 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrASP: Gradient-Based Affordance Selection for Planning
Feb 08, 2022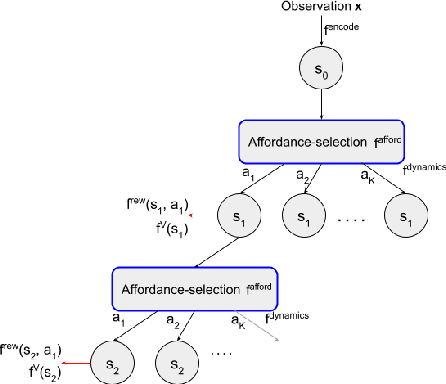
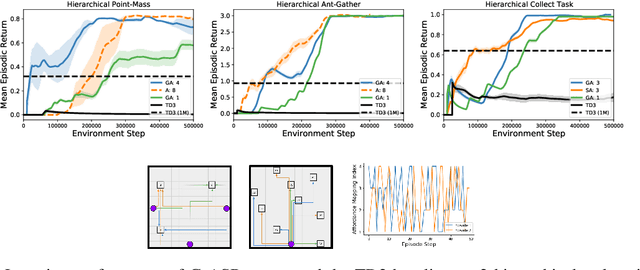
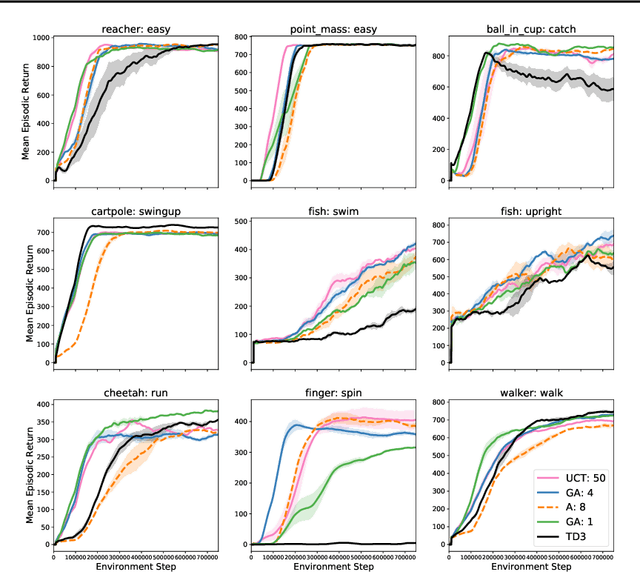
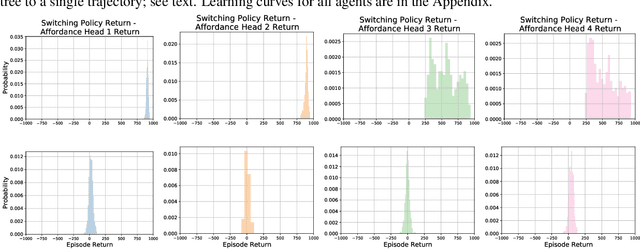
Planning with a learned model is arguably a key component of intelligence. There are several challenges in realizing such a component in large-scale reinforcement learning (RL) problems. One such challenge is dealing effectively with continuous action spaces when using tree-search planning (e.g., it is not feasible to consider every action even at just the root node of the tree). In this paper we present a method for selecting affordances useful for planning -- for learning which small number of actions/options from a continuous space of actions/options to consider in the tree-expansion process during planning. We consider affordances that are goal-and-state-conditional mappings to actions/options as well as unconditional affordances that simply select actions/options available in all states. Our selection method is gradient based: we compute gradients through the planning procedure to update the parameters of the function that represents affordances. Our empirical work shows that it is feasible to learn to select both primitive-action and option affordances, and that simultaneously learning to select affordances and planning with a learned value-equivalent model can outperform model-free RL.
