 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugInsert: Learning Robust Visual-Force Policies via Data Augmentation for Object Assembly Tasks
Oct 19, 2024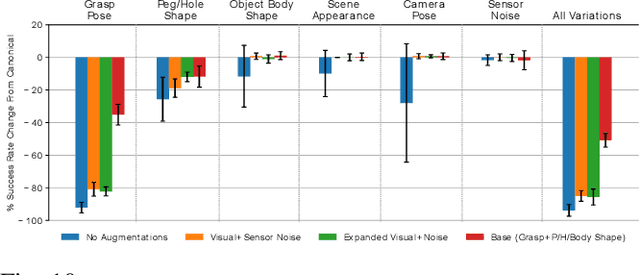
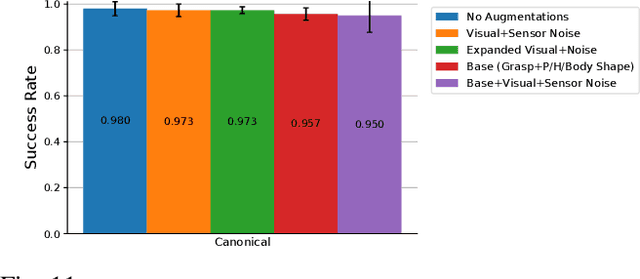
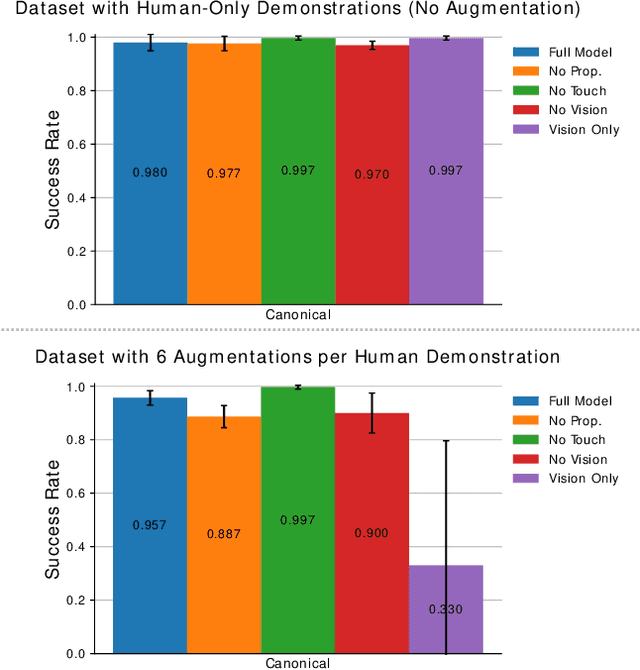

This paper primarily focuses on learning robust visual-force policies in the context of high-precision object assembly tasks. Specifically, we focus on the contact phase of the assembly task where both objects (peg and hole) have made contact and the objective lies in maneuvering the objects to complete the assembly. Moreover, we aim to learn contact-rich manipulation policies with multisensory inputs on limited expert data by expanding human demonstrations via online data augmentation. We develop a simulation environment with a dual-arm robot manipulator to evaluate the effect of augmented expert demonstration data. Our focus is on evaluating the robustness of our model with respect to certain task variations: grasp pose, peg/hole shape, object body shape, scene appearance, camera pose, and force-torque/proprioception noise. We show that our proposed data augmentation method helps in learning a multisensory manipulation policy that is robust to unseen instances of these variations, particularly physical variations such as grasp pose. Additionally, our ablative studies show the significant contribution of force-torque data to the robustness of our model. For additional experiments and qualitative results, we refer to the project webpage at https://bit.ly/47skWXH .
