 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTBDFiltering: Sample-Efficient Tree-Based Data Filtering
Jan 29, 2026The quality of machine learning models depends heavily on their training data. Selecting high-quality, diverse training sets for large language models (LLMs) is a difficult task, due to the lack of cheap and reliable quality metrics. While querying existing LLMs for document quality is common, this is not scalable to the large number (billions) of documents used in training. Instead, practitioners often use classifiers trained on sparse quality signals. In this paper, we propose a text-embedding-based hierarchical clustering approach that adaptively selects the documents to be evaluated by the LLM to estimate cluster quality. We prove that our method is query efficient: under the assumption that the hierarchical clustering contains a subtree such that each leaf cluster in the tree is pure enough (i.e., it mostly contains either only good or only bad documents), with high probability, the method can correctly predict the quality of each document after querying a small number of documents. The number of such documents is proportional to the size of the smallest subtree with (almost) pure leaves, without the algorithm knowing this subtree in advance. Furthermore, in a comprehensive experimental study, we demonstrate the benefits of our algorithm compared to other classifier-based filtering methods.
What Can Grokking Teach Us About Learning Under Nonstationarity?
Jul 26, 2025In continual learning problems, it is often necessary to overwrite components of a neural network's learned representation in response to changes in the data stream; however, neural networks often exhibit \primacy bias, whereby early training data hinders the network's ability to generalize on later tasks. While feature-learning dynamics of nonstationary learning problems are not well studied, the emergence of feature-learning dynamics is known to drive the phenomenon of grokking, wherein neural networks initially memorize their training data and only later exhibit perfect generalization. This work conjectures that the same feature-learning dynamics which facilitate generalization in grokking also underlie the ability to overwrite previous learned features as well, and methods which accelerate grokking by facilitating feature-learning dynamics are promising candidates for addressing primacy bias in non-stationary learning problems. We then propose a straightforward method to induce feature-learning dynamics as needed throughout training by increasing the effective learning rate, i.e. the ratio between parameter and update norms. We show that this approach both facilitates feature-learning and improves generalization in a variety of settings, including grokking, warm-starting neural network training, and reinforcement learning tasks.
Partition Tree Weighting for Non-Stationary Stochastic Bandits
Feb 26, 2025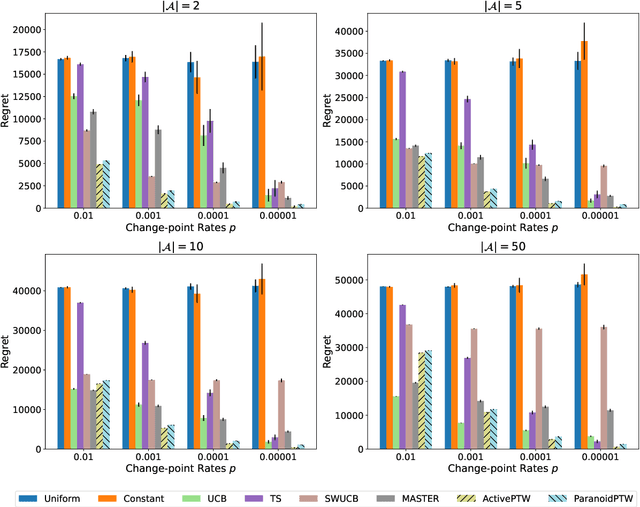
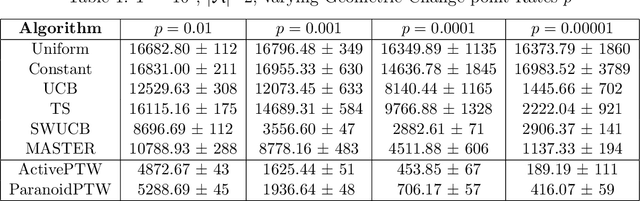
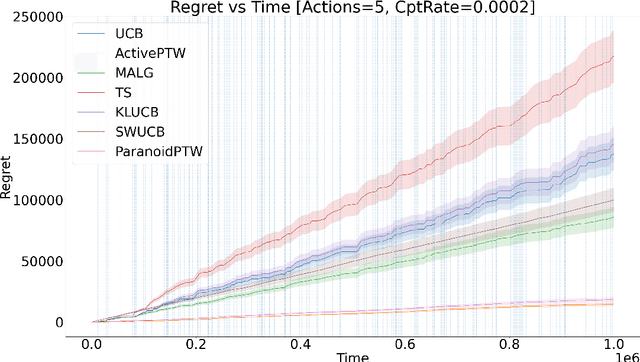
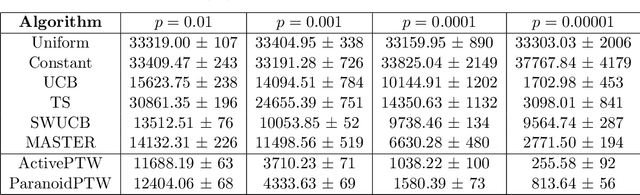
This paper considers a generalisation of universal source coding for interaction data, namely data streams that have actions interleaved with observations. Our goal will be to construct a coding distribution that is both universal \emph{and} can be used as a control policy. Allowing for action generation needs careful treatment, as naive approaches which do not distinguish between actions and observations run into the self-delusion problem in universal settings. We showcase our perspective in the context of the challenging non-stationary stochastic Bernoulli bandit problem. Our main contribution is an efficient and high performing algorithm for this problem that generalises the Partition Tree Weighting universal source coding technique for passive prediction to the control setting.