Pairwise Weights for Temporal Credit Assignment
Feb 09, 2021
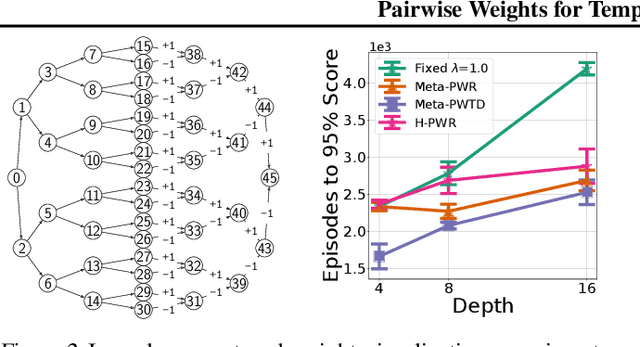
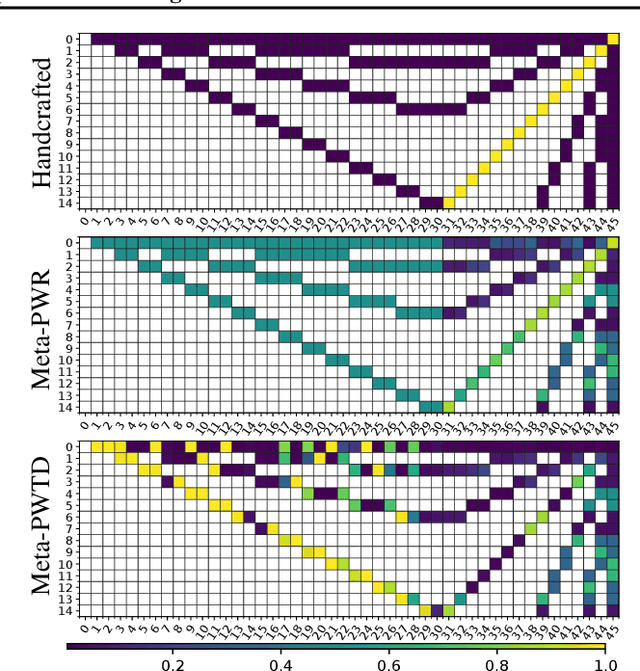

How much credit (or blame) should an action taken in a state get for a future reward? This is the fundamental temporal credit assignment problem in Reinforcement Learning (RL). One of the earliest and still most widely used heuristics is to assign this credit based on a scalar coefficient $\lambda$ (treated as a hyperparameter) raised to the power of the time interval between the state-action and the reward. In this empirical paper, we explore heuristics based on more general pairwise weightings that are functions of the state in which the action was taken, the state at the time of the reward, as well as the time interval between the two. Of course it isn't clear what these pairwise weight functions should be, and because they are too complex to be treated as hyperparameters we develop a metagradient procedure for learning these weight functions during the usual RL training of a policy. Our empirical work shows that it is often possible to learn these pairwise weight functions during learning of the policy to achieve better performance than competing approaches.
Learning State Representations from Random Deep Action-conditional Predictions
Feb 09, 2021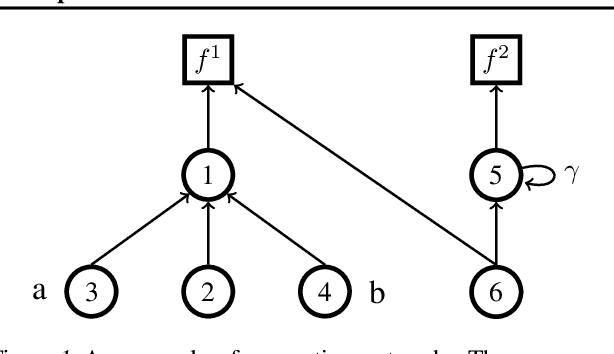
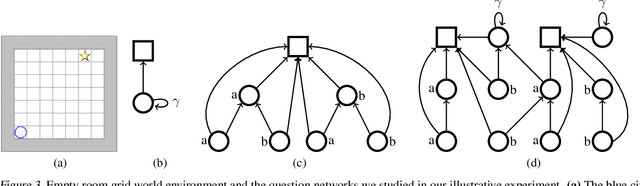
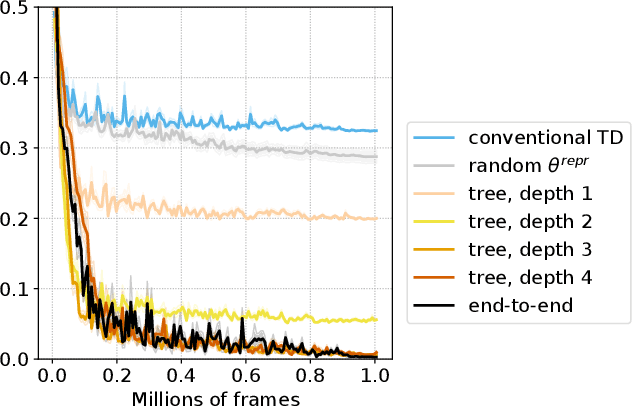
In this work, we study auxiliary prediction tasks defined by temporal-difference networks (TD networks); these networks are a language for expressing a rich space of general value function (GVF) prediction targets that may be learned efficiently with TD. Through analysis in an illustrative domain we show the benefits to learning state representations of exploiting the full richness of TD networks, including both action-conditional predictions and temporally deep