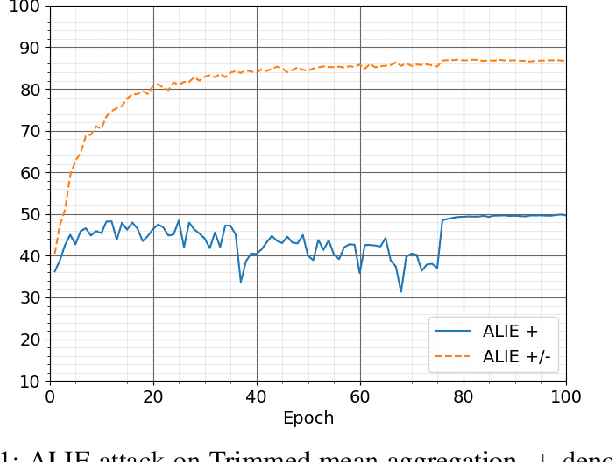
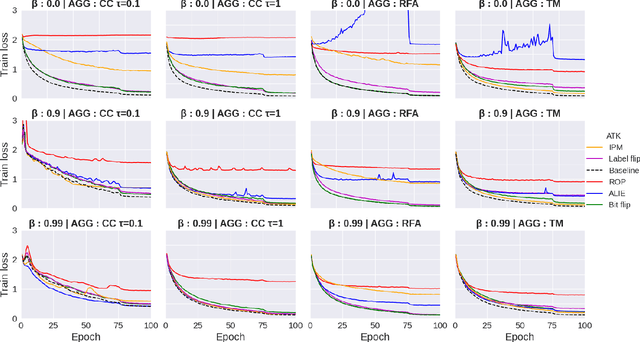
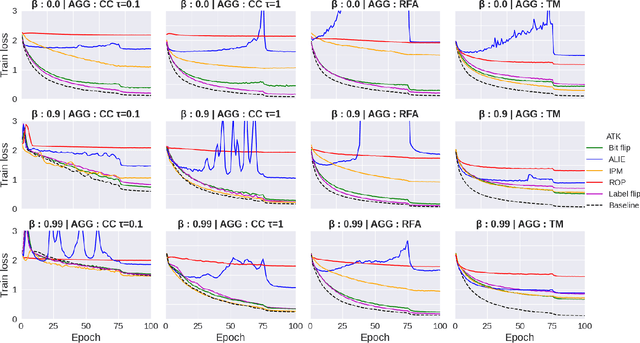
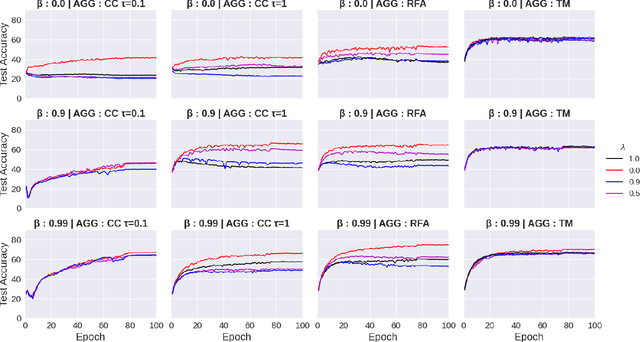
The increasing popularity of the federated learning framework due to its success in a wide range of collaborative learning tasks also induces certain security concerns regarding the learned model due to the possibility of malicious clients participating in the learning process. Hence, the objective is to neutralize the impact of the malicious participants and to ensure the final model is trustable. One common observation regarding the Byzantine attacks is that the higher the variance among the clients' models/updates, the more space for attacks to be hidden. To this end, it has been recently shown that by utilizing momentum, thus reducing the variance, it is possible to weaken the strength of the known Byzantine attacks. The Centered Clipping framework (ICML 2021) has further shown that, besides reducing the variance, the momentum term from the previous iteration can be used as a reference point to neutralize the Byzantine attacks and show impressive performance against well-known attacks. However, in the scope of this work, we show that the centered clipping framework has certain vulnerabilities, and existing attacks can be revised based on these vulnerabilities to circumvent the centered clipping defense. Hence, we introduce a strategy to design an attack to circumvent the centered clipping framework and numerically illustrate its effectiveness against centered clipping as well as other known defense strategies by reducing test accuracy to 5-40 on best-case scenarios.