A New Look at Dynamic Regret for Non-Stationary Stochastic Bandits
Jan 17, 2022We study the non-stationary stochastic multi-armed bandit problem, where the reward statistics of each arm may change several times during the course of learning. The performance of a learning algorithm is evaluated in terms of their dynamic regret, which is defined as the difference of the expected cumulative reward of an agent choosing the optimal arm in every round and the cumulative reward of the learning algorithm. One way to measure the hardness of such environments is to consider how many times the identity of the optimal arm can change. We propose a method that achieves, in $K$-armed bandit problems, a near-optimal $\widetilde O(\sqrt{K N(S+1)})$ dynamic regret, where $N$ is the number of rounds and $S$ is the number of times the identity of the optimal arm changes, without prior knowledge of $S$ and $N$. Previous works for this problem obtain regret bounds that scale with the number of changes (or the amount of change) in the reward functions, which can be much larger, or assume prior knowledge of $S$ to achieve similar bounds.
Learning to Minimize Age of Information over an Unreliable Channel with Energy Harvesting
Jun 30, 2021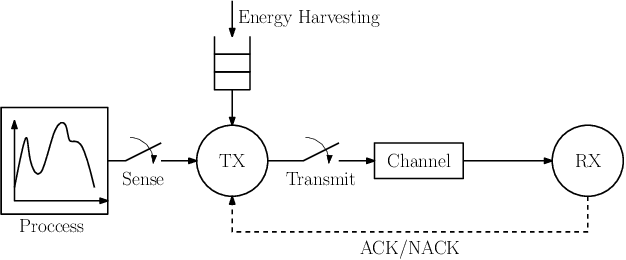
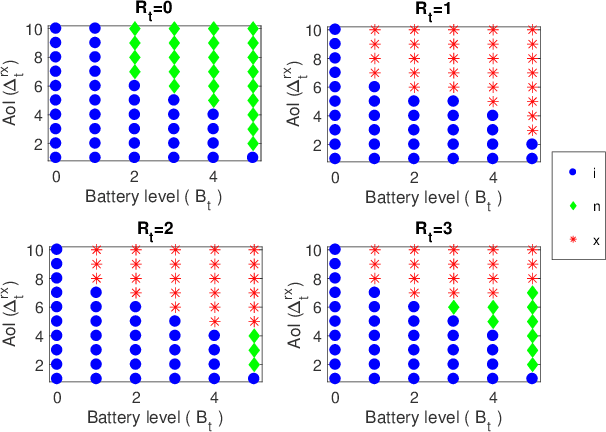
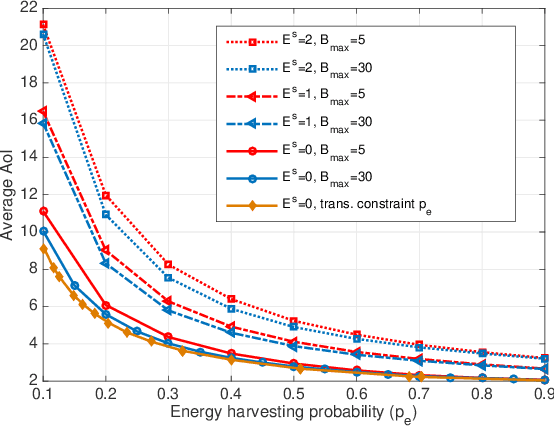
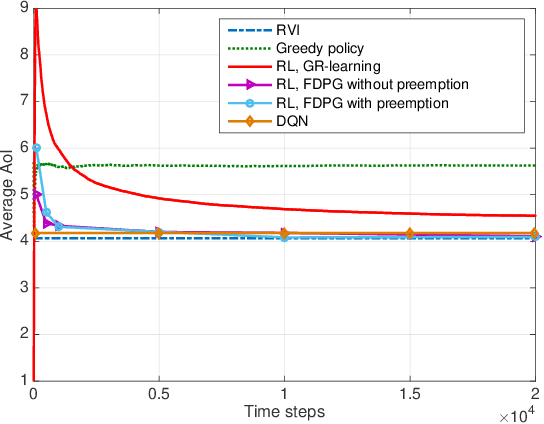
The time average expected age of information (AoI) is studied for status updates sent over an error-prone channel from an energy-harvesting transmitter with a finite-capacity battery. Energy cost of sensing new status updates is taken into account as well as the transmission energy cost better capturing practical systems. The optimal scheduling policy is first studied under the hybrid automatic repeat request (HARQ) protocol when the channel and