 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataRater: Meta-Learned Dataset Curation
May 23, 2025The quality of foundation models depends heavily on their training data. Consequently, great efforts have been put into dataset curation. Yet most approaches rely on manual tuning of coarse-grained mixtures of large buckets of data, or filtering by hand-crafted heuristics. An approach that is ultimately more scalable (let alone more satisfying) is to \emph{learn} which data is actually valuable for training. This type of meta-learning could allow more sophisticated, fine-grained, and effective curation. Our proposed \emph{DataRater} is an instance of this idea. It estimates the value of training on any particular data point. This is done by meta-learning using `meta-gradients', with the objective of improving training efficiency on held out data. In extensive experiments across a range of model scales and datasets, we find that using our DataRater to filter data is highly effective, resulting in significantly improved compute efficiency.
Scalable Meta-Learning via Mixed-Mode Differentiation
May 01, 2025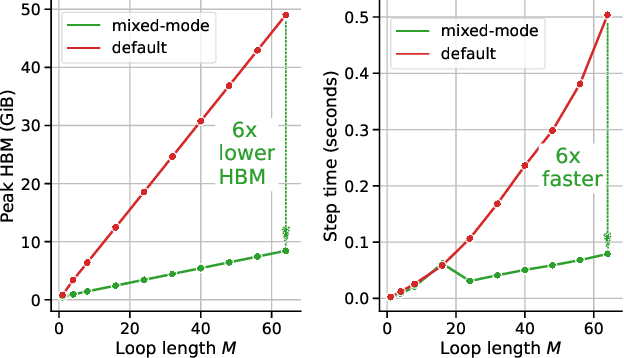
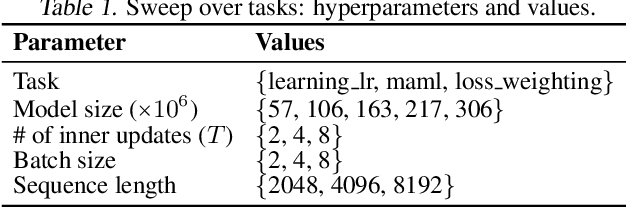
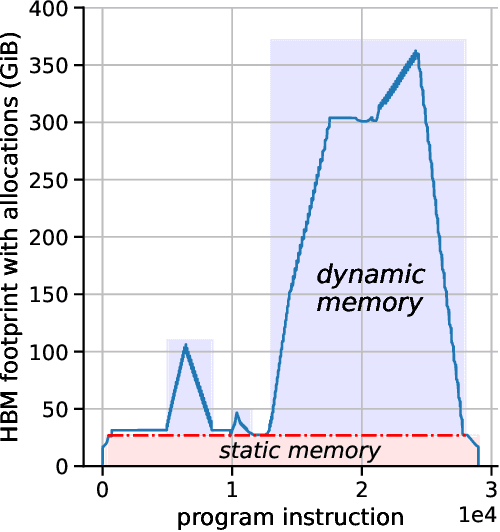
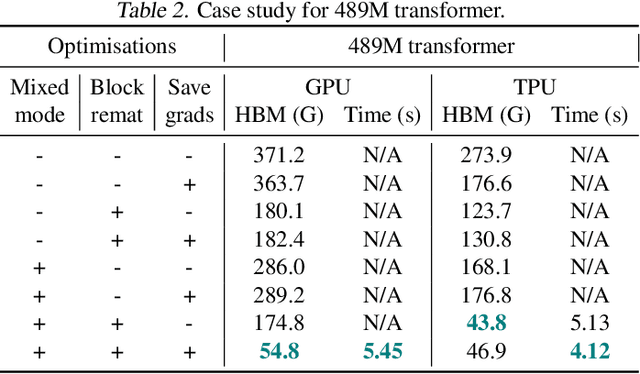
Gradient-based bilevel optimisation is a powerful technique with applications in hyperparameter optimisation, task adaptation, algorithm discovery, meta-learning more broadly, and beyond. It often requires differentiating through the gradient-based optimisation process itself, leading to "gradient-of-a-gradient" calculations with computationally expensive second-order and mixed derivatives. While modern automatic differentiation libraries provide a convenient way to write programs for calculating these derivatives, they oftentimes cannot fully exploit the specific structure of these problems out-of-the-box, leading to suboptimal performance. In this paper, we analyse such cases and propose Mixed-Flow Meta-Gradients, or MixFlow-MG -- a practical algorithm that uses mixed-mode differentiation to construct more efficient and scalable computational graphs yielding over 10x memory and up to 25% wall-clock time improvements over standard implementations in modern meta-learning setups.
