 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextCAVs: Debugging vision models using text
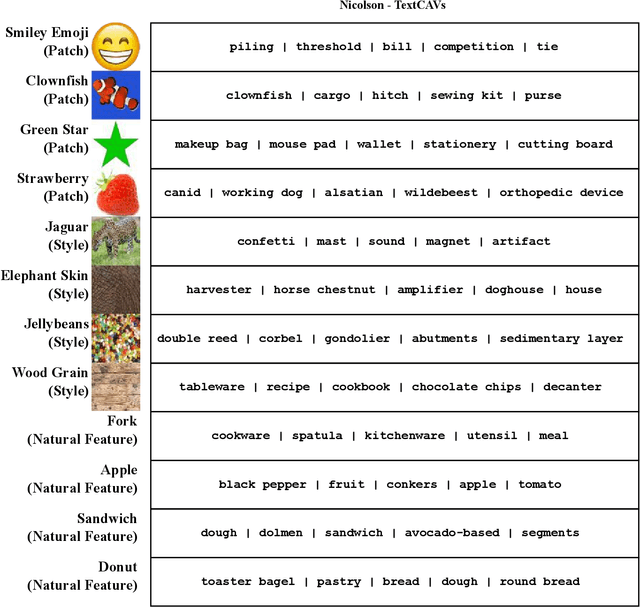
Aug 16, 2024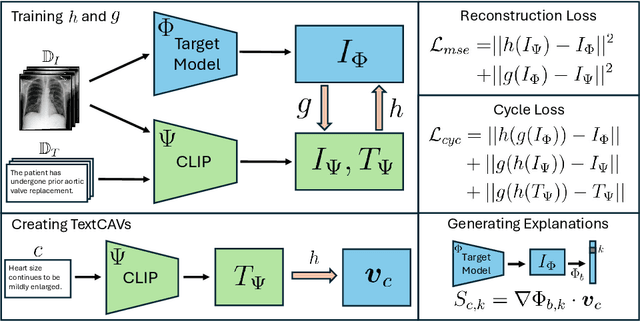
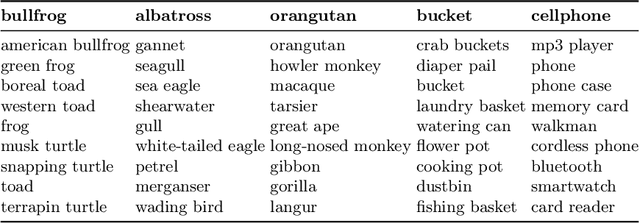
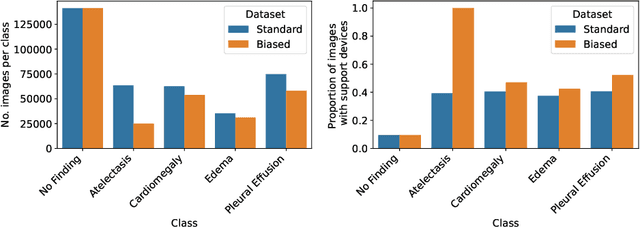
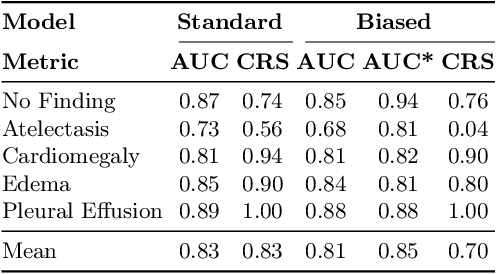
Concept-based interpretability methods are a popular form of explanation for deep learning models which provide explanations in the form of high-level human interpretable concepts. These methods typically find concept activation vectors (CAVs) using a probe dataset of concept examples. This requires labelled data for these concepts -- an expensive task in the medical domain. We introduce TextCAVs: a novel method which creates CAVs using vision-language models such as CLIP, allowing for explanations to be created solely using text descriptions of the concept, as opposed to image exemplars. This reduced cost in testing concepts allows for many concepts to be tested and for users to interact with the model, testing new ideas as they are thought of, rather than a delay caused by image collection and annotation. In early experimental results, we demonstrate that TextCAVs produces reasonable explanations for a chest x-ray dataset (MIMIC-CXR) and natural images (ImageNet), and that these explanations can be used to debug deep learning-based models.
Explaining Explainability: Understanding Concept Activation Vectors
Apr 04, 2024Recent interpretability methods propose using concept-based explanations to translate the internal representations of deep learning models into a language that humans are familiar with: concepts. This requires understanding which concepts are present in the representation space of a neural network. One popular method for finding concepts is Concept Activation Vectors (CAVs), which are learnt using a probe dataset of concept exemplars. In this work, we investigate three properties of CAVs. CAVs may be: (1) inconsistent between layers, (2) entangled with different concepts, and (3) spatially dependent. Each property provides both challenges and opportunities in interpreting models. We introduce tools designed to detect the presence of these properties, provide insight into how they affect the derived explanations, and provide recommendations to minimise their impact. Understanding these properties can be used to our advantage. For example, we introduce spatially dependent CAVs to test if a model is translation invariant with respect to a specific concept and class. Our experiments are performed on ImageNet and a new synthetic dataset, Elements. Elements is designed to capture a known ground truth relationship between concepts and classes. We release this dataset to facilitate further research in understanding and evaluating interpretability methods.
The SaTML '24 CNN Interpretability Competition: New Innovations for Concept-Level Interpretability
Apr 03, 2024


Interpretability techniques are valuable for helping humans understand and oversee AI systems. The SaTML 2024 CNN Interpretability Competition solicited novel methods for studying convolutional neural networks (CNNs) at the ImageNet scale. The objective of the competition was to help human crowd-workers identify trojans in CNNs. This report showcases the methods and results of four featured competition entries. It remains challenging to help humans reliably diagnose trojans via interpretability tools. However, the competition's entries have contributed new techniques and set a new record on the benchmark from Casper et al., 2023.