energy harvesting statistics are known, and the existence of a threshold-based optimal policy is shown. For the case of unknown environments, average-cost reinforcement-learning algorithms are proposed that learn the system parameters and the status update policy in real-time. The effectiveness of the proposed methods is demonstrated through numerical results.
On Multi-objective Policy Optimization as a Tool for Reinforcement Learning
Jun 15, 2021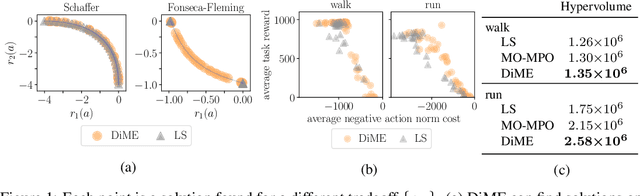
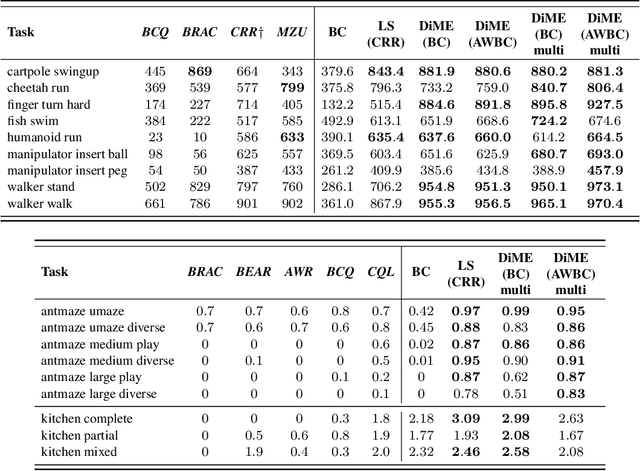
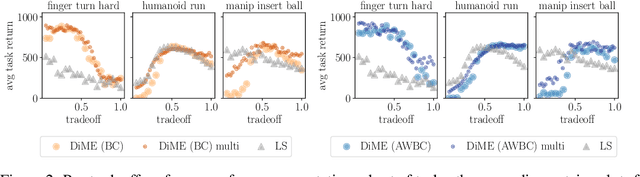

Many advances that have improved the robustness and efficiency of deep reinforcement learning (RL) algorithms can, in one way or another, be understood as introducing additional objectives, or constraints, in the policy optimization step. This includes ideas as far ranging as exploration bonuses, entropy regularization, and regularization toward teachers or data priors when learning from experts or in offline RL. Often, task reward and auxiliary objectives are in conflict with each other and it is therefore natural to treat these examples as instances of multi-objective (MO) optimization problems. We study the principles underlying MORL and introduce a new algorithm, Distillation of a Mixture of Experts (DiME), that is intuitive and scale-invariant under some conditions. We highlight its strengths on standard MO benchmark problems and consider case studies in which we recast offline RL and learning from experts as MO problems. This leads to a natural algorithmic formulation that sheds light on the connection between existing approaches. For offline RL, we use the MO perspective to derive a simple algorithm, that optimizes for the standard RL objective plus a behavioral cloning term. This outperforms state-of-the-art on two established offline RL benchmarks.
