 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Neural Debugger for Python
Mar 10, 2026Training large language models (LLMs) on Python execution traces grounds them in code execution and enables the line-by-line execution prediction of whole Python programs, effectively turning them into neural interpreters (FAIR CodeGen Team et al., 2025). However, developers rarely execute programs step by step; instead, they use debuggers to stop execution at certain breakpoints and step through relevant portions only while inspecting or modifying program variables. Existing neural interpreter approaches lack such interactive control. To address this limitation, we introduce neural debuggers: language models that emulate traditional debuggers, supporting operations such as stepping into, over, or out of functions, as well as setting breakpoints at specific source lines. We show that neural debuggers -- obtained via fine-tuning large LLMs or pre-training smaller models from scratch -- can reliably model both forward execution (predicting future states and outputs) and inverse execution (inferring prior states or inputs) conditioned on debugger actions. Evaluated on CruxEval, our models achieve strong performance on both output and input prediction tasks, demonstrating robust conditional execution modeling. Our work takes first steps towards future agentic coding systems in which neural debuggers serve as a world model for simulated debugging environments, providing execution feedback or enabling agents to interact with real debugging tools. This capability lays the foundation for more powerful code generation, program understanding, and automated debugging.
Scaling Up Active Testing to Large Language Models
Aug 12, 2025Active testing enables label-efficient evaluation of models through careful data acquisition. However, its significant computational costs have previously undermined its use for large models. We show how it can be successfully scaled up to the evaluation of large language models (LLMs). In particular we show that the surrogate model used to guide data acquisition can be constructed cheaply using in-context learning, does not require updating within an active-testing loop, and can be smaller than the target model. We even find we can make good data-acquisition decisions without computing predictions with the target model and further introduce a single-run error estimator to asses how well active testing is working on the fly. We find that our approach is able to more effectively evaluate LLM performance with less data than current standard practices.
Rethinking Aleatoric and Epistemic Uncertainty
Dec 30, 2024

The ideas of aleatoric and epistemic uncertainty are widely used to reason about the probabilistic predictions of machine-learning models. We identify incoherence in existing discussions of these ideas and suggest this stems from the aleatoric-epistemic view being insufficiently expressive to capture all of the distinct quantities that researchers are interested in. To explain and address this we derive a simple delineation of different model-based uncertainties and the data-generating processes associated with training and evaluation. Using this in place of the aleatoric-epistemic view could produce clearer discourse as the field moves forward.
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Jun 22, 2024We propose semantic entropy probes (SEPs), a cheap and reliable method for uncertainty quantification in Large Language Models (LLMs). Hallucinations, which are plausible-sounding but factually incorrect and arbitrary model generations, present a major challenge to the practical adoption of LLMs. Recent work by Farquhar et al. (2024) proposes semantic entropy (SE), which can detect hallucinations by estimating uncertainty in the space semantic meaning for a set of model generations. However, the 5-to-10-fold increase in computation cost associated with SE computation hinders practical adoption. To address this, we propose SEPs, which directly approximate SE from the hidden states of a single generation. SEPs are simple to train and do not require sampling multiple model generations at test time, reducing the overhead of semantic uncertainty quantification to almost zero. We show that SEPs retain high performance for hallucination detection and generalize better to out-of-distribution data than previous probing methods that directly predict model accuracy. Our results across models and tasks suggest that model hidden states capture SE, and our ablation studies give further insights into the token positions and model layers for which this is the case.
Estimating the Hallucination Rate of Generative AI
Jun 11, 2024



