 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Multilingual LLMs Think In English?
Feb 21, 2025Large language models (LLMs) have multilingual capabilities and can solve tasks across various languages. However, we show that current LLMs make key decisions in a representation space closest to English, regardless of their input and output languages. Exploring the internal representations with a logit lens for sentences in French, German, Dutch, and Mandarin, we show that the LLM first emits representations close to English for semantically-loaded words before translating them into the target language. We further show that activation steering in these LLMs is more effective when the steering vectors are computed in English rather than in the language of the inputs and outputs. This suggests that multilingual LLMs perform key reasoning steps in a representation that is heavily shaped by English in a way that is not transparent to system users.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Jun 22, 2024We propose semantic entropy probes (SEPs), a cheap and reliable method for uncertainty quantification in Large Language Models (LLMs). Hallucinations, which are plausible-sounding but factually incorrect and arbitrary model generations, present a major challenge to the practical adoption of LLMs. Recent work by Farquhar et al. (2024) proposes semantic entropy (SE), which can detect hallucinations by estimating uncertainty in the space semantic meaning for a set of model generations. However, the 5-to-10-fold increase in computation cost associated with SE computation hinders practical adoption. To address this, we propose SEPs, which directly approximate SE from the hidden states of a single generation. SEPs are simple to train and do not require sampling multiple model generations at test time, reducing the overhead of semantic uncertainty quantification to almost zero. We show that SEPs retain high performance for hallucination detection and generalize better to out-of-distribution data than previous probing methods that directly predict model accuracy. Our results across models and tasks suggest that model hidden states capture SE, and our ablation studies give further insights into the token positions and model layers for which this is the case.
Explaining Explainability: Understanding Concept Activation Vectors
Apr 04, 2024Recent interpretability methods propose using concept-based explanations to translate the internal representations of deep learning models into a language that humans are familiar with: concepts. This requires understanding which concepts are present in the representation space of a neural network. One popular method for finding concepts is Concept Activation Vectors (CAVs), which are learnt using a probe dataset of concept exemplars. In this work, we investigate three properties of CAVs. CAVs may be: (1) inconsistent between layers, (2) entangled with different concepts, and (3) spatially dependent. Each property provides both challenges and opportunities in interpreting models. We introduce tools designed to detect the presence of these properties, provide insight into how they affect the derived explanations, and provide recommendations to minimise their impact. Understanding these properties can be used to our advantage. For example, we introduce spatially dependent CAVs to test if a model is translation invariant with respect to a specific concept and class. Our experiments are performed on ImageNet and a new synthetic dataset, Elements. Elements is designed to capture a known ground truth relationship between concepts and classes. We release this dataset to facilitate further research in understanding and evaluating interpretability methods.
Bridging the Human-AI Knowledge Gap: Concept Discovery and Transfer in AlphaZero
Oct 25, 2023Artificial Intelligence (AI) systems have made remarkable progress, attaining super-human performance across various domains. This presents us with an opportunity to further human knowledge and improve human expert performance by leveraging the hidden knowledge encoded within these highly performant AI systems. Yet, this knowledge is often hard to extract, and may be hard to understand or learn from. Here, we show that this is possible by proposing a new method that allows us to extract new chess concepts in AlphaZero, an AI system that mastered the game of chess via self-play without human supervision. Our analysis indicates that AlphaZero may encode knowledge that extends beyond the existing human knowledge, but knowledge that is ultimately not beyond human grasp, and can be successfully learned from. In a human study, we show that these concepts are learnable by top human experts, as four top chess grandmasters show improvements in solving the presented concept prototype positions. This marks an important first milestone in advancing the frontier of human knowledge by leveraging AI; a development that could bear profound implications and help us shape how we interact with AI systems across many AI applications.
Diversifying AI: Towards Creative Chess with AlphaZero
Aug 29, 2023



In recent years, Artificial Intelligence (AI) systems have surpassed human intelligence in a variety of computational tasks. However, AI systems, like humans, make mistakes, have blind spots, hallucinate, and struggle to generalize to new situations. This work explores whether AI can benefit from creative decision-making mechanisms when pushed to the limits of its computational rationality. In particular, we investigate whether a team of diverse AI systems can outperform a single AI in challenging tasks by generating more ideas as a group and then selecting the best ones. We study this question in the game of chess, the so-called drosophila of AI. We build on AlphaZero (AZ) and extend it to represent a league of agents via a latent-conditioned architecture, which we call AZ_db. We train AZ_db to generate a wider range of ideas using behavioral diversity techniques and select the most promising ones with sub-additive planning. Our experiments suggest that AZ_db plays chess in diverse ways, solves more puzzles as a group and outperforms a more homogeneous team. Notably, AZ_db solves twice as many challenging puzzles as AZ, including the challenging Penrose positions. When playing chess from different openings, we notice that players in AZ_db specialize in different openings, and that selecting a player for each opening using sub-additive planning results in a 50 Elo improvement over AZ. Our findings suggest that diversity bonuses emerge in teams of AI agents, just as they do in teams of humans and that diversity is a valuable asset in solving computationally hard problems.
