 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataRater: Meta-Learned Dataset Curation
May 23, 2025The quality of foundation models depends heavily on their training data. Consequently, great efforts have been put into dataset curation. Yet most approaches rely on manual tuning of coarse-grained mixtures of large buckets of data, or filtering by hand-crafted heuristics. An approach that is ultimately more scalable (let alone more satisfying) is to \emph{learn} which data is actually valuable for training. This type of meta-learning could allow more sophisticated, fine-grained, and effective curation. Our proposed \emph{DataRater} is an instance of this idea. It estimates the value of training on any particular data point. This is done by meta-learning using `meta-gradients', with the objective of improving training efficiency on held out data. In extensive experiments across a range of model scales and datasets, we find that using our DataRater to filter data is highly effective, resulting in significantly improved compute efficiency.
Data Augmentation Can Improve Robustness
Nov 09, 2021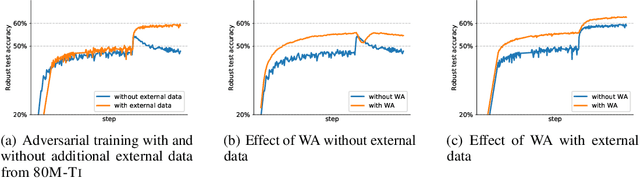
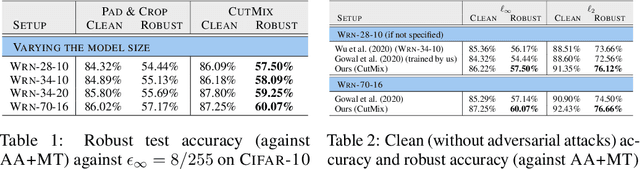
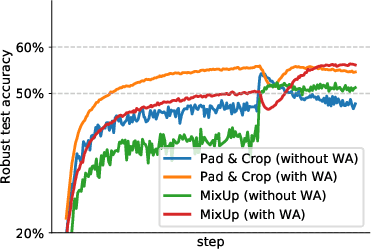
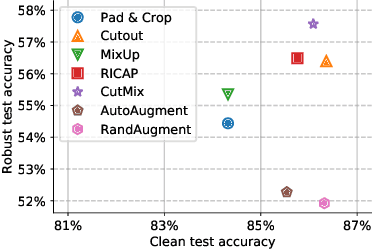
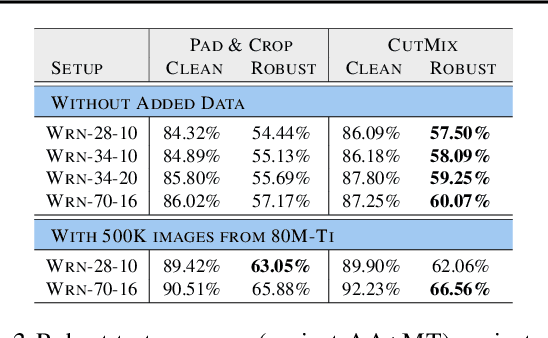
Adversarial training suffers from robust overfitting, a phenomenon where the robust test accuracy starts to decrease during training. In this paper, we focus on reducing robust overfitting by using common data augmentation schemes. We demonstrate that, contrary to previous findings, when combined with model weight averaging, data augmentation can significantly boost robust accuracy. Furthermore, we compare various augmentations techniques and observe that spatial composition techniques work the best for adversarial training. Finally, we evaluate our approach on CIFAR-10 against $\ell_\infty$ and $\ell_2$ norm-bounded perturbations of size $\epsilon = 8/255$ and $\epsilon = 128/255$, respectively. We show large absolute improvements of +2.93% and +2.16% in robust accuracy compared to previous state-of-the-art methods. In particular, against $\ell_\infty$ norm-bounded perturbations of size $\epsilon = 8/255$, our model reaches 60.07% robust accuracy without using any external data. We also achieve a significant performance boost with this approach while using other architectures and datasets such as CIFAR-100, SVHN and TinyImageNet.
