 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASK: Multi-Agent Semantic K-Scheduling for Risk-Sensitive 6G Robotics
Jun 08, 2026Realizing the vision of 6G connected robotics requires reconciling high-performance collaborative control with the rigid spectral limitations of physical wireless channels. In realistic collaborative sensing scenarios, spectral resources are quantized into finite physical resource blocks or orthogonal subcarriers, rendering simultaneous transmission by all agents infeasible. To address this, we propose Multi-Agent Semantic K-Scheduling (MASK), a control architecture designed to sustain robust, risk-aware coordination under strict instantaneous bandwidth caps. We introduce Arbiter-Assisted Semantic Information Gating (A-SIG), a lightweight coordination mechanism that enforces hard access constraints by scheduling only the top-K agents based on locally computed semantic importance scores. By aggregating these prioritized observations into a compact latent state, a self-supervised global encoder enables a distributional policy to mitigate tail risks despite data sparsity. We evaluate MASK across diverse benchmarks, demonstrating that it matches the performance of communication-unconstrained baselines even when channel access is restricted to a small fraction of the swarm size. Furthermore, the framework exhibits inherent resilience to packet erasures, validating semantic scheduling as a critical enabler for resource-constrained 6G systems.
Deep Reinforcement Learning Enhanced Rate-Splitting Multiple Access for Interference Mitigation
Mar 09, 2024
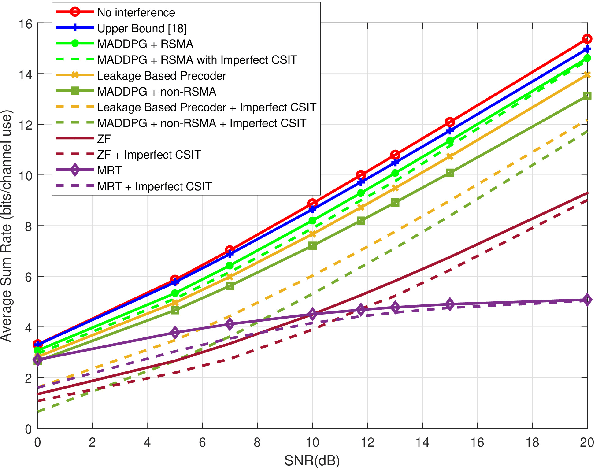


This study explores the application of the rate-splitting multiple access (RSMA) technique, vital for interference mitigation in modern communication systems. It investigates the use of precoding methods in RSMA, especially in complex multiple-antenna interference channels, employing deep reinforcement learning. The aim is to optimize precoders and power allocation for common and private data streams involving multiple decision-makers. A multi-agent deep deterministic policy gradient (MADDPG) framework is employed to address this complexity, where decentralized agents collectively learn to optimize actions in a continuous policy space. We also explore the challenges posed by imperfect channel side information at the transmitter. Additionally, decoding order estimation is addressed to determine the optimal decoding sequence for common and private data sequences. Simulation results demonstrate the effectiveness of the proposed RSMA method based on MADDPG, achieving the upper bound in single-antenna scenarios and closely approaching theoretical limits in multi-antenna scenarios. Comparative analysis shows superiority over other techniques such as MADDPG without rate-splitting, maximal ratio transmission (MRT), zero-forcing (ZF), and leakage-based precoding methods. These findings highlight the potential of deep reinforcement learning-driven RSMA in reducing interference and enhancing system performance in communication systems.
