 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersona-Conditioned Adversarial Prompting: Multi-Identity Red-Teaming for Adversarial Discovery and Mitigation
May 12, 2026Automated red-teaming for LLMs often discovers narrow attack slices, missing diverse real-world threats, and yielding insufficient data for safety fine-tuning. We introduce Persona-Conditioned Adversarial Prompting (PCAP), which conditions adversarial search on diverse attacker personas (e.g., doctors, students, malicious actors) and strategy sets to explore realistic attack scenarios. By running parallel persona-conditioned searches, PCAP discovers transferable jailbreaks across different contexts and generates rich defense datasets with automatic metadata tracking. On GPT-OSS 120B, PCAP increases attack success from 57\% to 97\% while producing 2-6$\times$ more diverse prompts covering varied real-world scenarios. Critically, fine-tuning lightweight adapters on PCAP-generated data significantly improves model robustness (recall: 0.36 $\rightarrow$ 0.99, F1: 0.53 $\rightarrow$ 0.96) with minimal false positives, demonstrating a practical closed-loop approach from vulnerability discovery to automated alignment.
MAD-MAX: Modular And Diverse Malicious Attack MiXtures for Automated LLM Red Teaming
Mar 08, 2025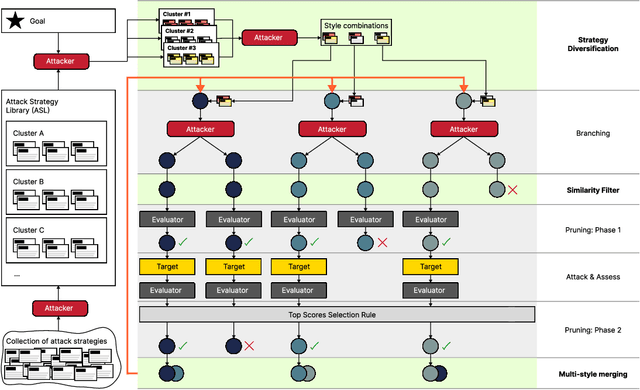
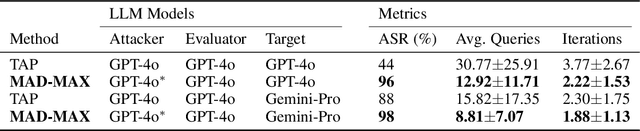
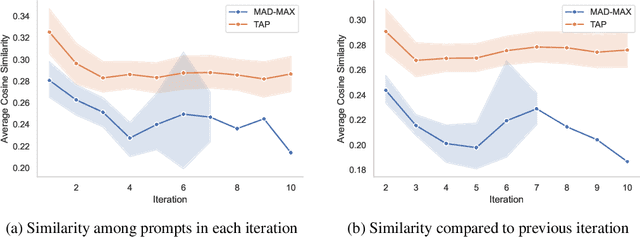
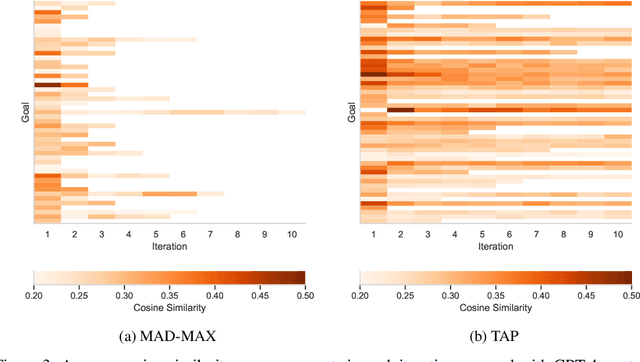
With LLM usage rapidly increasing, their vulnerability to jailbreaks that create harmful outputs are a major security risk. As new jailbreaking strategies emerge and models are changed by fine-tuning, continuous testing for security vulnerabilities is necessary. Existing Red Teaming methods fall short in cost efficiency, attack success rate, attack diversity, or extensibility as new attack types emerge. We address these challenges with Modular And Diverse Malicious Attack MiXtures (MAD-MAX) for Automated LLM Red Teaming. MAD-MAX uses automatic assignment of attack strategies into relevant attack clusters, chooses the most relevant clusters for a malicious goal, and then combines strategies from the selected clusters to achieve diverse novel attacks with high attack success rates. MAD-MAX further merges promising attacks together at each iteration of Red Teaming to boost performance and introduces a similarity filter to prune out similar attacks for increased cost efficiency. The MAD-MAX approach is designed to be easily extensible with newly discovered attack strategies and outperforms the prominent Red Teaming method Tree of Attacks with Pruning (TAP) significantly in terms of Attack Success Rate (ASR) and queries needed to achieve jailbreaks. MAD-MAX jailbreaks 97% of malicious goals in our benchmarks on GPT-4o and Gemini-Pro compared to TAP with 66%. MAD-MAX does so with only 10.9 average queries to the target LLM compared to TAP with 23.3. WARNING: This paper contains contents which are offensive in nature.