Return-based Scaling: Yet Another Normalisation Trick for Deep RL
May 11, 2021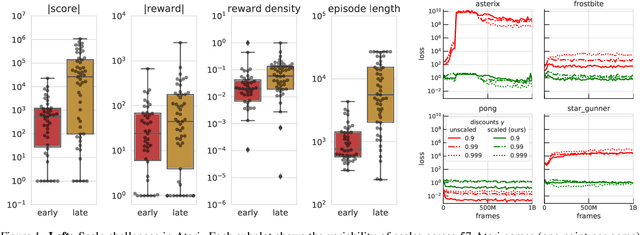
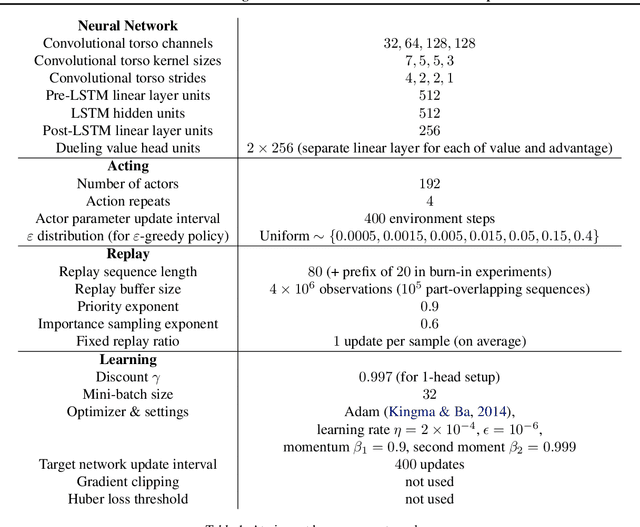
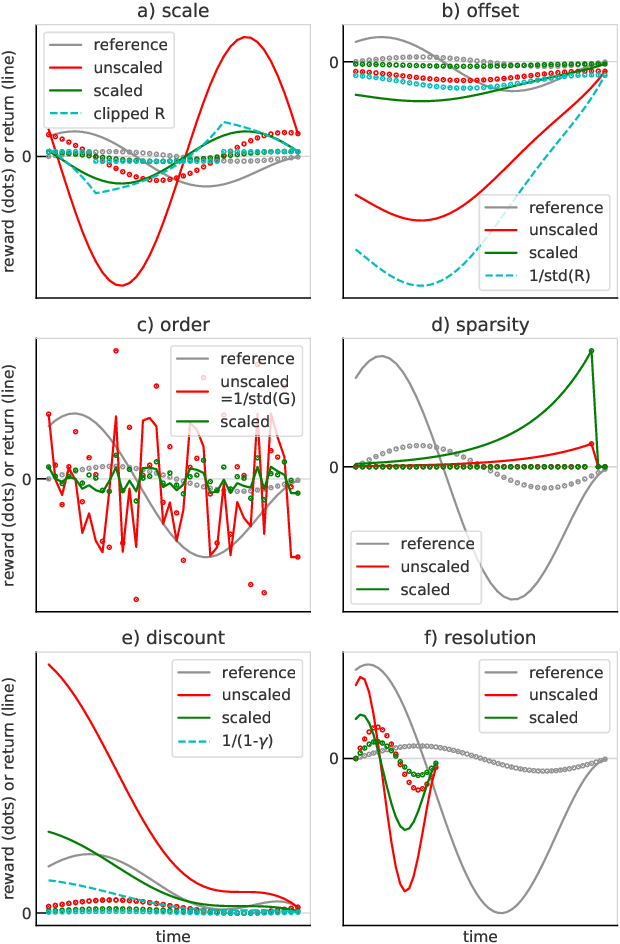
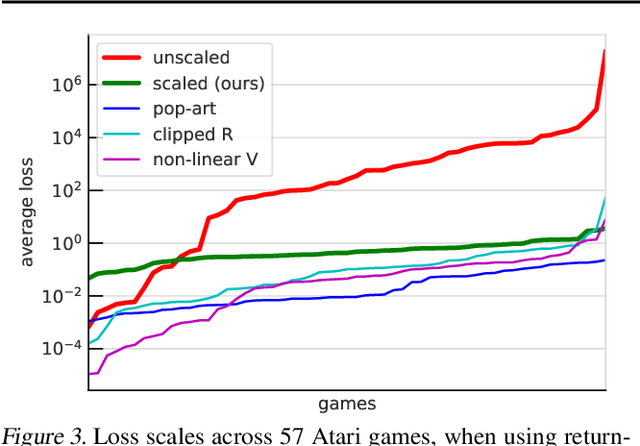
Scaling issues are mundane yet irritating for practitioners of reinforcement learning. Error scales vary across domains, tasks, and stages of learning; sometimes by many orders of magnitude. This can be detrimental to learning speed and stability, create interference between learning tasks, and necessitate substantial tuning. We revisit this topic for agents based on temporal-difference learning, sketch out some desiderata and investigate scenarios where simple fixes fall short. The mechanism we propose requires neither tuning, clipping, nor adaptation. We validate its effectiveness and robustness on the suite of Atari games. Our scaling method turns out to be particularly helpful at mitigating interference, when training a shared neural network on multiple targets that differ in reward scale or discounting.