Diversifying AI: Towards Creative Chess with AlphaZero
Aug 29, 2023



In recent years, Artificial Intelligence (AI) systems have surpassed human intelligence in a variety of computational tasks. However, AI systems, like humans, make mistakes, have blind spots, hallucinate, and struggle to generalize to new situations. This work explores whether AI can benefit from creative decision-making mechanisms when pushed to the limits of its computational rationality. In particular, we investigate whether a team of diverse AI systems can outperform a single AI in challenging tasks by generating more ideas as a group and then selecting the best ones. We study this question in the game of chess, the so-called drosophila of AI. We build on AlphaZero (AZ) and extend it to represent a league of agents via a latent-conditioned architecture, which we call AZ_db. We train AZ_db to generate a wider range of ideas using behavioral diversity techniques and select the most promising ones with sub-additive planning. Our experiments suggest that AZ_db plays chess in diverse ways, solves more puzzles as a group and outperforms a more homogeneous team. Notably, AZ_db solves twice as many challenging puzzles as AZ, including the challenging Penrose positions. When playing chess from different openings, we notice that players in AZ_db specialize in different openings, and that selecting a player for each opening using sub-additive planning results in a 50 Elo improvement over AZ. Our findings suggest that diversity bonuses emerge in teams of AI agents, just as they do in teams of humans and that diversity is a valuable asset in solving computationally hard problems.
ReLOAD: Reinforcement Learning with Optimistic Ascent-Descent for Last-Iterate Convergence in Constrained MDPs
Feb 02, 2023
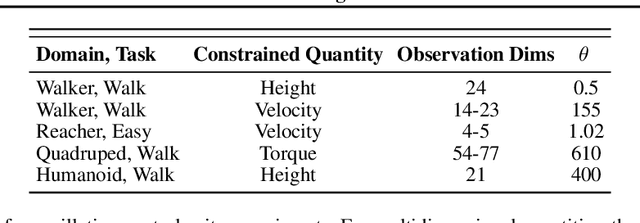
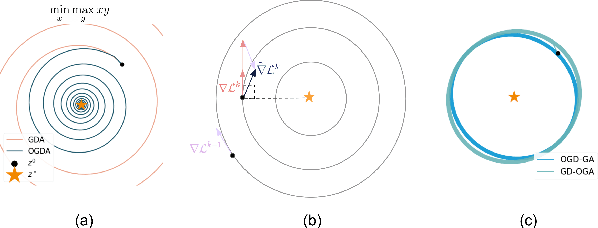
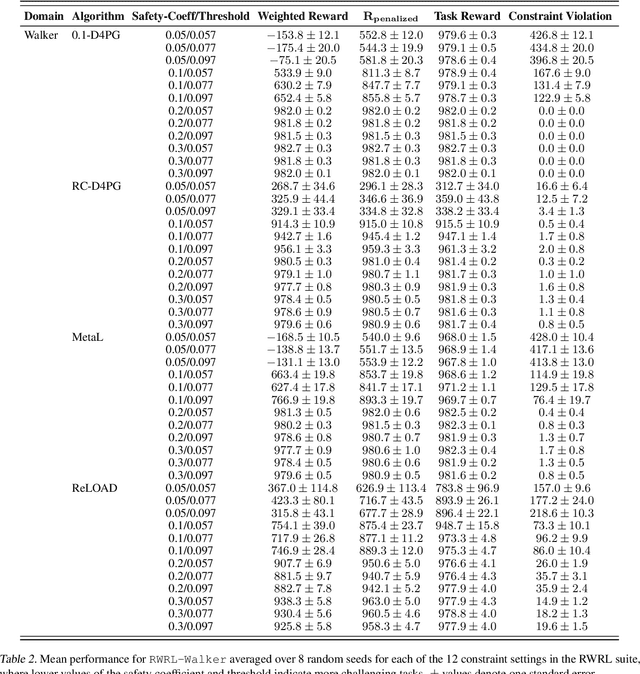
In recent years, Reinforcement Learning (RL) has been applied to real-world problems with increasing success. Such applications often require to put constraints on the agent's behavior. Existing algorithms for constrained RL (CRL) rely on gradient descent-ascent, but this approach comes with a caveat. While these algorithms are guaranteed to converge on average, they do not guarantee last-iterate convergence, i.e., the current policy of the agent may never converge to the optimal solution. In practice, it is often observed that the policy alternates between satisfying the constraints and maximizing the reward, rarely accomplishing both objectives simultaneously. Here, we address this problem by introducing Reinforcement Learning with Optimistic Ascent-Descent (ReLOAD), a principled CRL method with guaranteed last-iterate convergence. We demonstrate its empirical effectiveness on a wide variety of CRL problems including discrete MDPs and continuous control. In the process we establish a benchmark of challenging CRL problems.