Adversarial Prompt Evaluation: Systematic Benchmarking of Guardrails Against Prompt Input Attacks on LLMs
Feb 21, 2025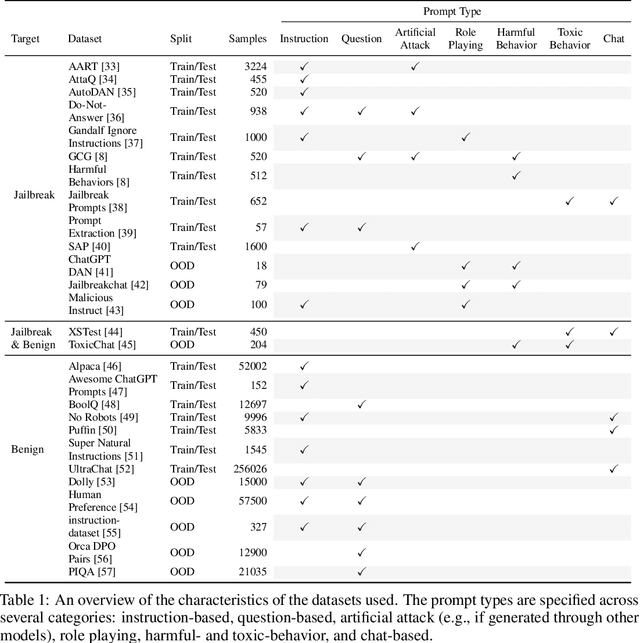
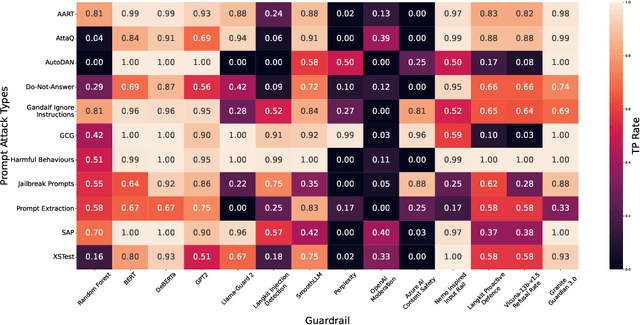
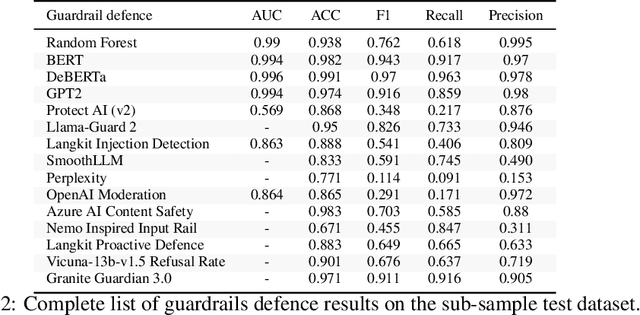
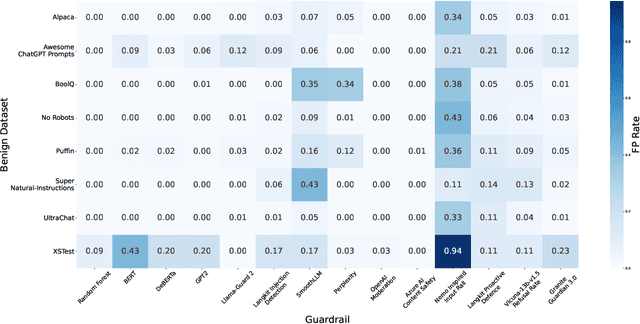
As large language models (LLMs) become integrated into everyday applications, ensuring their robustness and security is increasingly critical. In particular, LLMs can be manipulated into unsafe behaviour by prompts known as jailbreaks. The variety of jailbreak styles is growing, necessitating the use of external defences known as guardrails. While many jailbreak defences have been proposed, not all defences are able to handle new out-of-distribution attacks due to the narrow segment of jailbreaks used to align them. Moreover, the lack of systematisation around defences has created significant gaps in their practical application. In this work, we perform systematic benchmarking across 15 different defences, considering a broad swathe of malicious and benign datasets. We find that there is significant performance variation depending on the style of jailbreak a defence is subject to. Additionally, we show that based on current datasets available for evaluation, simple baselines can display competitive out-of-distribution performance compared to many state-of-the-art defences. Code is available at https://github.com/IBM/Adversarial-Prompt-Evaluation.