Defending Against Image Corruptions Through Adversarial Augmentations
Apr 20, 2021
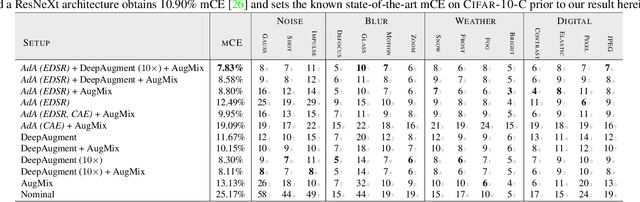
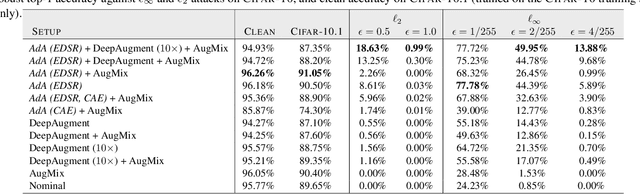
Modern neural networks excel at image classification, yet they remain vulnerable to common image corruptions such as blur, speckle noise or fog. Recent methods that focus on this problem, such as AugMix and DeepAugment, introduce defenses that operate in expectation over a distribution of image corruptions. In contrast, the literature on $\ell_p$-norm bounded perturbations focuses on defenses against worst-case corruptions. In this work, we reconcile both approaches by proposing AdversarialAugment, a technique which optimizes the parameters of image-to-image models to generate adversarially corrupted augmented images. We theoretically motivate our method and give sufficient conditions for the consistency of its idealized version as well as that of DeepAugment. Our classifiers improve upon the state-of-the-art on common image corruption benchmarks conducted in expectation on CIFAR-10-C and improve worst-case performance against $\ell_p$-norm bounded perturbations on both CIFAR-10 and ImageNet.
A Reinforcement Learning Approach to Age of Information in Multi-User Networks with HARQ
Feb 19, 2021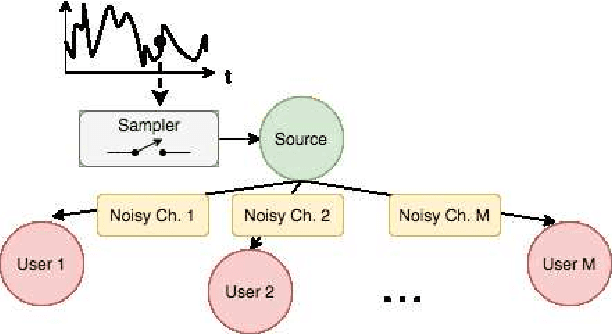
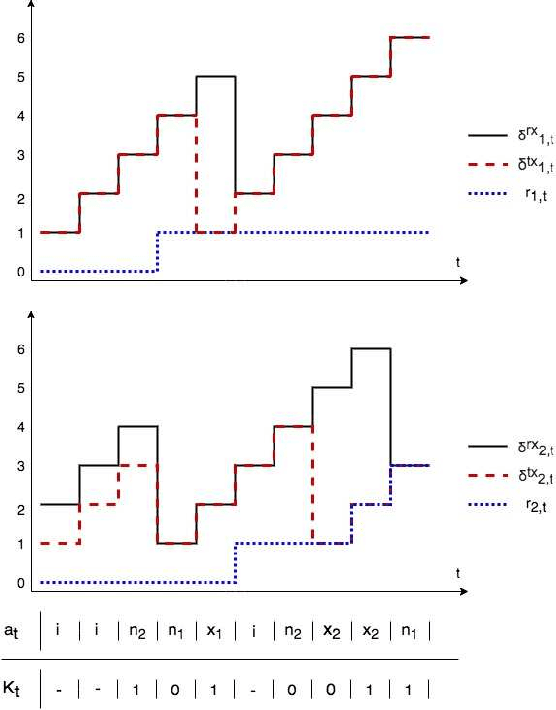
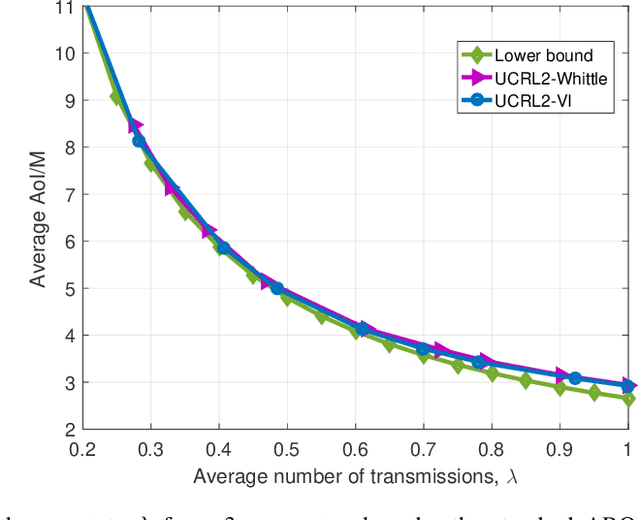
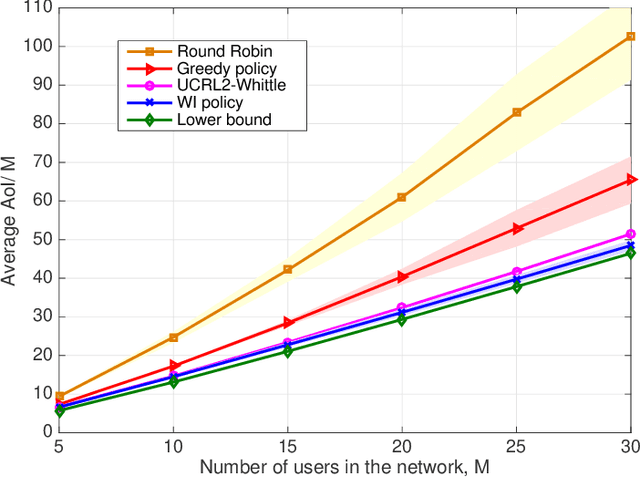
Scheduling the transmission of time-sensitive information from a source node to multiple users over error-prone communication channels is studied with the goal of minimizing the long-term average age of information (AoI) at the users. A long-term average resource constraint is imposed on the source, which limits the average number of transmissions. The source can transmit only to a single user at each time slot, and