Federated Spatial Reuse Optimization in Next-Generation Decentralized IEEE 802.11 WLANs
Mar 20, 2022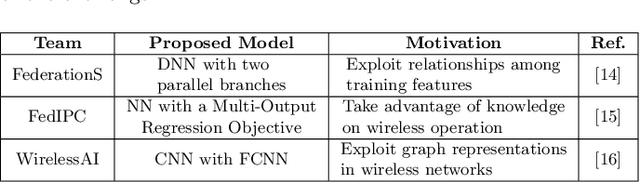

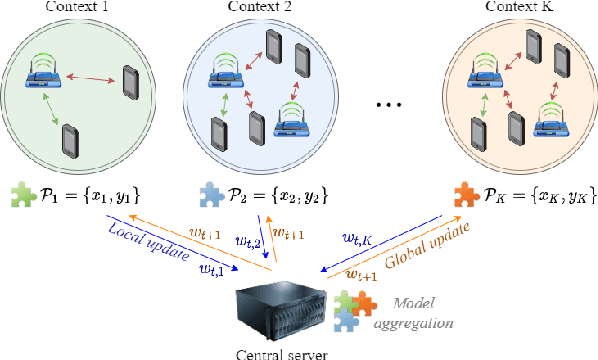
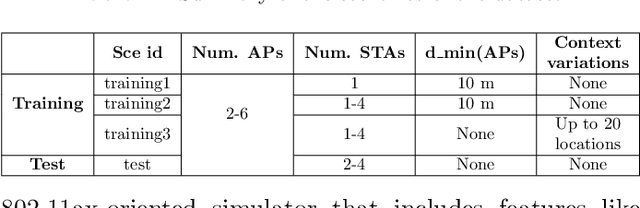
As wireless standards evolve, more complex functionalities are introduced to address the increasing requirements in terms of throughput, latency, security, and efficiency. To unleash the potential of such new features, artificial intelligence (AI) and machine learning (ML) are currently being exploited for deriving models and protocols from data, rather than by hand-programming. In this paper, we explore the feasibility of applying ML in next-generation wireless local area networks (WLANs). More specifically, we focus on the IEEE 802.11ax spatial reuse (SR) problem and predict its performance through federated learning (FL) models. The set of FL solutions overviewed in this work is part of the 2021 International Telecommunication Union (ITU) AI for 5G Challenge.
Less is More: Feature Selection for Adversarial Robustness with Compressive Counter-Adversarial Attacks
Jun 18, 2021
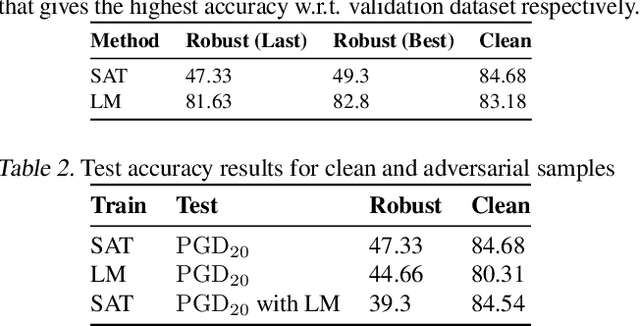
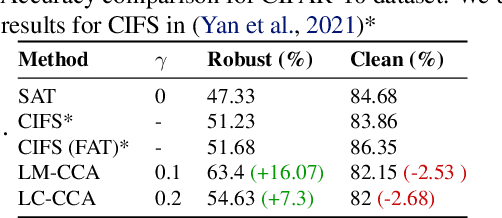
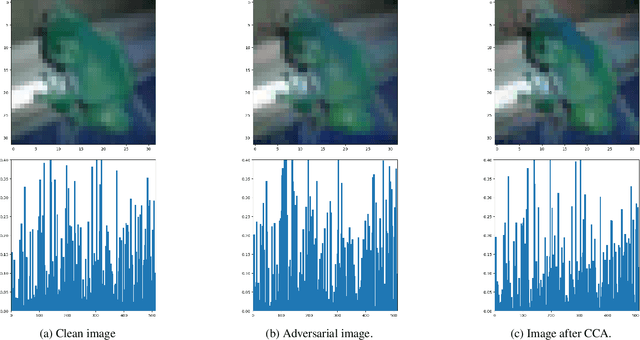
A common observation regarding adversarial attacks is that they mostly give rise to false activation at the penultimate layer to fool the classifier. Assuming that these activation values correspond to certain features of the input, the objective becomes choosing the features that are most useful for classification. Hence, we propose a novel approach to identify the important features by employing counter-adversarial attacks, which highlights the consistency at the penultimate layer with respect to perturbations on input samples. First, we empirically show that there exist a subset of features, classification based in which bridge the gap between the clean and robust accuracy. Second, we propose a simple yet efficient mechanism to identify those features by searching the neighborhood of input sample. We then select features by observing the consistency of the activation values at the penultimate layer.