This work is about estimating the hallucination rate for in-context learning (ICL) with Generative AI. In ICL, a conditional generative model (CGM) is prompted with a dataset and asked to make a prediction based on that dataset. The Bayesian interpretation of ICL assumes that the CGM is calculating a posterior predictive distribution over an unknown Bayesian model of a latent parameter and data. With this perspective, we define a \textit{hallucination} as a generated prediction that has low-probability under the true latent parameter. We develop a new method that takes an ICL problem -- that is, a CGM, a dataset, and a prediction question -- and estimates the probability that a CGM will generate a hallucination. Our method only requires generating queries and responses from the model and evaluating its response log probability. We empirically evaluate our method on synthetic regression and natural language ICL tasks using large language models.
Kernel Language Entropy: Fine-grained Uncertainty Quantification for LLMs from Semantic Similarities
May 30, 2024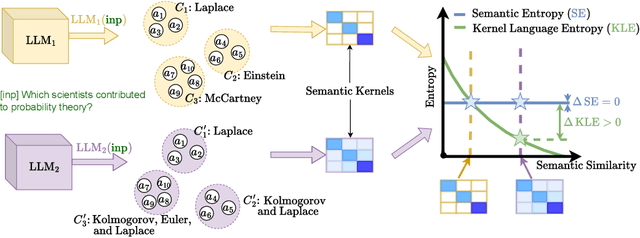

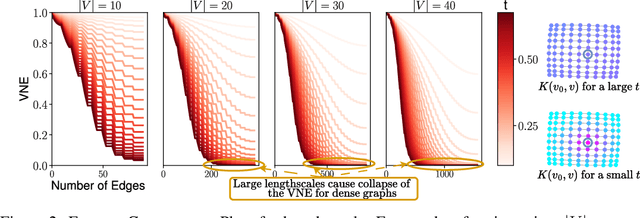
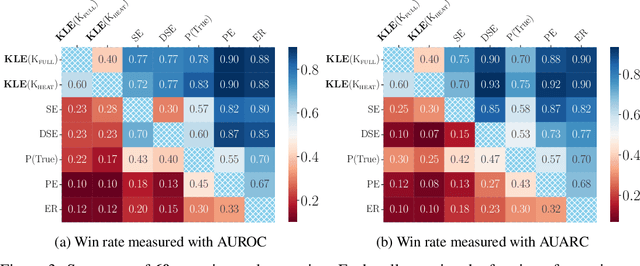
Uncertainty quantification in Large Language Models (LLMs) is crucial for applications where safety and reliability are important. In particular, uncertainty can be used to improve the trustworthiness of LLMs by detecting factually incorrect model responses, commonly called hallucinations. Critically, one should seek to capture the model's semantic uncertainty, i.e., the uncertainty over the meanings of LLM outputs, rather than uncertainty over lexical or syntactic variations that do not affect answer correctness. To address this problem, we propose Kernel Language Entropy (KLE), a novel method for uncertainty estimation in white- and black-box LLMs. KLE defines positive semidefinite unit trace kernels to encode the semantic similarities of LLM outputs and quantifies uncertainty using the von Neumann entropy. It considers pairwise semantic dependencies between answers (or semantic clusters), providing more fine-grained uncertainty estimates than previous methods based on hard clustering of answers. We theoretically prove that KLE generalizes the previous state-of-the-art method called semantic entropy and empirically demonstrate that it improves uncertainty quantification performance across multiple natural language generation datasets and LLM architectures.
In-Context Learning in Large Language Models Learns Label Relationships but Is Not Conventional Learning
Aug 07, 2023



The performance of Large Language Models (LLMs) on downstream tasks often improves significantly when including examples of the input-label relationship in the context. However, there is currently no consensus about how this in-context learning (ICL) ability of LLMs works: for example, while Xie et al. (2021) liken ICL to a general-purpose learning algorithm, Min et al. (2022b) argue ICL does not even learn label relationships from in-context examples. In this paper, we study (1) how labels of in-context examples affect predictions, (2) how label relationships learned during pre-training interact with input-label examples provided in-context, and (3) how ICL aggregates label information across in-context examples. Our findings suggests LLMs usually incorporate information from in-context labels, but that pre-training and in-context label relationships are treated differently, and that the model does not consider all in-context information equally. Our results give insights into understanding and aligning LLM behavior.
Three Towers: Flexible Contrastive Learning with Pretrained Image Models
May 29, 2023