predictions. Our main (and perhaps surprising) result is that deep action-conditional TD networks with random structures that create random prediction-questions about random features yield state representations that are competitive with state-of-the-art hand-crafted value prediction and pixel control auxiliary tasks in both Atari games and DeepMind Lab tasks. We also show through stop-gradient experiments that learning the state representations solely via these unsupervised random TD network prediction tasks yield agents that outperform the end-to-end-trained actor-critic baseline.
How Should an Agent Practice?
Dec 15, 2019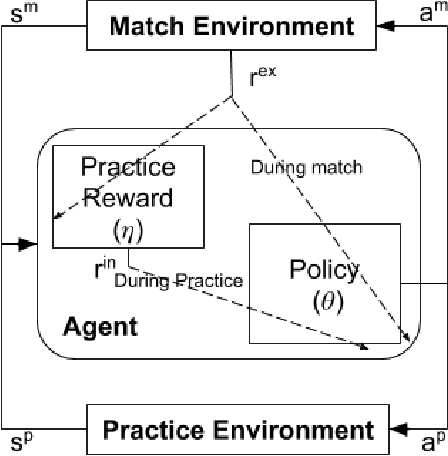
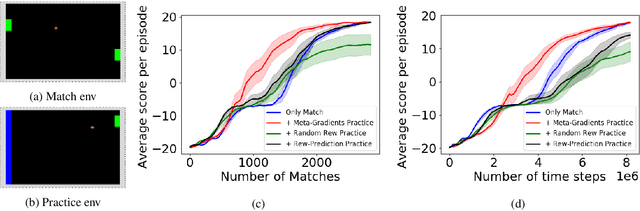
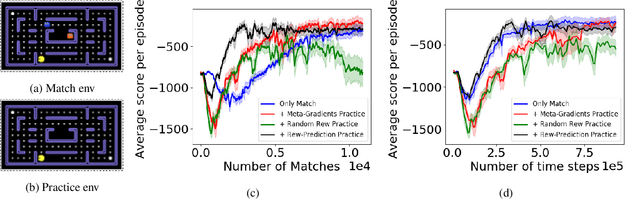
We present a method for learning intrinsic reward functions to drive the learning of an agent during periods of practice in which extrinsic task rewards are not available. During practice, the environment may differ from the one available for training and evaluation with extrinsic rewards. We refer to this setup of alternating periods of practice and objective evaluation as practice-match, drawing an analogy to regimes of skill acquisition common for humans in sports and games. The agent must effectively use periods in the practice environment so that performance improves during matches. In the proposed method the intrinsic practice reward is learned through a meta-gradient approach that adapts the practice reward parameters to reduce the extrinsic match reward loss computed from matches. We illustrate the method on a simple grid world, and evaluate it in two games in which the practice environment differs from match: Pong with practice against a wall without an opponent, and PacMan with practice in a maze without ghosts. The results show gains from learning in practice in addition to match periods over learning in matches only.