Podracer architectures for scalable Reinforcement Learning
Apr 13, 2021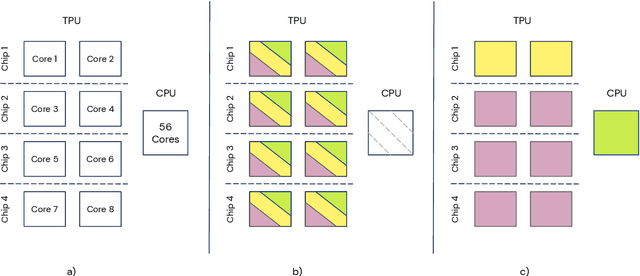
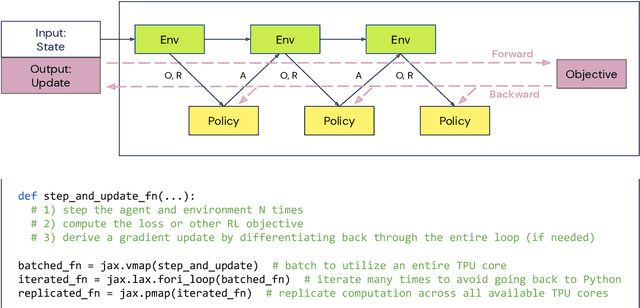
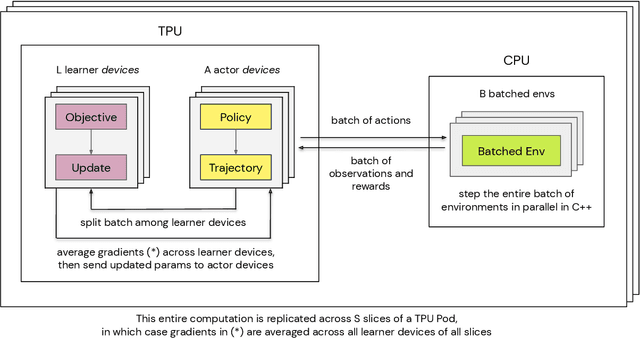
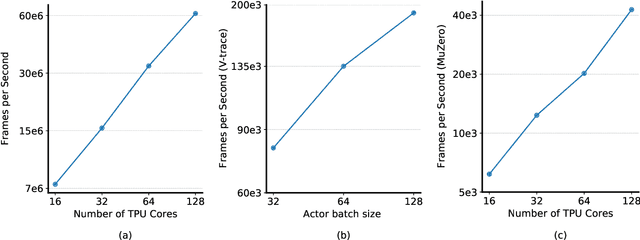
Supporting state-of-the-art AI research requires balancing rapid prototyping, ease of use, and quick iteration, with the ability to deploy experiments at a scale traditionally associated with production systems.Deep learning frameworks such as TensorFlow, PyTorch and JAX allow users to transparently make use of accelerators, such as TPUs and GPUs, to offload the more computationally intensive parts of training and inference in modern deep learning systems. Popular training pipelines that use these frameworks for deep learning typically focus on (un-)supervised learning. How to best train reinforcement learning (RL) agents at scale is still an active research area. In this report we argue that TPUs are particularly well suited for training RL agents in a scalable, efficient and reproducible way. Specifically we describe two architectures designed to make the best use of the resources available on a TPU Pod (a special configuration in a Google data center that features multiple TPU devices connected to each other by extremely low latency communication channels).