We introduce Three Towers (3T), a flexible method to improve the contrastive learning of vision-language models by incorporating pretrained image classifiers. While contrastive models are usually trained from scratch, LiT (Zhai et al., 2022) has recently shown performance gains from using pretrained classifier embeddings. However, LiT directly replaces the image tower with the frozen embeddings, excluding any potential benefits of contrastively training the image tower. With 3T, we propose a more flexible strategy that allows the image tower to benefit from both pretrained embeddings and contrastive training. To achieve this, we introduce a third tower that contains the frozen pretrained embeddings, and we encourage alignment between this third tower and the main image-text towers. Empirically, 3T consistently improves over LiT and the CLIP-style from-scratch baseline for retrieval tasks. For classification, 3T reliably improves over the from-scratch baseline, and while it underperforms relative to LiT for JFT-pretrained models, it outperforms LiT for ImageNet-21k and Places365 pretraining.
Active Acquisition for Multimodal Temporal Data: A Challenging Decision-Making Task
Nov 09, 2022

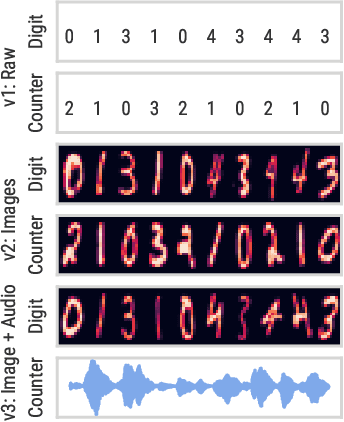

We introduce a challenging decision-making task that we call active acquisition for multimodal temporal data (A2MT). In many real-world scenarios, input features are not readily available at test time and must instead be acquired at significant cost. With A2MT, we aim to learn agents that actively select which modalities of an input to acquire, trading off acquisition cost and predictive performance. A2MT extends a previous task called active feature acquisition to temporal decision making about high-dimensional inputs. Further, we propose a method based on the Perceiver IO architecture to address A2MT in practice. Our agents are able to solve a novel synthetic scenario requiring practically relevant cross-modal reasoning skills. On two large-scale, real-world datasets, Kinetics-700 and AudioSet, our agents successfully learn cost-reactive acquisition behavior. However, an ablation reveals they are unable to learn to learn adaptive acquisition strategies, emphasizing the difficulty of the task even for state-of-the-art models. Applications of A2MT may be impactful in domains like medicine, robotics, or finance, where modalities differ in acquisition cost and informativeness.
Marginal and Joint Cross-Entropies & Predictives for Online Bayesian Inference, Active Learning, and Active Sampling
May 18, 2022
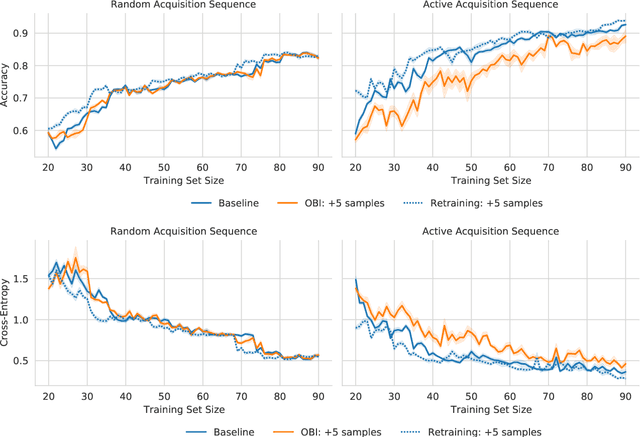
Principled Bayesian deep learning (BDL) does not live up to its potential when we only focus on marginal predictive distributions (marginal predictives). Recent works have highlighted the importance of joint predictives for (Bayesian) sequential decision making from a theoretical and synthetic perspective. We provide additional practical arguments grounded in real-world applications for focusing on joint predictives: we discuss online Bayesian inference, which would allow us to make predictions while taking into account additional data without retraining, and we propose new challenging evaluation settings using active learning and active sampling. These settings are motivated by an examination of marginal and joint predictives, their respective cross-entropies, and their place in offline and online learning. They are more realistic than previously suggested ones, building on work by Wen et al. (2021) and Osband et al. (2022), and focus on evaluating the performance of approximate BNNs in an online supervised setting. Initial experiments, however, raise questions on the feasibility of these ideas in high-dimensional parameter spaces with current BDL inference techniques, and we suggest experiments that might help shed further light on the practicality of current research for these problems. Importantly, our work highlights previously unidentified gaps in current research and the need for better approximate joint predictives.