GrASP: Gradient-Based Affordance Selection for Planning
Feb 08, 2022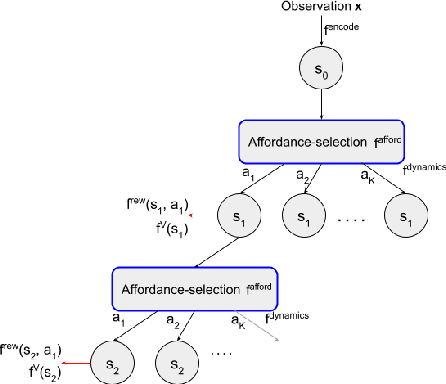
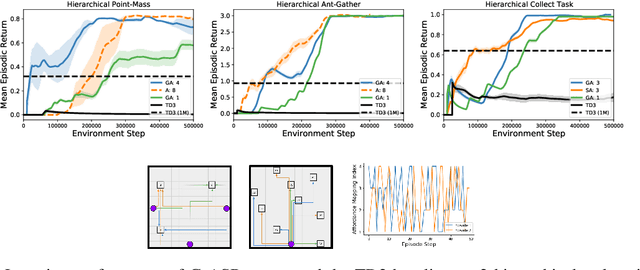
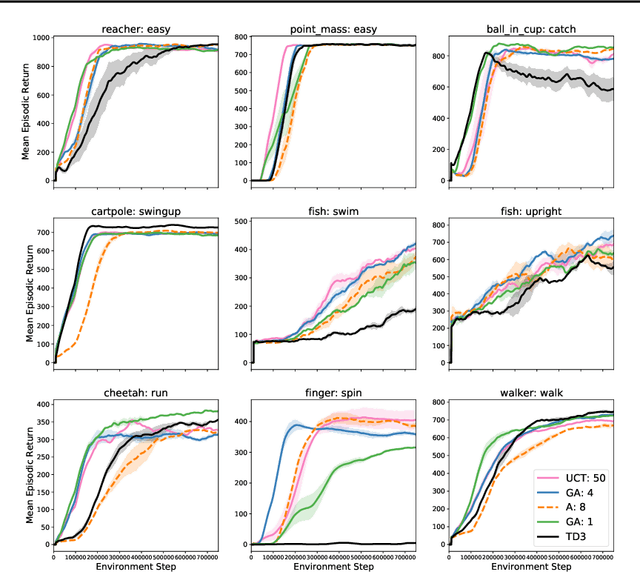
Planning with a learned model is arguably a key component of intelligence. There are several challenges in realizing such a component in large-scale reinforcement learning (RL) problems. One such challenge is dealing effectively with continuous action spaces when using tree-search planning (e.g., it is not feasible to consider every action even at just the root node of the tree). In this paper we present a method for selecting affordances useful for planning -- for learning which small number of actions/options from a continuous space of actions/options to consider in the tree-expansion process during planning. We consider affordances that are goal-and-state-conditional mappings to actions/options as well as unconditional affordances that simply select actions/options available in all states. Our selection method is gradient based: we compute gradients through the planning procedure to update the parameters of the function that represents affordances. Our empirical work shows that it is feasible to learn to select both primitive-action and option affordances, and that simultaneously learning to select affordances and planning with a learned value-equivalent model can outperform model-free RL.