Discovery of Useful Questions as Auxiliary Tasks
Sep 10, 2019



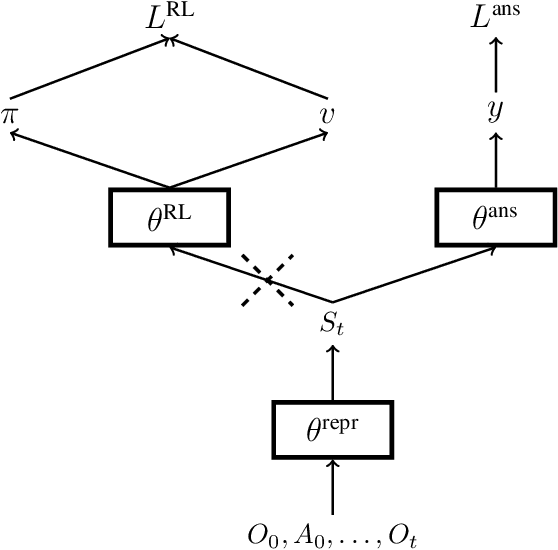
Arguably, intelligent agents ought to be able to discover their own questions so that in learning answers for them they learn unanticipated useful knowledge and skills; this departs from the focus in much of machine learning on agents learning answers to externally defined questions. We present a novel method for a reinforcement learning (RL) agent to discover questions formulated as general value functions or GVFs, a fairly rich form of knowledge representation. Specifically, our method uses non-myopic meta-gradients to learn GVF-questions such that learning answers to them, as an auxiliary task, induces useful representations for the main task faced by the RL agent. We demonstrate that auxiliary tasks based on the discovered GVFs are sufficient, on their own, to build representations that support main task learning, and that they do so better than popular hand-designed auxiliary tasks from the literature. Furthermore, we show, in the context of Atari 2600 videogames, how such auxiliary tasks, meta-learned alongside the main task, can improve the data efficiency of an actor-critic agent.
In silico generation of novel, drug-like chemical matter using the LSTM neural network
Jan 08, 2018
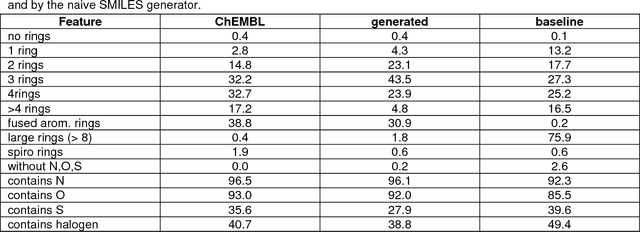
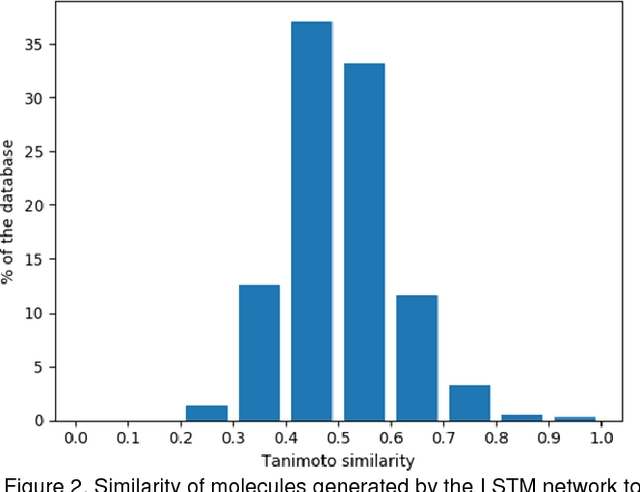
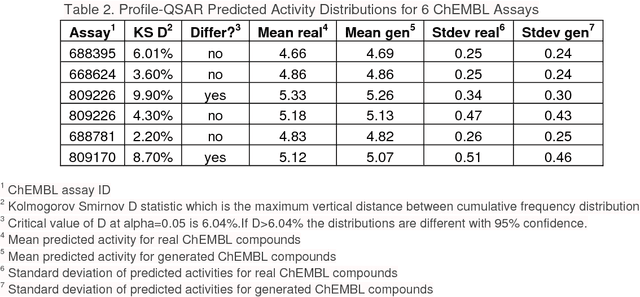
The exploration of novel chemical spaces is one of the most important tasks of cheminformatics when supporting the drug discovery process. Properly designed and trained deep neural networks can provide a viable alternative to brute-force de novo approaches or various other machine-learning techniques for generating novel drug-like molecules. In this article we present a method to generate molecules using a long short-term memory (LSTM) neural network and provide an analysis of the results, including a virtual screening test. Using the network one million drug-like molecules were generated in 2 hours. The molecules are novel, diverse (contain numerous novel chemotypes), have good physicochemical properties and have good synthetic accessibility, even though these qualities were not specific constraints. Although novel, their structural features and functional groups remain closely within the drug-like space defined by the bioactive molecules from ChEMBL. Virtual screening using the profile QSAR approach confirms that the potential of these novel molecules to show bioactivity is comparable to the ChEMBL set from which they were derived. The molecule generator written in Python used in this study is available on request.