Granite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
Boundary Adversarial Examples Against Adversarial Overfitting
Nov 25, 2022



Standard adversarial training approaches suffer from robust overfitting where the robust accuracy decreases when models are adversarially trained for too long. The origin of this problem is still unclear and conflicting explanations have been reported, i.e., memorization effects induced by large loss data or because of small loss data and growing differences in loss distribution of training samples as the adversarial training progresses. Consequently, several mitigation approaches including early stopping, temporal ensembling and weight perturbations on small loss data have been proposed to mitigate the effect of robust overfitting. However, a side effect of these strategies is a larger reduction in clean accuracy compared to standard adversarial training. In this paper, we investigate if these mitigation approaches are complimentary to each other in improving adversarial training performance. We further propose the use of helper adversarial examples that can be obtained with minimal cost in the adversarial example generation, and show how they increase the clean accuracy in the existing approaches without compromising the robust accuracy.
Less is More: Feature Selection for Adversarial Robustness with Compressive Counter-Adversarial Attacks
Jun 18, 2021
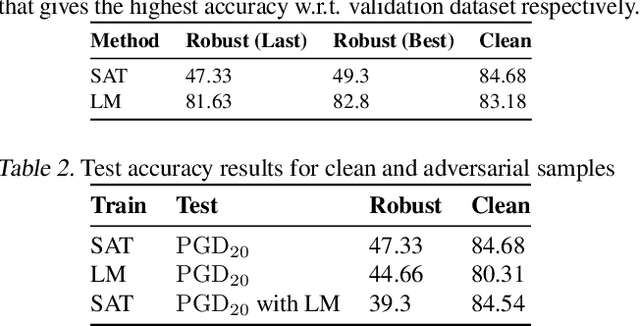
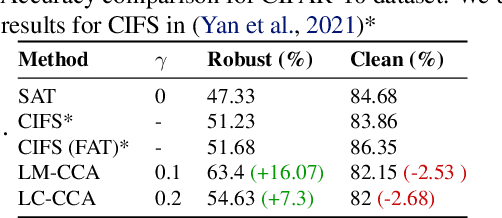
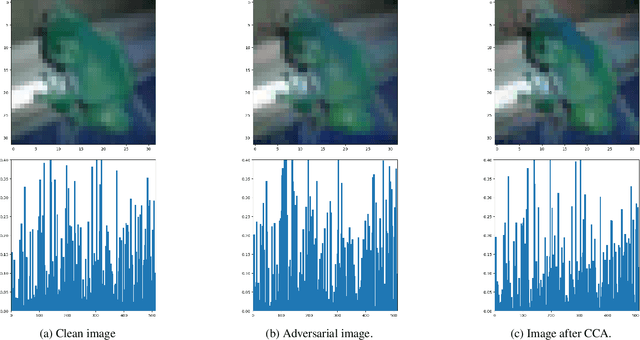
A common observation regarding adversarial attacks is that they mostly give rise to false activation at the penultimate layer to fool the classifier. Assuming that these activation values correspond to certain features of the input, the objective becomes choosing the features that are most useful for classification. Hence, we propose a novel approach to identify the important features by employing counter-adversarial attacks, which highlights the consistency at the penultimate layer with respect to perturbations on input samples. First, we empirically show that there exist a subset of features, classification based in which bridge the gap between the clean and robust accuracy. Second, we propose a simple yet efficient mechanism to identify those features by searching the neighborhood of input sample. We then select features by observing the consistency of the activation values at the penultimate layer.