Time-Correlated Sparsification for Communication-Efficient Federated Learning
Jan 21, 2021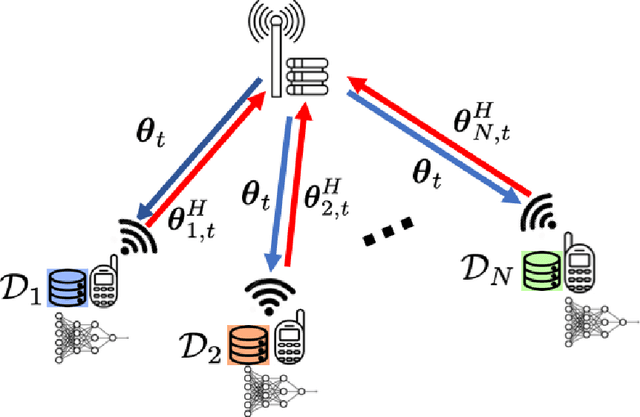
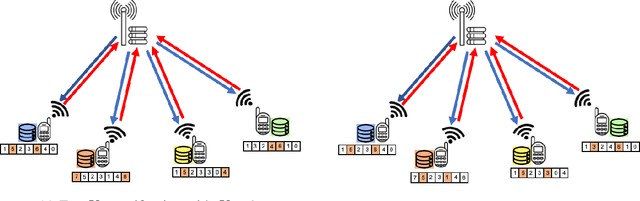
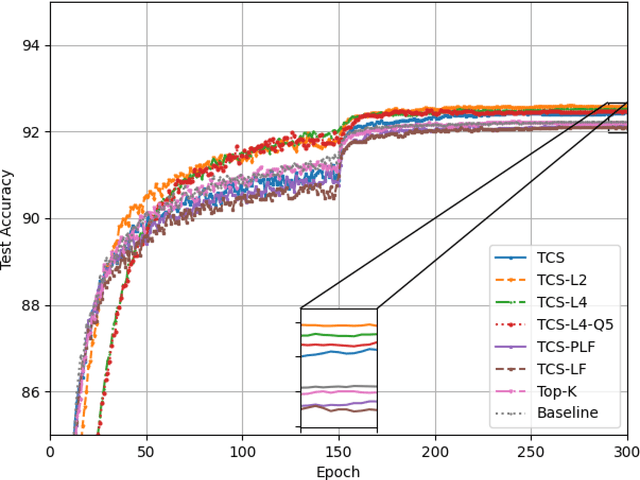
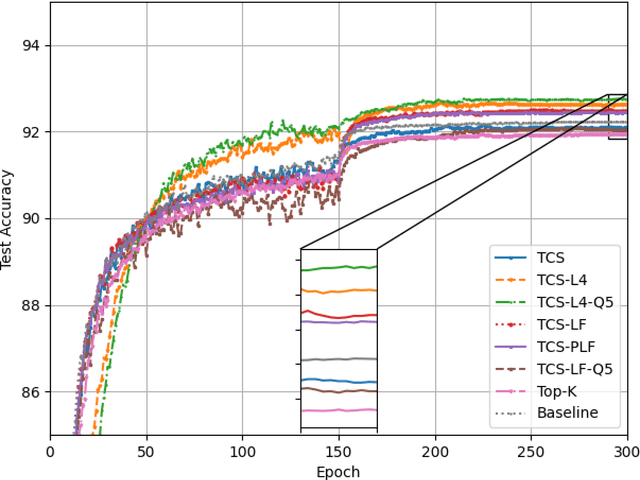
Federated learning (FL) enables multiple clients to collaboratively train a shared model without disclosing their local datasets. This is achieved by exchanging local model updates with the help of a parameter server (PS). However, due to the increasing size of the trained models, the communication load due to the iterative exchanges between the clients and the PS often becomes a bottleneck in the performance. Sparse communication is often employed to reduce the communication load, where only a small subset of the model updates are communicated from the clients to the PS. In this paper, we introduce a novel time-correlated sparsification (TCS) scheme, which builds upon the notion that sparse communication framework can be considered as identifying the most significant elements of the underlying model. Hence, TCS seeks a certain correlation between the sparse representations used at consecutive iterations in FL, so that the overhead due to encoding and transmission of the sparse representation can be significantly reduced without compromising