after each transmission, it receives an instantaneous ACK/NACK feedback from the intended receiver, and decides when and to which user to transmit the next update. Assuming the channel statistics are known, the optimal scheduling policy is studied for both the standard automatic repeat request (ARQ) and hybrid ARQ (HARQ) protocols. Then, a reinforcement learning(RL) approach is introduced to find a near-optimal policy, which does not assume any a priori information on the random processes governing the channel states. Different RL methods including average-cost SARSAwith linear function approximation (LFA), upper confidence reinforcement learning (UCRL2), and deep Q-network (DQN) are applied and compared through numerical simulations
Perceptually Constrained Adversarial Attacks
Feb 14, 2021
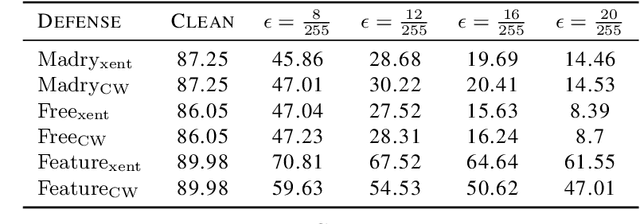
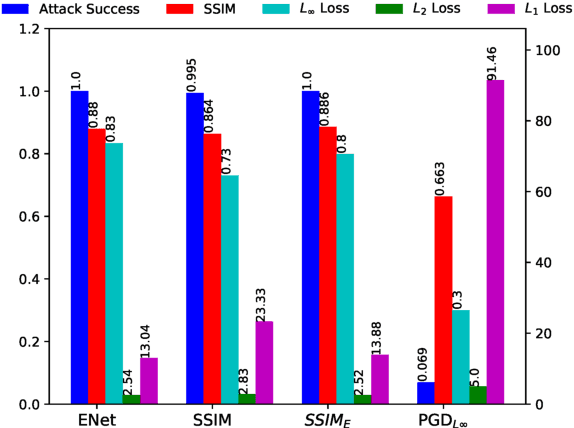

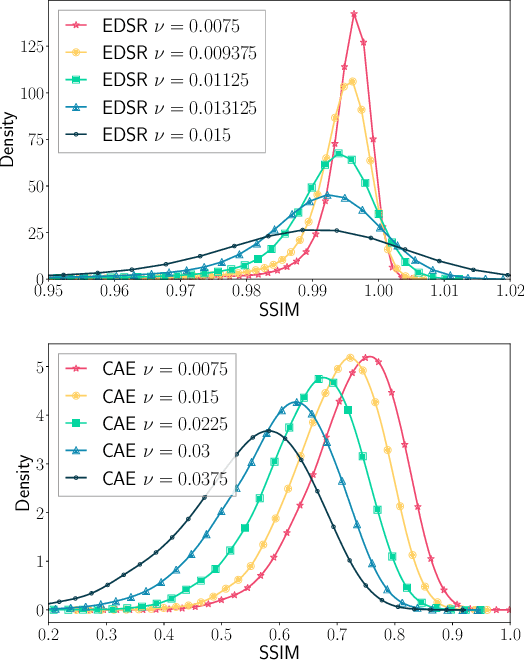
Motivated by previous observations that the usually applied $L_p$ norms ($p=1,2,\infty$) do not capture the perceptual quality of adversarial examples in image classification, we propose to replace these norms with the structural similarity index (SSIM) measure, which was developed originally to measure the perceptual similarity of images. Through extensive experiments with adversarially trained classifiers for MNIST and CIFAR-10, we demonstrate that our SSIM-constrained adversarial attacks can break state-of-the-art adversarially trained classifiers and achieve similar or larger success rate than the elastic net attack, while consistently providing adversarial images of better perceptual quality. Utilizing SSIM to automatically identify and disallow adversarial images of low quality, we evaluate the performance of several defense schemes in a perceptually much more meaningful way than was done previously in the literature.
