 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextCAVs: Debugging vision models using text
Paper and Code
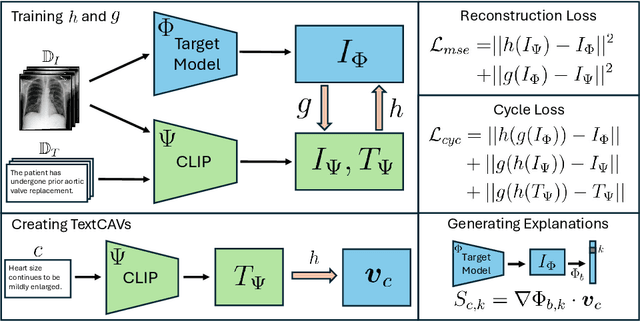
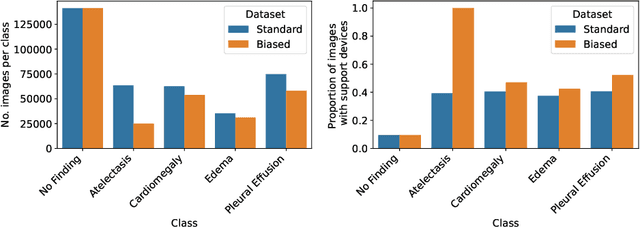
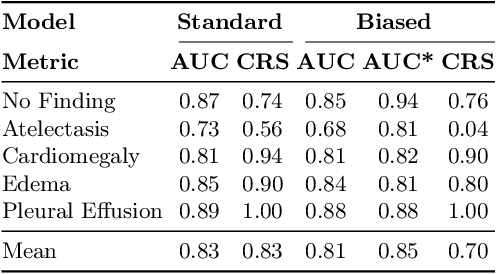
Concept-based interpretability methods are a popular form of explanation for deep learning models which provide explanations in the form of high-level human interpretable concepts. These methods typically find concept activation vectors (CAVs) using a probe dataset of concept examples. This requires labelled data for these concepts -- an expensive task in the medical domain. We introduce TextCAVs: a novel method which creates CAVs using vision-language models such as CLIP, allowing for explanations to be created solely using text descriptions of the concept, as opposed to image exemplars. This reduced cost in testing concepts allows for many concepts to be tested and for users to interact with the model, testing new ideas as they are thought of, rather than a delay caused by image collection and annotation. In early experimental results, we demonstrate that TextCAVs produces reasonable explanations for a chest x-ray dataset (MIMIC-CXR) and natural images (ImageNet), and that these explanations can be used to debug deep learning-based models.