the test accuracy. Through extensive simulations on the CIFAR-10 dataset, we show that TCS can achieve centralized training accuracy with 100 times sparsification, and up to 2000 times reduction in the communication load when employed together with quantization.
FedADC: Accelerated Federated Learning with Drift Control
Dec 16, 2020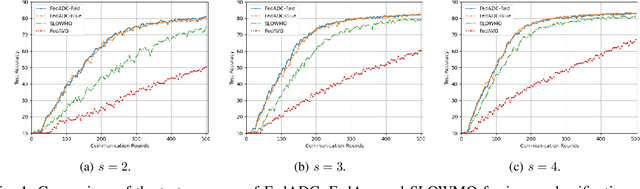
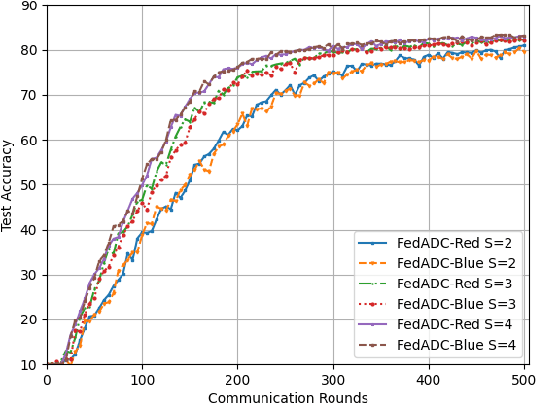
Federated learning (FL) has become de facto framework for collaborative learning among edge devices with privacy concern. The core of the FL strategy is the use of stochastic gradient descent (SGD) in a distributed manner. Large scale implementation of FL brings new challenges, such as the incorporation of acceleration techniques designed for SGD into the distributed setting, and mitigation of the drift problem due to non-homogeneous distribution of local datasets. These two problems have been separately studied in the literature; whereas, in this paper, we show that it is possible to address both problems using a single strategy without any major alteration to the FL framework, or introducing additional computation and communication load. To achieve this goal, we propose FedADC, which is an accelerated FL algorithm with drift control. We empirically illustrate the advantages of FedADC.