Learning to Minimize Age of Information over an Unreliable Channel with Energy Harvesting
Jun 30, 2021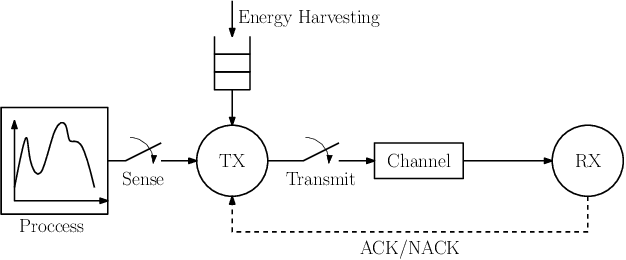
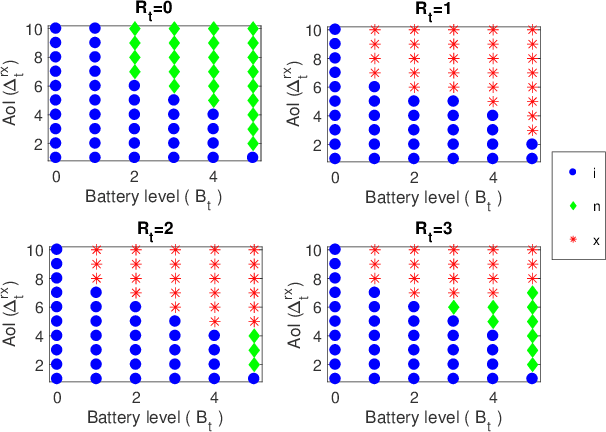
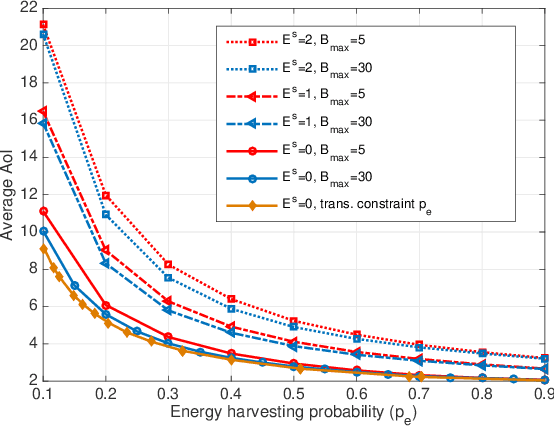
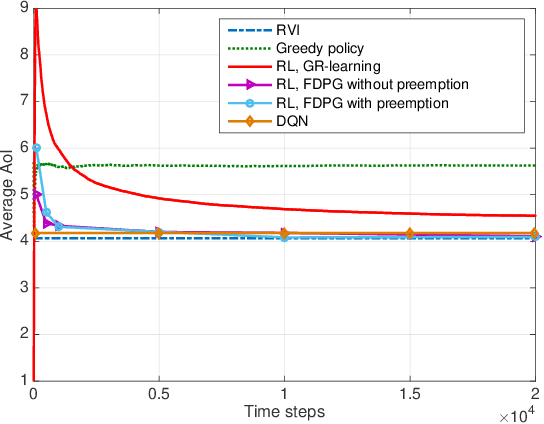
The time average expected age of information (AoI) is studied for status updates sent over an error-prone channel from an energy-harvesting transmitter with a finite-capacity battery. Energy cost of sensing new status updates is taken into account as well as the transmission energy cost better capturing practical systems. The optimal scheduling policy is first studied under the hybrid automatic repeat request (HARQ) protocol when the channel and energy harvesting statistics are known, and the existence of a threshold-based optimal policy is shown. For the case of unknown environments, average-cost reinforcement-learning algorithms are proposed that learn the system parameters and the status update policy in real-time. The effectiveness of the proposed methods is demonstrated through numerical results.