Discovery of Options via Meta-Learned Subgoals
Feb 12, 2021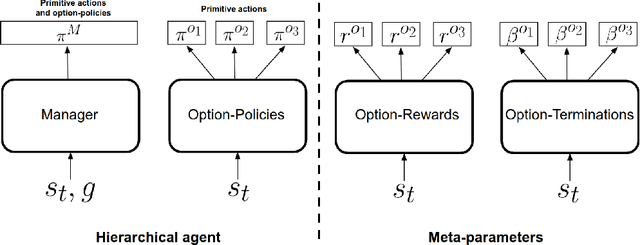
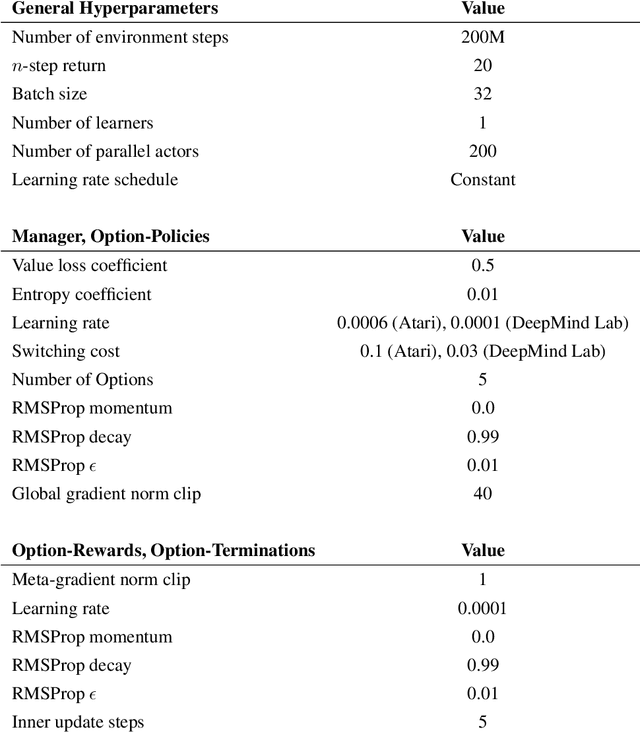
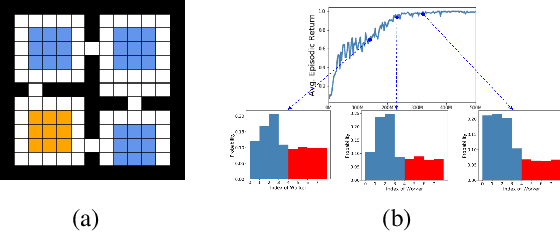
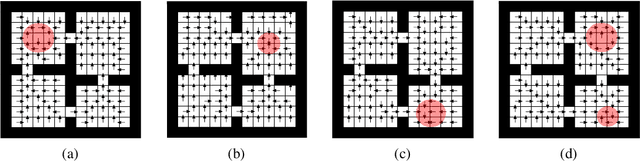
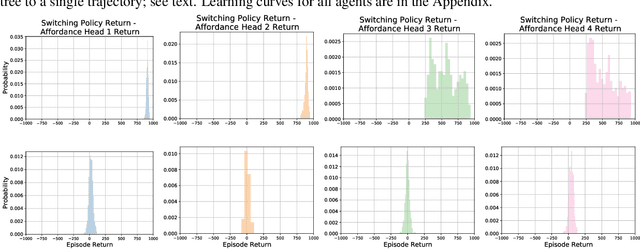
Temporal abstractions in the form of options have been shown to help reinforcement learning (RL) agents learn faster. However, despite prior work on this topic, the problem of discovering options through interaction with an environment remains a challenge. In this paper, we introduce a novel meta-gradient approach for discovering useful options in multi-task RL environments. Our approach is based on a manager-worker decomposition of the RL agent, in which a manager maximises rewards from the environment by learning a task-dependent policy over both a set of task-independent discovered-options and primitive actions. The option-reward and termination functions that define a subgoal for each option are parameterised as neural networks and trained via meta-gradients to maximise their usefulness. Empirical analysis on gridworld and DeepMind Lab tasks show that: (1) our approach can discover meaningful and diverse temporally-extended options in multi-task RL domains, (2) the discovered options are frequently used by the agent while learning to solve the training tasks, and (3) that the discovered options help a randomly initialised manager learn faster in completely new tasks.