Distributed Sparse SGD with Majority Voting
Nov 12, 2020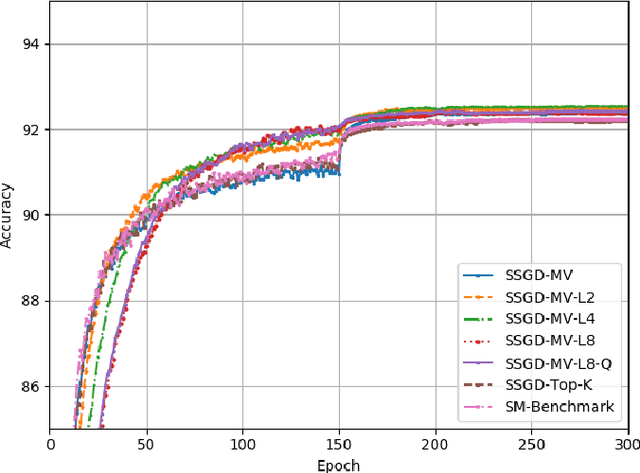
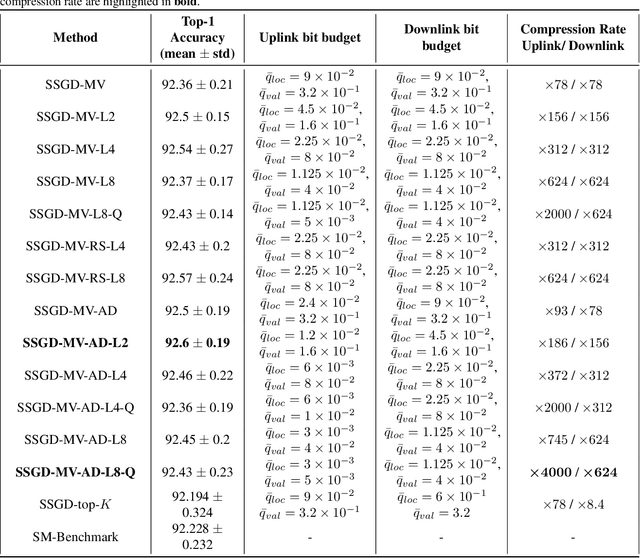
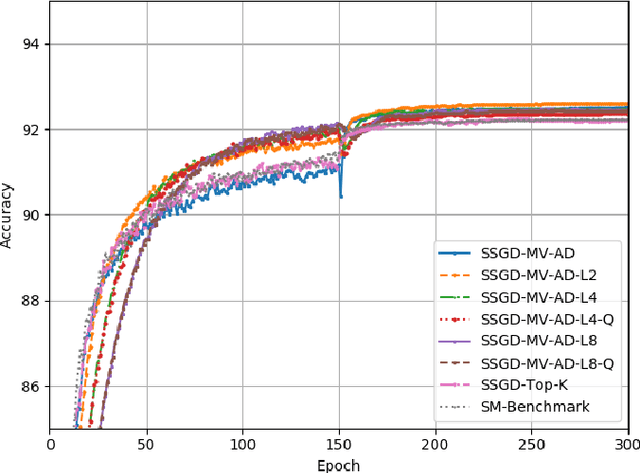
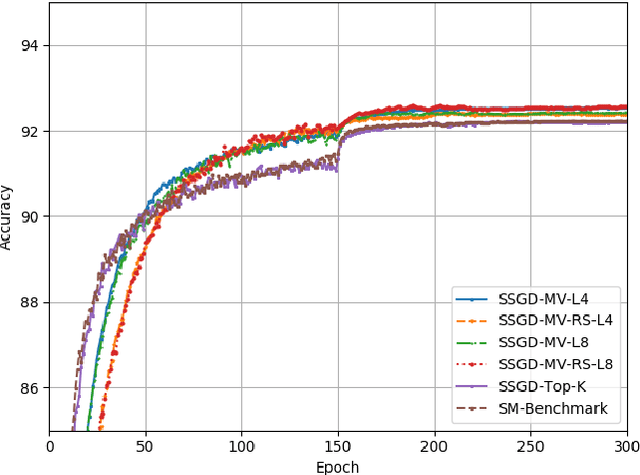
Distributed learning, particularly variants of distributed stochastic gradient descent (DSGD), are widely employed to speed up training by leveraging computational resources of several workers. However, in practise, communication delay becomes a bottleneck due to the significant amount of information that needs to be exchanged between the workers and the parameter server. One of the most efficient strategies to mitigate the communication bottleneck is top-K sparsification. However, top-K sparsification requires additional communication load to represent the sparsity pattern, and the mismatch between the sparsity patterns of the workers prevents exploitation of efficient communication protocols. To address these issues, we introduce a novel majority voting based sparse communication strategy, in which the workers first seek a consensus on the structure of the sparse representation. This strategy provides a significant reduction in the communication load and allows using the same sparsity level in both communication directions. Through extensive simulations on the CIFAR-10 dataset, we show that it is possible to achieve up to x4000 compression without any loss in the test accuracy.