A Reinforcement Learning Approach to Age of Information in Multi-User Networks with HARQ
Feb 19, 2021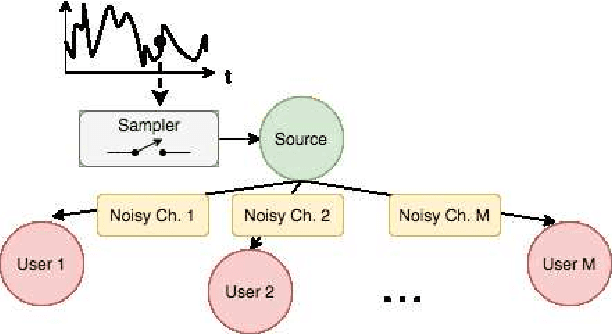
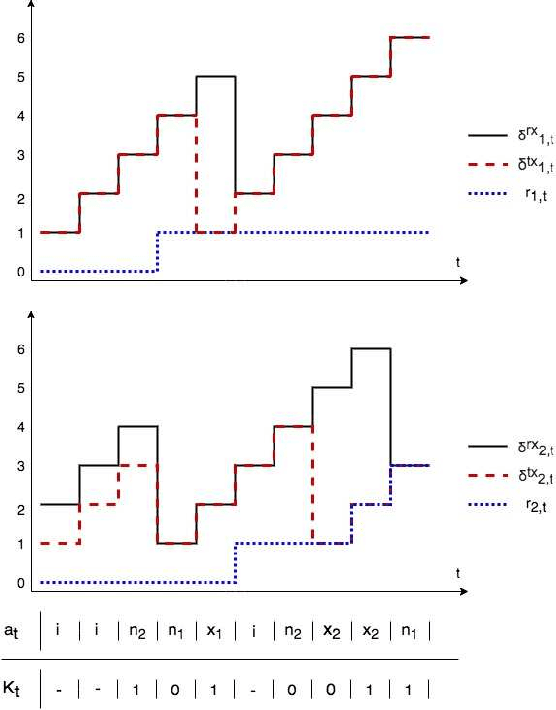
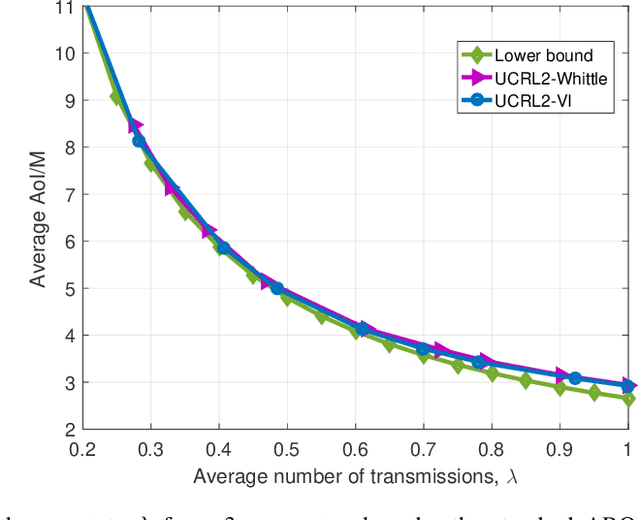
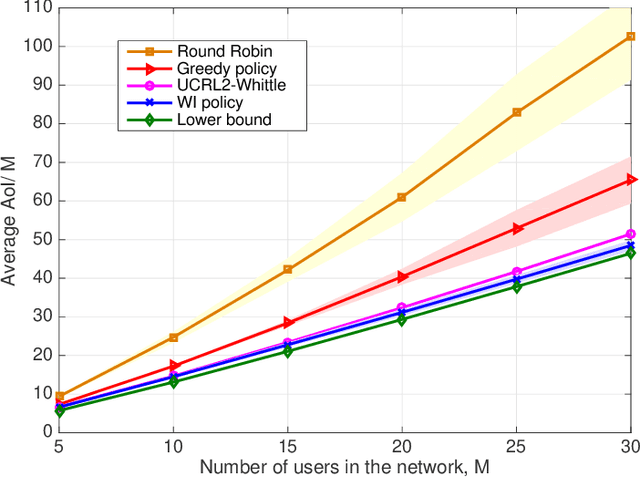
Scheduling the transmission of time-sensitive information from a source node to multiple users over error-prone communication channels is studied with the goal of minimizing the long-term average age of information (AoI) at the users. A long-term average resource constraint is imposed on the source, which limits the average number of transmissions. The source can transmit only to a single user at each time slot, and after each transmission, it receives an instantaneous ACK/NACK feedback from the intended receiver, and decides when and to which user to transmit the next update. Assuming the channel statistics are known, the optimal scheduling policy is studied for both the standard automatic repeat request (ARQ) and hybrid ARQ (HARQ) protocols. Then, a reinforcement learning(RL) approach is introduced to find a near-optimal policy, which does not assume any a priori information on the random processes governing the channel states. Different RL methods including average-cost SARSAwith linear function approximation (LFA), upper confidence reinforcement learning (UCRL2), and deep Q-network (DQN) are applied and compared through numerical simulations