Deep Learning for Reward Design to Improve Monte Carlo Tree Search in ATARI Games
Apr 24, 2016
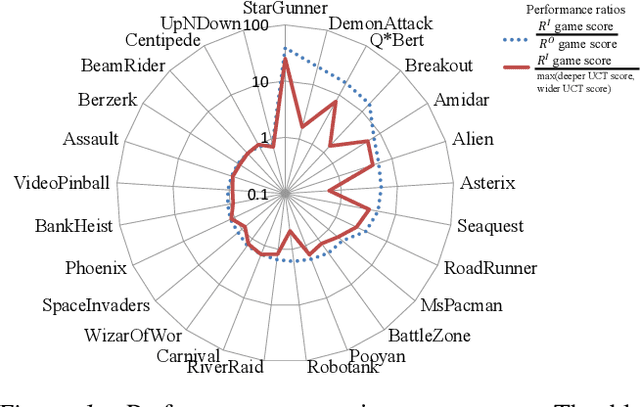


Monte Carlo Tree Search (MCTS) methods have proven powerful in planning for sequential decision-making problems such as Go and video games, but their performance can be poor when the planning depth and sampling trajectories are limited or when the rewards are sparse. We present an adaptation of PGRD (policy-gradient for reward-design) for learning a reward-bonus function to improve UCT (a MCTS algorithm). Unlike previous applications of PGRD in which the space of reward-bonus functions was limited to linear functions of hand-coded state-action-features, we use PGRD with a multi-layer convolutional neural network to automatically learn features from raw perception as well as to adapt the non-linear reward-bonus function parameters. We also adopt a variance-reducing gradient method to improve PGRD's performance. The new method improves UCT's performance on multiple ATARI games compared to UCT without the reward bonus. Combining PGRD and Deep Learning in this way should make adapting rewards for MCTS algorithms far more widely and practically applicable than before.
Action-Conditional Video Prediction using Deep Networks in Atari Games
Dec 22, 2015

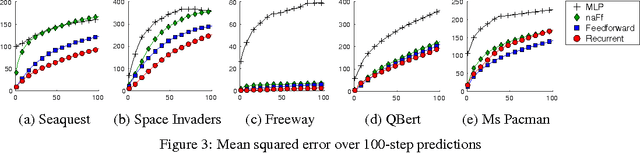
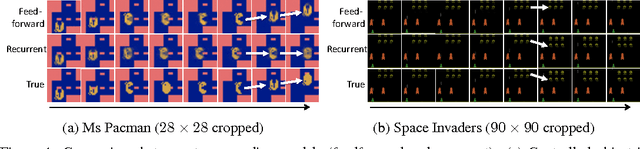
Motivated by vision-based reinforcement learning (RL) problems, in particular Atari games from the recent benchmark Aracade Learning Environment (ALE), we consider spatio-temporal prediction problems where future (image-)frames are dependent on control variables or actions as well as previous frames. While not composed of natural scenes, frames in Atari games are high-dimensional in size, can involve tens of objects with one or more objects being controlled by the actions directly and many other objects being influenced indirectly, can involve entry and departure of objects, and can involve deep partial observability. We propose and evaluate two deep neural network architectures that consist of encoding, action-conditional transformation, and decoding layers based on convolutional neural networks and recurrent neural networks. Experimental results show that the proposed architectures are able to generate visually-realistic frames that are also useful for control over approximately 100-step action-conditional futures in some games. To the best of our knowledge, this paper is the first to make and evaluate long-term predictions on high-dimensional video conditioned by control inputs.