Defending Against Image Corruptions Through Adversarial Augmentations
Apr 20, 2021
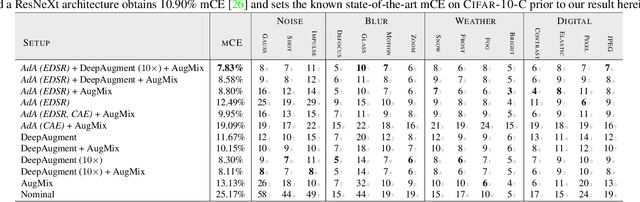
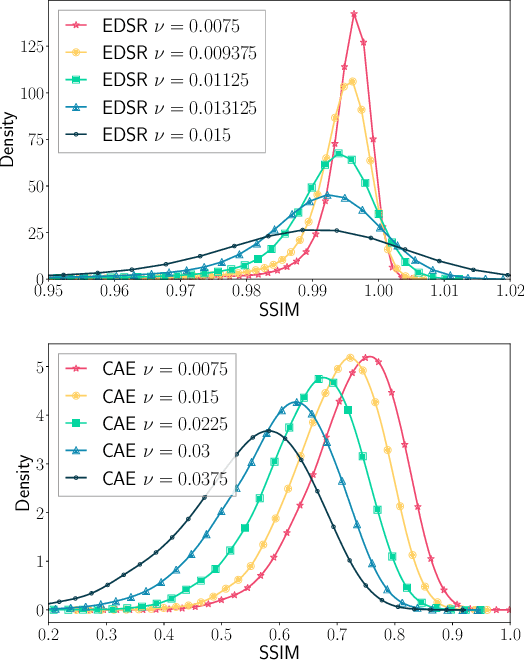
Modern neural networks excel at image classification, yet they remain vulnerable to common image corruptions such as blur, speckle noise or fog. Recent methods that focus on this problem, such as AugMix and DeepAugment, introduce defenses that operate in expectation over a distribution of image corruptions. In contrast, the literature on $\ell_p$-norm bounded perturbations focuses on defenses against worst-case corruptions. In this work, we reconcile both approaches by proposing AdversarialAugment, a technique which optimizes the parameters of image-to-image models to generate adversarially corrupted augmented images. We theoretically motivate our method and give sufficient conditions for the consistency of its idealized version as well as that of DeepAugment. Our classifiers improve upon the state-of-the-art on common image corruption benchmarks conducted in expectation on CIFAR-10-C and improve worst-case performance against $\ell_p$-norm bounded perturbations on both CIFAR-10 and ImageNet.
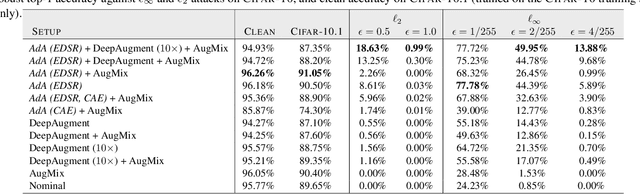
Fixing Data Augmentation to Improve Adversarial Robustness
Mar 02, 2021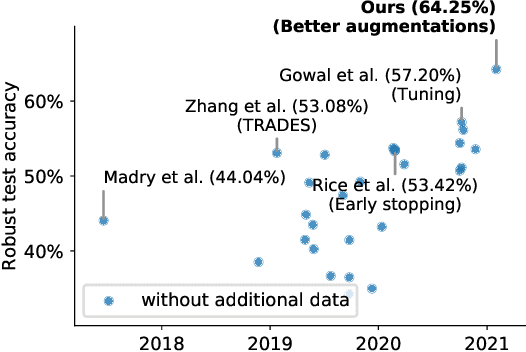
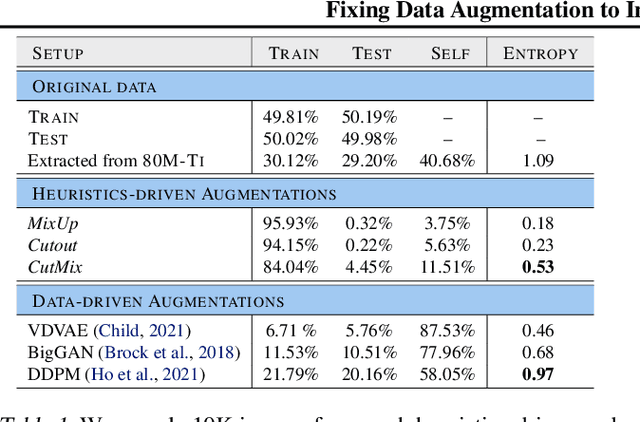
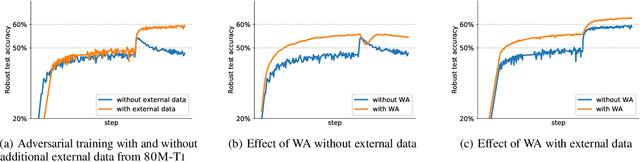
Adversarial training suffers from robust overfitting, a phenomenon where the robust test accuracy starts to decrease during training. In this paper, we focus on both heuristics-driven and data-driven augmentations as a means to reduce robust overfitting. First, we demonstrate that, contrary to previous findings, when combined with model weight averaging, data augmentation can significantly boost robust accuracy. Second, we explore how state-of-the-art generative models can be leveraged to artificially increase the size of the training set and further improve adversarial robustness. Finally, we evaluate our approach on CIFAR-10 against $\ell_\infty$ and $\ell_2$ norm-bounded perturbations of size $\epsilon = 8/255$ and $\epsilon = 128/255$, respectively. We show large absolute improvements of +7.06% and +5.88% in robust accuracy compared to previous state-of-the-art methods. In particular, against $\ell_\infty$ norm-bounded perturbations of size $\epsilon = 8/255$, our model reaches 64.20% robust accuracy without using any external data, beating most prior works that use external data.