DeDUCE: Generating Counterfactual Explanations Efficiently
Nov 29, 2021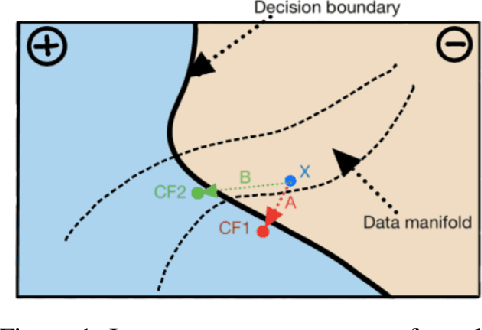


When an image classifier outputs a wrong class label, it can be helpful to see what changes in the image would lead to a correct classification. This is the aim of algorithms generating counterfactual explanations. However, there is no easily scalable method to generate such counterfactuals. We develop a new algorithm providing counterfactual explanations for large image classifiers trained with spectral normalisation at low computational cost. We empirically compare this algorithm against baselines from the literature; our novel algorithm consistently finds counterfactuals that are much closer to the original inputs. At the same time, the realism of these counterfactuals is comparable to the baselines. The code for all experiments is available at https://github.com/benedikthoeltgen/DeDUCE.
Generating Interpretable Counterfactual Explanations By Implicit Minimisation of Epistemic and Aleatoric Uncertainties
Mar 16, 2021
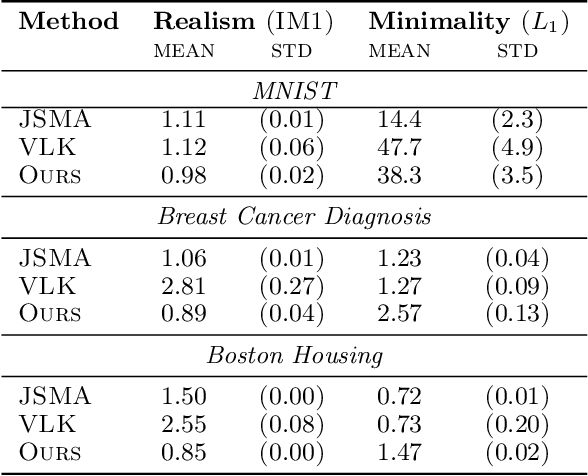


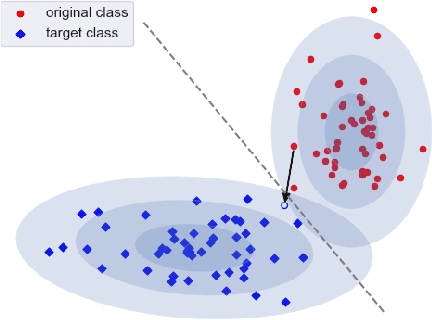
Counterfactual explanations (CEs) are a practical tool for demonstrating why machine learning classifiers make particular decisions. For CEs to be useful, it is important that they are easy for users to interpret. Existing methods for generating interpretable CEs rely on auxiliary generative models, which may not be suitable for complex datasets, and incur engineering overhead. We introduce a simple and fast method for generating interpretable CEs in a white-box setting without an auxiliary model, by using the predictive uncertainty of the classifier. Our experiments show that our proposed algorithm generates more interpretable CEs, according to IM1 scores, than existing methods. Additionally, our approach allows us to estimate the uncertainty of a CE, which may be important in safety-critical applications, such as those in the medical domain.
