 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniLingua: A Small Open-Source LLM for European Languages
Dec 15, 2025Large language models are powerful but often limited by high computational cost, privacy concerns, and English-centric training. Recent progress demonstrates that small, efficient models with around one billion parameters can deliver strong results and enable on-device use. This paper introduces MiniLingua, a multilingual open-source LLM of one billion parameters trained from scratch for 13 European languages, designed to balance coverage and instruction-following capabilities. Based on evaluation results, the instruction-tuned version of MiniLingua outperforms EuroLLM, a model with a similar training approach but a larger training budget, on summarization, classification and both open- and closed-book question answering. Moreover, it remains competitive with more advanced state-of-the-art models on open-ended generation tasks. We release model weights, tokenizer and source code used for data processing and model training.
ICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024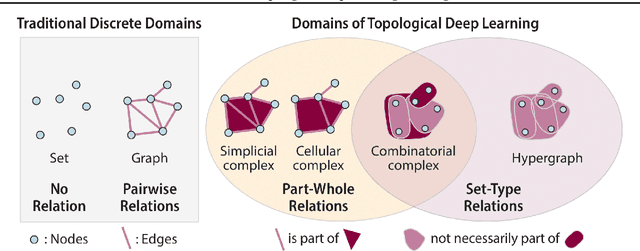
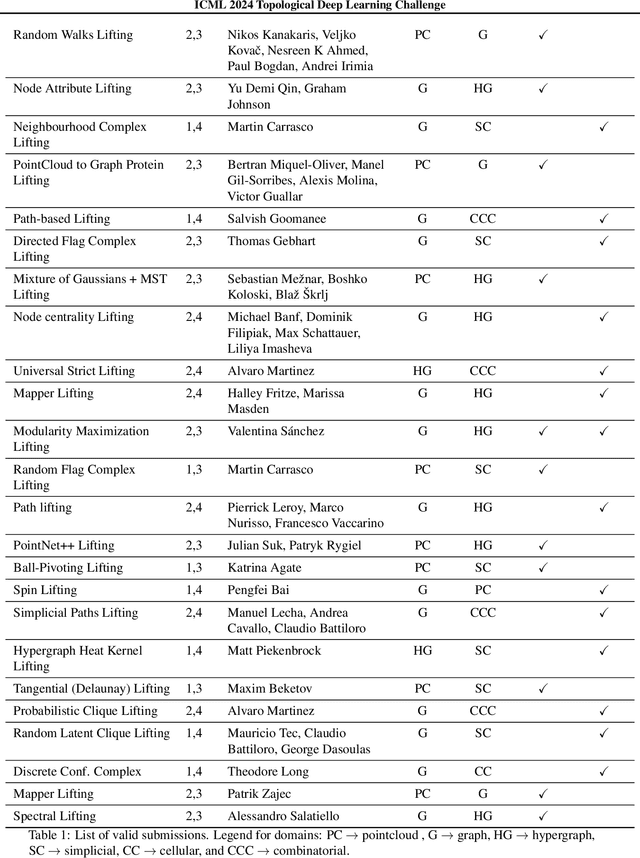
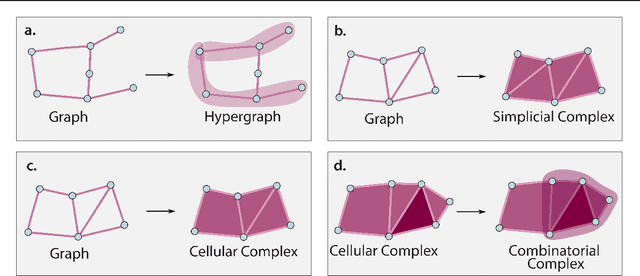
This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.