Robust Constrained Reinforcement Learning for Continuous Control with Model Misspecification
Oct 20, 2020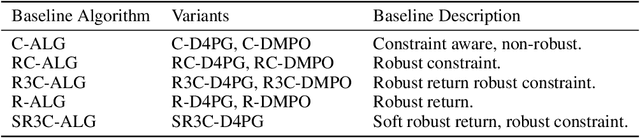
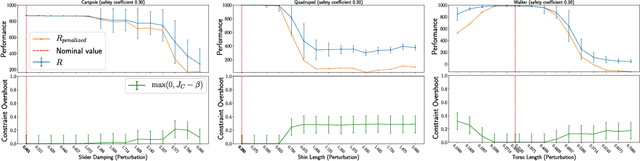
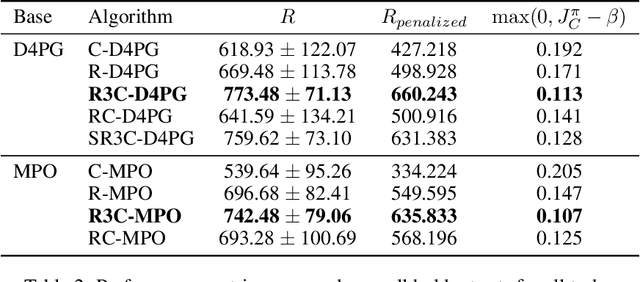
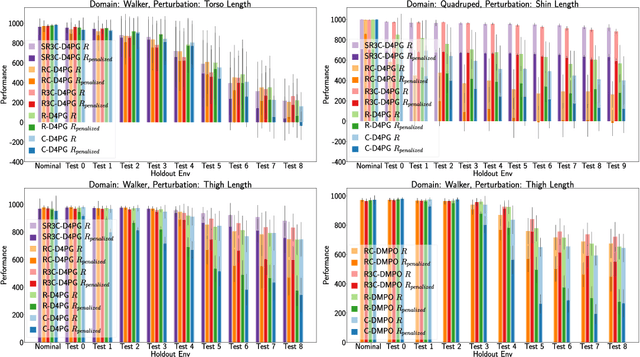
Many real-world physical control systems are required to satisfy constraints upon deployment. Furthermore, real-world systems are often subject to effects such as non-stationarity, wear-and-tear, uncalibrated sensors and so on. Such effects effectively perturb the system dynamics and can cause a policy trained successfully in one domain to perform poorly when deployed to a perturbed version of the same domain. This can affect a policy's ability to maximize future rewards as well as the extent to which it satisfies constraints. We refer to this as constrained model misspecification. We present an algorithm with theoretical guarantees that mitigates this form of misspecification, and showcase its performance in multiple Mujoco tasks from the Real World Reinforcement Learning (RWRL) suite.
Balancing Constraints and Rewards with Meta-Gradient D4PG
Oct 13, 2020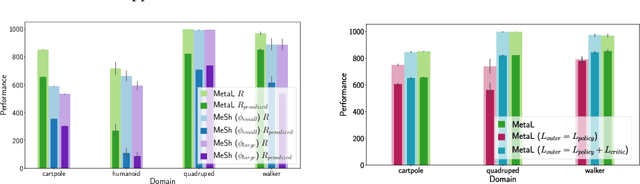
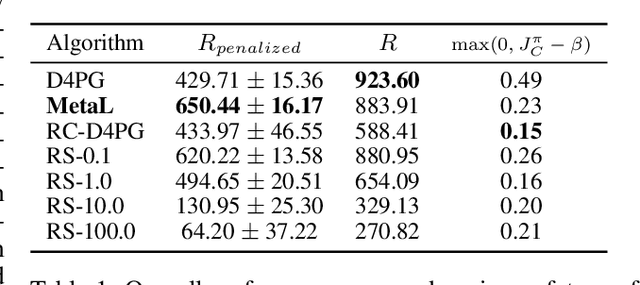

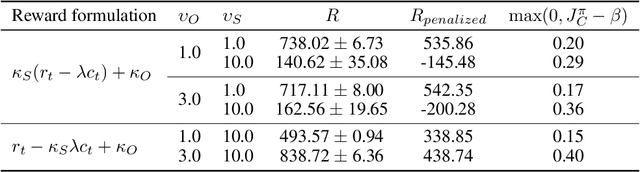
Deploying Reinforcement Learning (RL) agents to solve real-world applications often requires satisfying complex system constraints. Often the constraint thresholds are incorrectly set due to the complex nature of a system or the inability to verify the thresholds offline (e.g, no simulator or reasonable offline evaluation procedure exists). This results in solutions where a task cannot be solved without violating the constraints. However, in many real-world cases, constraint violations are undesirable yet they are not catastrophic, motivating the need for soft-constrained RL approaches. We present two soft-constrained RL approaches that utilize meta-gradients to find a good trade-off between expected return and minimizing constraint violations. We demonstrate the effectiveness of these approaches by showing that they consistently outperform the baselines across four different Mujoco domains.