* 21 pages, 13 Figures
A Bayesian Perspective on Training Speed and Model Selection
Oct 27, 2020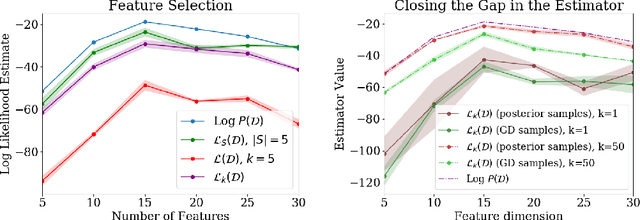
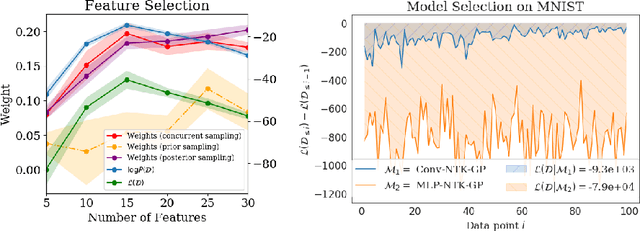
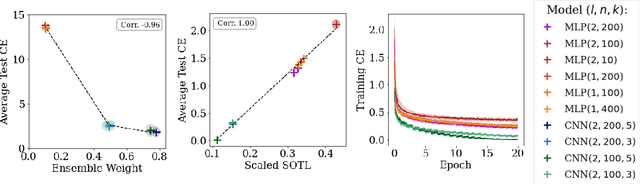
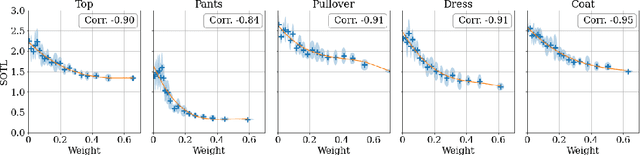
We take a Bayesian perspective to illustrate a connection between training speed and the marginal likelihood in linear models. This provides two major insights: first, that a measure of a model's training speed can be used to estimate its marginal likelihood. Second, that this measure, under certain conditions, predicts the relative weighting of models in linear model combinations trained to minimize a regression loss. We verify our results in model selection tasks for linear models and for the infinite-width limit of deep neural networks. We further provide encouraging empirical evidence that the intuition developed in these settings also holds for deep neural networks trained with stochastic gradient descent. Our results suggest a promising new direction towards explaining why neural networks trained with stochastic gradient descent are biased towards functions that generalize well.
Revisiting the Train Loss: an Efficient Performance Estimator for Neural Architecture Search
Jun 08, 2020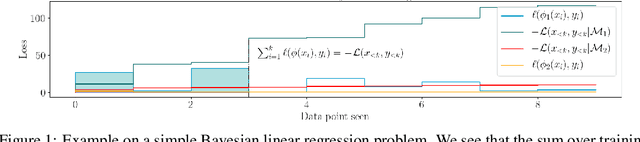
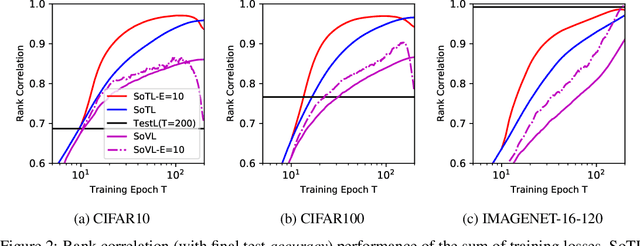
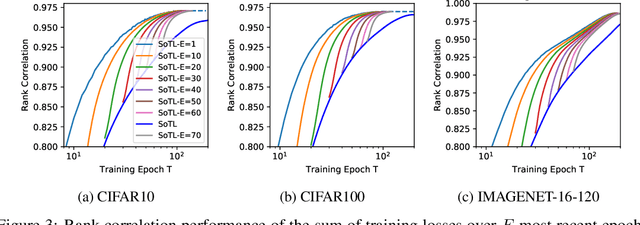
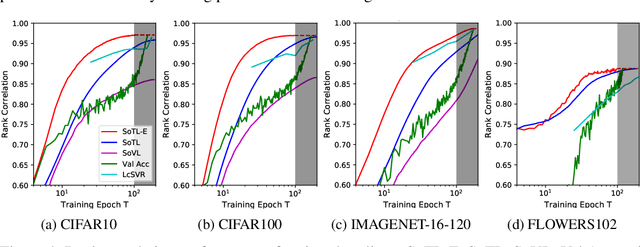
Reliable yet efficient evaluation of generalisation performance of a proposed architecture is crucial to the success of neural architecture search (NAS). Traditional approaches face a variety of limitations: training each architecture to completion is prohibitively expensive, early stopping estimates may correlate poorly with fully trained performance, and model-based estimators require large training sets. Instead, motivated by recent results linking training speed and generalisation with stochastic gradient descent, we propose to estimate the final test performance based on the sum of training losses. Our estimator is inspired by the marginal likelihood, which is used for Bayesian model selection. Our model-free estimator is simple, efficient, and cheap to implement, and does not require hyperparameter-tuning or surrogate training before deployment. We demonstrate empirically that our estimator consistently outperforms other baselines and can achieve a rank correlation of 0.95 with final test accuracy on the NAS-Bench201 dataset within 50 epochs.