Learning State Representations from Random Deep Action-conditional Predictions
Feb 09, 2021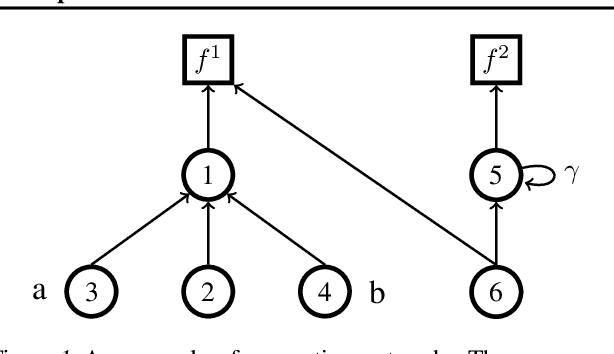
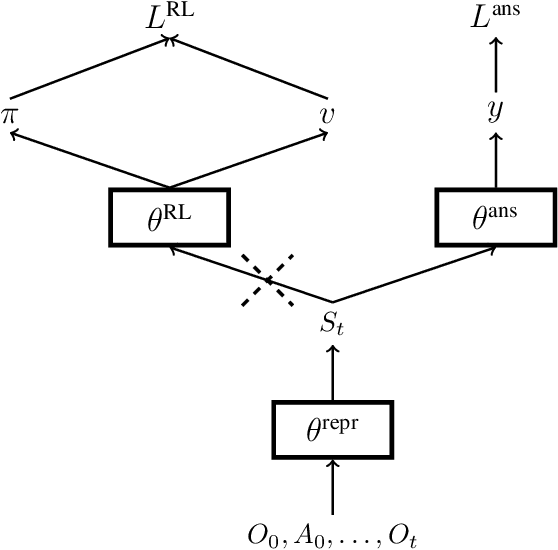
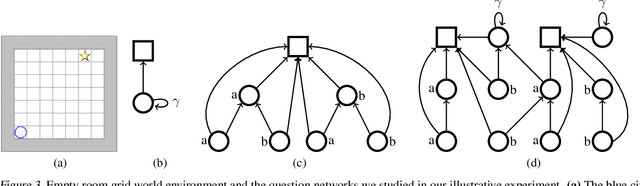
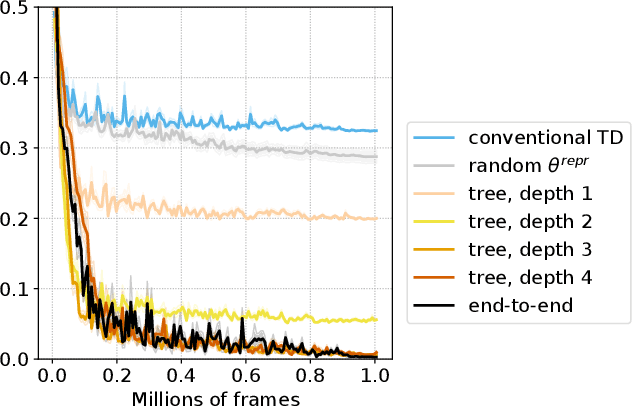
In this work, we study auxiliary prediction tasks defined by temporal-difference networks (TD networks); these networks are a language for expressing a rich space of general value function (GVF) prediction targets that may be learned efficiently with TD. Through analysis in an illustrative domain we show the benefits to learning state representations of exploiting the full richness of TD networks, including both action-conditional predictions and temporally deep predictions. Our main (and perhaps surprising) result is that deep action-conditional TD networks with random structures that create random prediction-questions about random features yield state representations that are competitive with state-of-the-art hand-crafted value prediction and pixel control auxiliary tasks in both Atari games and DeepMind Lab tasks. We also show through stop-gradient experiments that learning the state representations solely via these unsupervised random TD network prediction tasks yield agents that outperform the end-to-end-trained actor-critic baseline.
Learning Retrospective Knowledge with Reverse Reinforcement Learning
Jul 09, 2020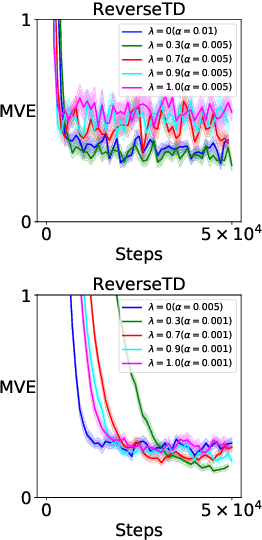
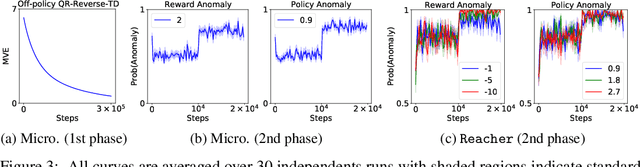

We present a Reverse Reinforcement Learning (Reverse RL) approach for representing retrospective knowledge. General Value Functions (GVFs) have enjoyed great success in representing predictive knowledge, i.e., answering questions about possible future outcomes such as "how much fuel will be consumed in expectation if we drive from A to B?". GVFs, however, cannot answer questions like "how much fuel do we expect a car to have given it is at B at time $t$?". To answer this question, we need to know when that car had a full tank and how that car came to B. Since such questions emphasize the influence of possible past events on the present, we refer to their answers as retrospective knowledge. In this paper, we show how to represent retrospective knowledge with Reverse GVFs, which are trained via Reverse RL. We demonstrate empirically the utility of Reverse GVFs in both representation learning and anomaly detection.