Discovery of Options via Meta-Learned Subgoals
Feb 12, 2021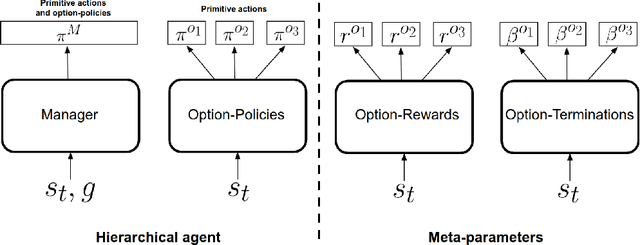
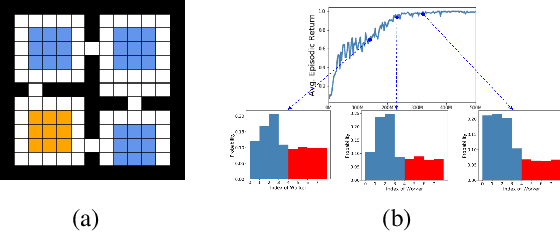
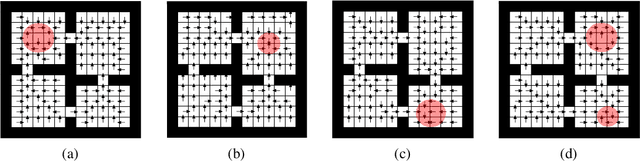
Temporal abstractions in the form of options have been shown to help reinforcement learning (RL) agents learn faster. However, despite prior work on this topic, the problem of discovering options through interaction with an environment remains a challenge. In this paper, we introduce a novel meta-gradient approach for discovering useful options in multi-task RL environments. Our approach is based on a manager-worker decomposition of the RL agent, in which a manager maximises rewards from the environment by learning a task-dependent policy over both a set of task-independent discovered-options and primitive actions. The option-reward and termination functions that define a subgoal for each option are parameterised as neural networks and trained via meta-gradients to maximise their usefulness. Empirical analysis on gridworld and DeepMind Lab tasks show that: (1) our approach can discover meaningful and diverse temporally-extended options in multi-task RL domains, (2) the discovered options are frequently used by the agent while learning to solve the training tasks, and (3) that the discovered options help a randomly initialised manager learn faster in completely new tasks.
Discovering a set of policies for the worst case reward
Feb 08, 2021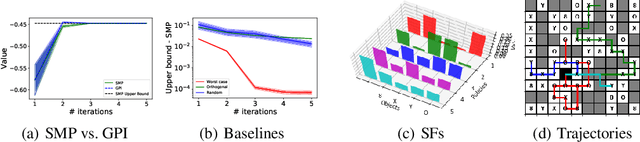
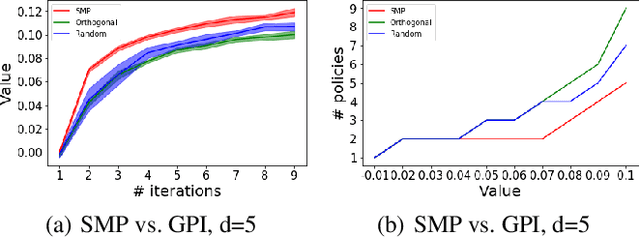
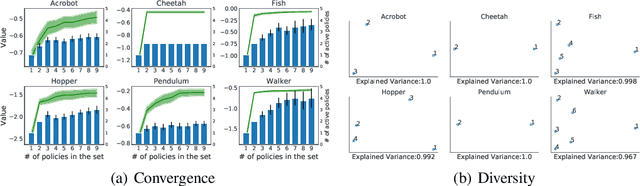

We study the problem of how to construct a set of policies that can be composed together to solve a collection of reinforcement learning tasks. Each task is a different reward function defined as a linear combination of known features. We consider a specific class of policy compositions which we call set improving policies (SIPs): given a set of policies and a set of tasks, a SIP is any composition of the former whose performance is at least as good as that of its constituents across all the tasks. We focus on the most conservative instantiation of SIPs, set-max policies (SMPs), so our analysis extends to any SIP. This includes known policy-composition operators like generalized policy improvement. Our main contribution is a policy iteration algorithm that builds a set of policies in order to maximize the worst-case performance of the resulting SMP on the set of tasks. The algorithm works by successively adding new policies to the set. We show that the worst-case performance of the resulting SMP strictly improves at each iteration, and the algorithm only stops when there does not exist a policy that leads to improved performance. We empirically evaluate our algorithm on a grid world and also on a set of domains from the DeepMind control suite. We confirm our theoretical results regarding the monotonically improving performance of our algorithm. Interestingly, we also show empirically that the sets of policies computed by the algorithm are diverse, leading to different trajectories in the grid world and very distinct locomotion skills in the control suite.