SCRAM: Spatially Coherent Randomized Attention Maps
May 24, 2019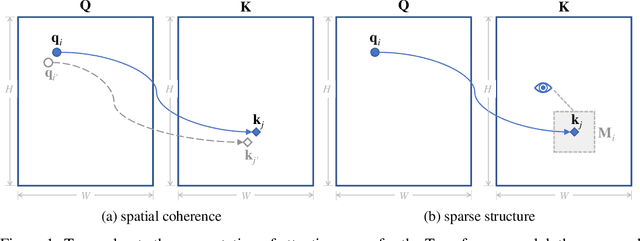
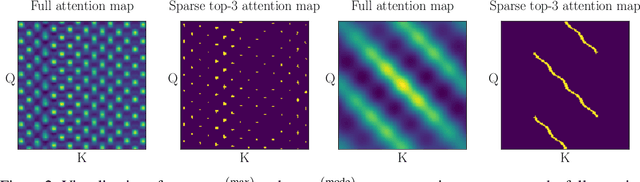
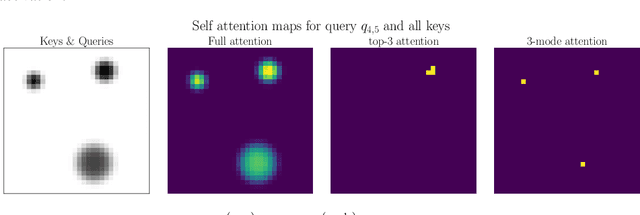
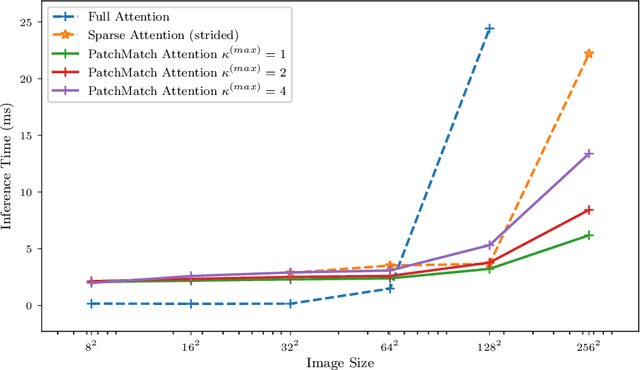
Attention mechanisms and non-local mean operations in general are key ingredients in many state-of-the-art deep learning techniques. In particular, the Transformer model based on multi-head self-attention has recently achieved great success in natural language processing and computer vision. However, the vanilla algorithm computing the Transformer of an image with n pixels has O(n^2) complexity, which is often painfully slow and sometimes prohibitively expensive for large-scale image data. In this paper, we propose a fast randomized algorithm --- SCRAM --- that only requires O(n log(n)) time to produce an image attention map. Such a dramatic acceleration is attributed to our insight that attention maps on real-world images usually exhibit (1) spatial coherence and (2) sparse structure. The central idea of SCRAM is to employ PatchMatch, a randomized correspondence algorithm, to quickly pinpoint the most compatible key (argmax) for each query first, and then exploit that knowledge to design a sparse approximation to non-local mean operations. Using the argmax (mode) to dynamically construct the sparse approximation distinguishes our algorithm from all of the existing sparse approximate methods and makes it very efficient. Moreover, SCRAM is a broadly applicable approximation to any non-local mean layer in contrast to some other sparse approximations that can only approximate self-attention. Our preliminary experimental results suggest that SCRAM is indeed promising for speeding up or scaling up the computation of attention maps in the Transformer.