Self-Tuning Deep Reinforcement Learning
Mar 02, 2020
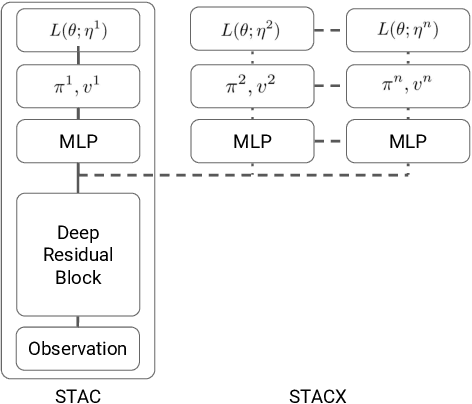
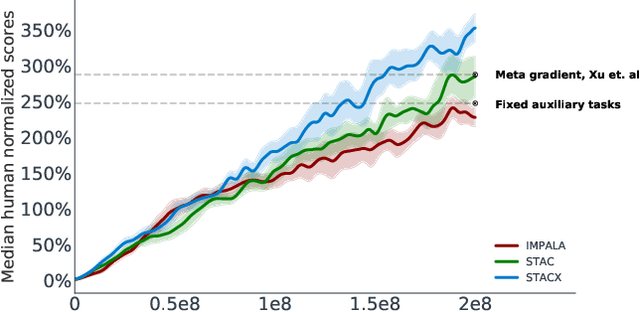
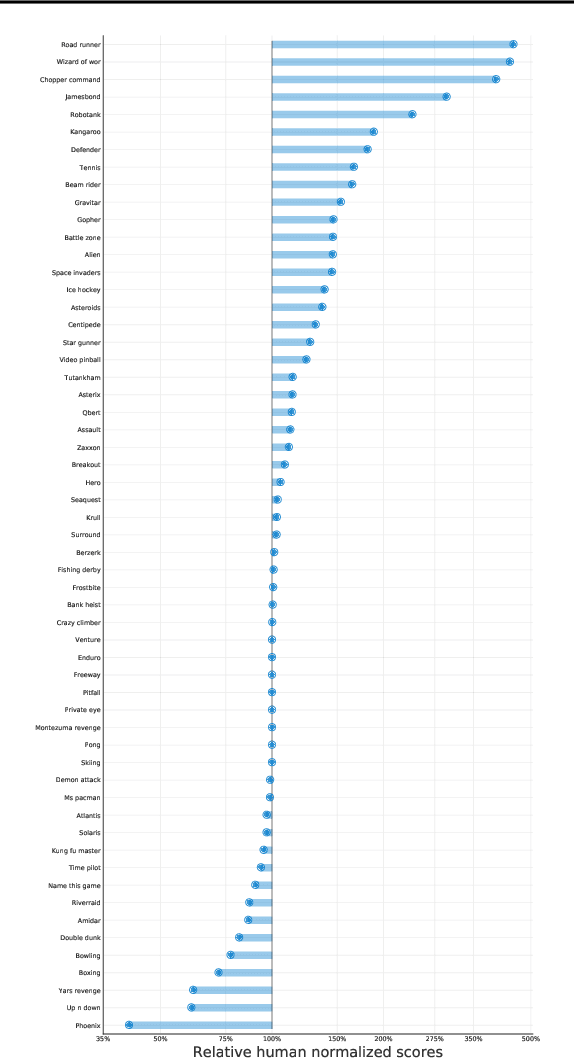
Reinforcement learning (RL) algorithms often require expensive manual or automated hyperparameter searches in order to perform well on a new domain. This need is particularly acute in modern deep RL architectures which often incorporate many modules and multiple loss functions. In this paper, we take a step towards addressing this issue by using metagradients (Xu et al., 2018) to tune these hyperparameters via differentiable cross validation, whilst the agent interacts with and learns from the environment. We present the Self-Tuning Actor Critic (STAC) which uses this process to tune the hyperparameters of the usual loss function of the IMPALA actor critic agent(Espeholt et. al., 2018), to learn the hyperparameters that define auxiliary loss functions, and to balance trade offs in off policy learning by introducing and adapting the hyperparameters of a novel leaky V-trace operator. The method is simple to use, sample efficient and does not require significant increase in compute. Ablative studies show that the overall performance of STAC improves as we adapt more hyperparameters. When applied to 57 games on the Atari 2600 environment over 200 million frames our algorithm improves the median human normalized score of the baseline from 243% to 364%.