ReSet: Learning Recurrent Dynamic Routing in ResNet-like Neural Networks
Nov 11, 2018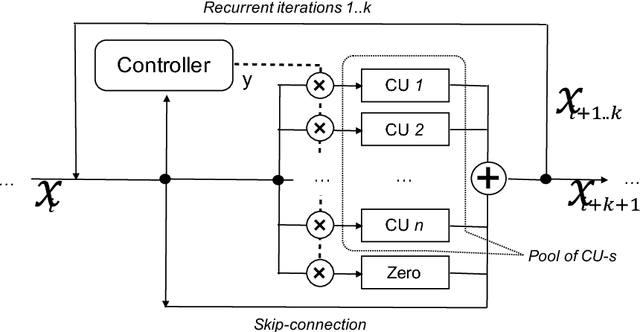
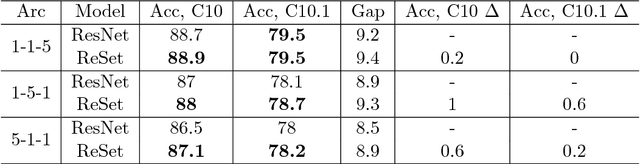
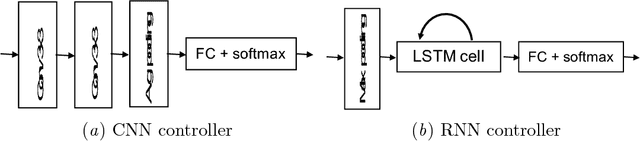
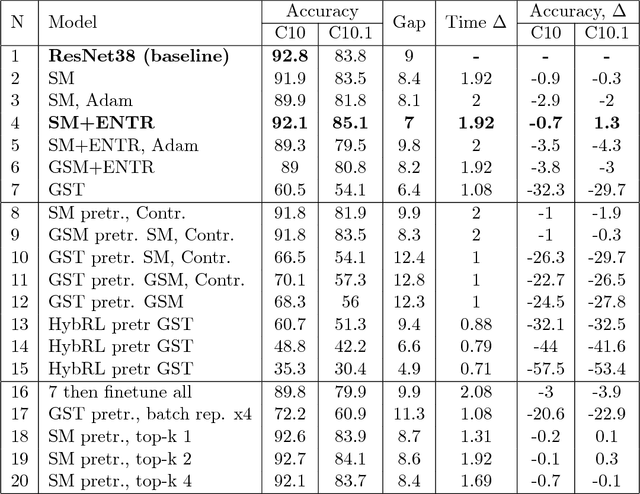
Neural Network is a powerful Machine Learning tool that shows outstanding performance in Computer Vision, Natural Language Processing, and Artificial Intelligence. In particular, recently proposed ResNet architecture and its modifications produce state-of-the-art results in image classification problems. ResNet and most of the previously proposed architectures have a fixed structure and apply the same transformation to all input images. In this work, we develop a ResNet-based model that dynamically selects Computational Units (CU) for each input object from a learned set of transformations. Dynamic selection allows the network to learn a sequence of useful transformations and apply only required units to predict the image label. We compare our model to ResNet-38 architecture and achieve better results than the original ResNet on CIFAR-10.1 test set. While examining the produced paths, we discovered that the network learned different routes for images from different classes and similar routes for similar images.
* Published in Proceedings of The 10th Asian Conference on Machine Learning, http://proceedings.mlr.press/v95/kemaev18a.html