Perceptually Constrained Adversarial Attacks
Feb 14, 2021
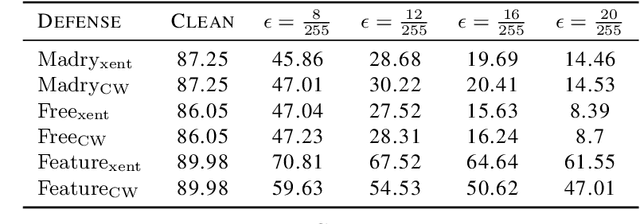
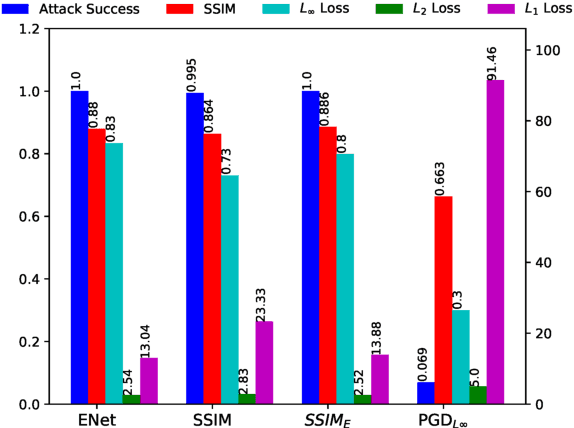

Motivated by previous observations that the usually applied $L_p$ norms ($p=1,2,\infty$) do not capture the perceptual quality of adversarial examples in image classification, we propose to replace these norms with the structural similarity index (SSIM) measure, which was developed originally to measure the perceptual similarity of images. Through extensive experiments with adversarially trained classifiers for MNIST and CIFAR-10, we demonstrate that our SSIM-constrained adversarial attacks can break state-of-the-art adversarially trained classifiers and achieve similar or larger success rate than the elastic net attack, while consistently providing adversarial images of better perceptual quality. Utilizing SSIM to automatically identify and disallow adversarial images of low quality, we evaluate the performance of several defense schemes in a perceptually much more meaningful way than was done previously in the literature.
Communication without Interception: Defense against Deep-Learning-based Modulation Detection
Feb 27, 2019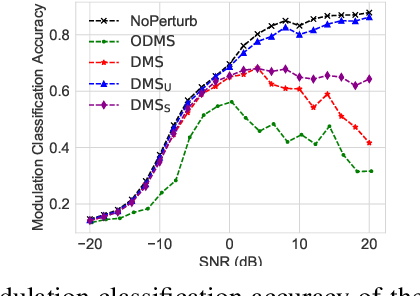
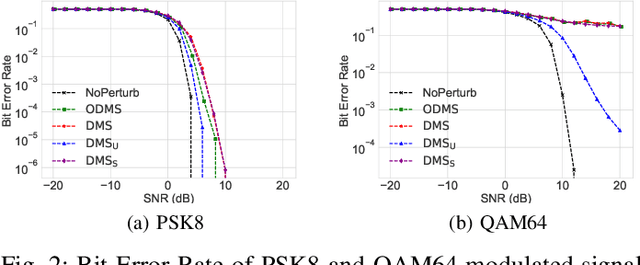
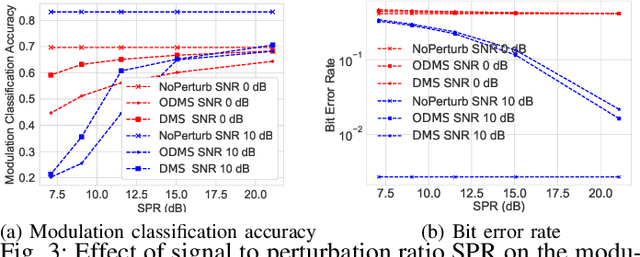
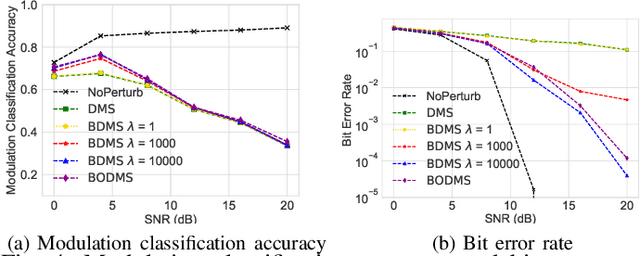
We consider a communication scenario, in which an intruder, employing a deep neural network (DNN), tries to determine the modulation scheme of the intercepted signal. Our aim is to minimize the accuracy of the intruder, while guaranteeing that the intended receiver can still recover the underlying message with the highest reliability. This is achieved by constellation perturbation at the encoder, similarly to adversarial attacks against DNN-based classifiers. In the latter perturbation is limited to be imperceptible to a human observer, while in our case perturbation is constrained so that the message can still be reliably decoded by the legitimate receiver which is oblivious to the perturbation. Simulation results demonstrate the viability of our approach to make wireless communication secure against DNN-based intruders with minimal sacrifice in the communication performance.