Non-Stationary Bandits with Intermediate Observations
Jun 03, 2020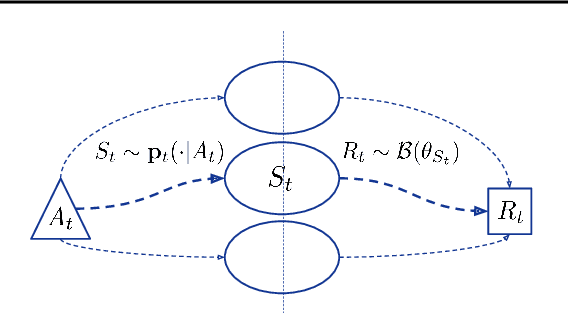
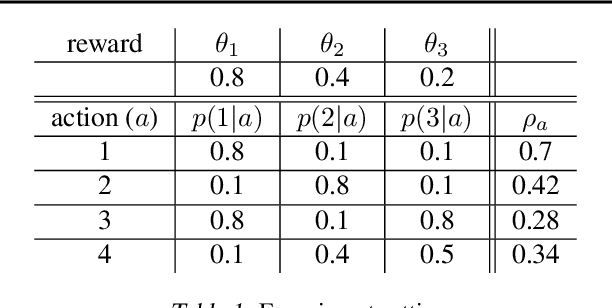
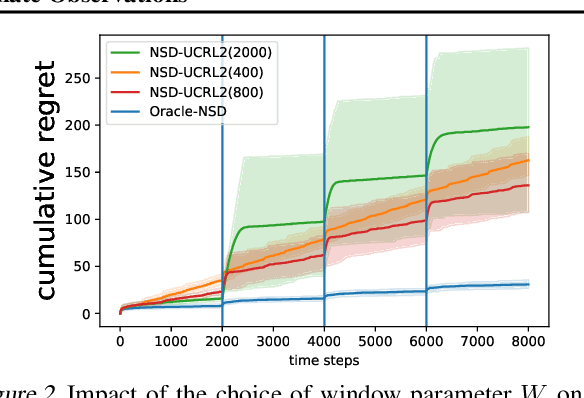
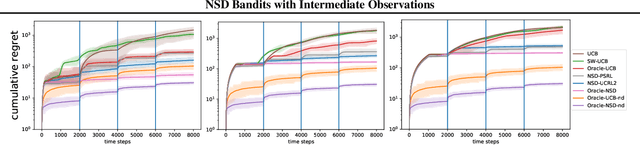
Online recommender systems often face long delays in receiving feedback, especially when optimizing for some long-term metrics. While mitigating the effects of delays in learning is well-understood in stationary environments, the problem becomes much more challenging when the environment changes. In fact, if the timescale of the change is comparable to the delay, it is impossible to learn about the environment, since the available observations are already obsolete. However, the arising issues can be addressed if intermediate signals are available without delay, such that given those signals, the long-term behavior of the system is stationary. To model this situation, we introduce the problem of stochastic, non-stationary, delayed bandits with intermediate observations. We develop a computationally efficient algorithm based on UCRL, and prove sublinear regret guarantees for its performance. Experimental results demonstrate that our method is able to learn in non-stationary delayed environments where existing methods fail.