How Should an Agent Practice?
Dec 15, 2019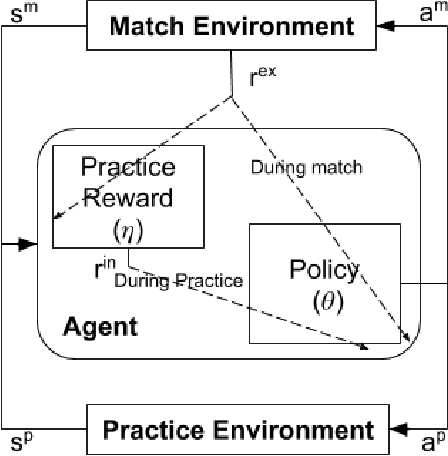
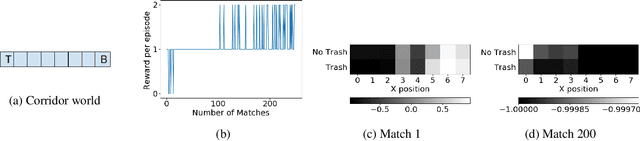
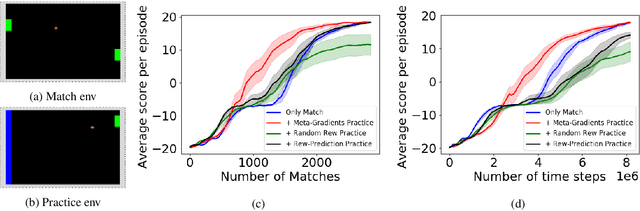
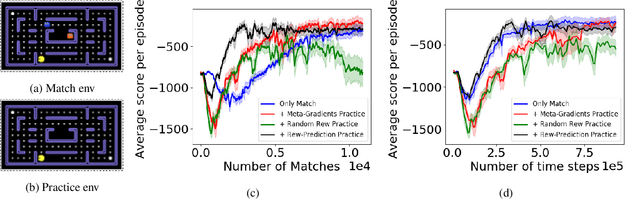
We present a method for learning intrinsic reward functions to drive the learning of an agent during periods of practice in which extrinsic task rewards are not available. During practice, the environment may differ from the one available for training and evaluation with extrinsic rewards. We refer to this setup of alternating periods of practice and objective evaluation as practice-match, drawing an analogy to regimes of skill acquisition common for humans in sports and games. The agent must effectively use periods in the practice environment so that performance improves during matches. In the proposed method the intrinsic practice reward is learned through a meta-gradient approach that adapts the practice reward parameters to reduce the extrinsic match reward loss computed from matches. We illustrate the method on a simple grid world, and evaluate it in two games in which the practice environment differs from match: Pong with practice against a wall without an opponent, and PacMan with practice in a maze without ghosts. The results show gains from learning in practice in addition to match periods over learning in matches only.
Discovery of Useful Questions as Auxiliary Tasks
Sep 10, 2019



Arguably, intelligent agents ought to be able to discover their own questions so that in learning answers for them they learn unanticipated useful knowledge and skills; this departs from the focus in much of machine learning on agents learning answers to externally defined questions. We present a novel method for a reinforcement learning (RL) agent to discover questions formulated as general value functions or GVFs, a fairly rich form of knowledge representation. Specifically, our method uses non-myopic meta-gradients to learn GVF-questions such that learning answers to them, as an auxiliary task, induces useful representations for the main task faced by the RL agent. We demonstrate that auxiliary tasks based on the discovered GVFs are sufficient, on their own, to build representations that support main task learning, and that they do so better than popular hand-designed auxiliary tasks from the literature. Furthermore, we show, in the context of Atari 2600 videogames, how such auxiliary tasks, meta-learned alongside the main task, can improve the data efficiency of an actor-critic agent.