Kernel Language Entropy: Fine-grained Uncertainty Quantification for LLMs from Semantic Similarities
May 30, 2024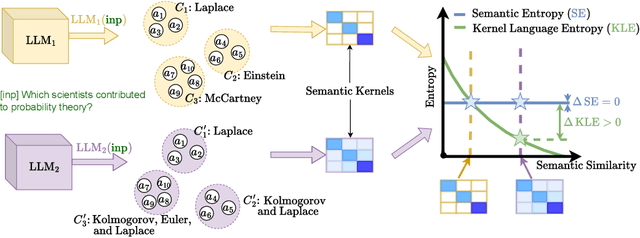

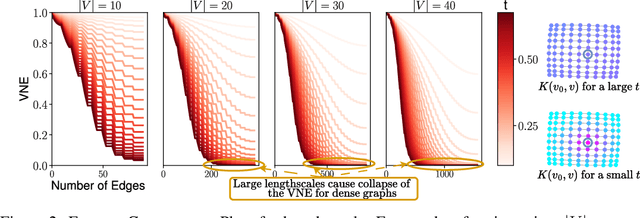
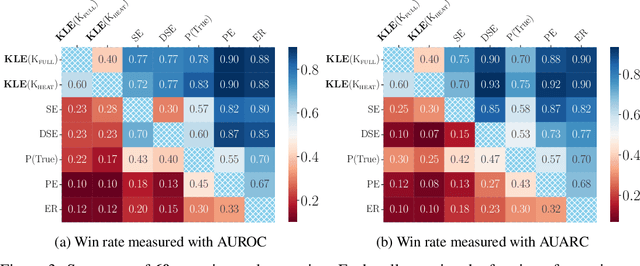
Uncertainty quantification in Large Language Models (LLMs) is crucial for applications where safety and reliability are important. In particular, uncertainty can be used to improve the trustworthiness of LLMs by detecting factually incorrect model responses, commonly called hallucinations. Critically, one should seek to capture the model's semantic uncertainty, i.e., the uncertainty over the meanings of LLM outputs, rather than uncertainty over lexical or syntactic variations that do not affect answer correctness. To address this problem, we propose Kernel Language Entropy (KLE), a novel method for uncertainty estimation in white- and black-box LLMs. KLE defines positive semidefinite unit trace kernels to encode the semantic similarities of LLM outputs and quantifies uncertainty using the von Neumann entropy. It considers pairwise semantic dependencies between answers (or semantic clusters), providing more fine-grained uncertainty estimates than previous methods based on hard clustering of answers. We theoretically prove that KLE generalizes the previous state-of-the-art method called semantic entropy and empirically demonstrate that it improves uncertainty quantification performance across multiple natural language generation datasets and LLM architectures.
TopoX: A Suite of Python Packages for Machine Learning on Topological Domains
Feb 07, 2024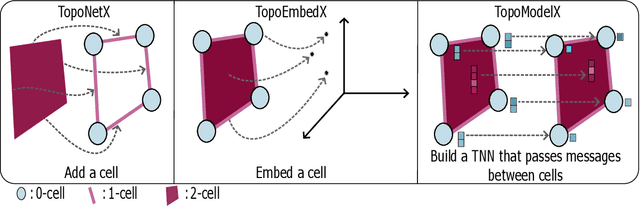
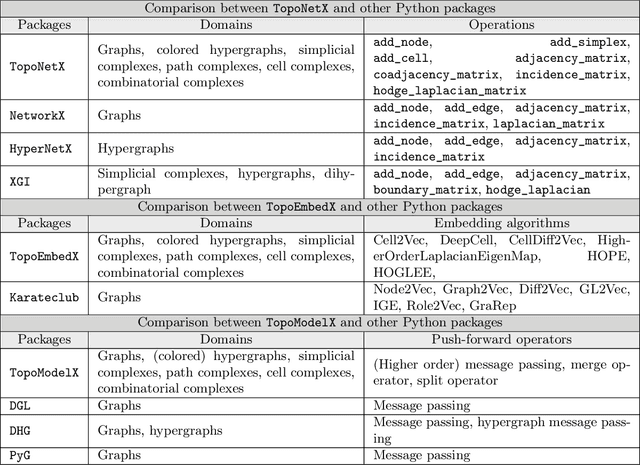
We introduce topox, a Python software suite that provides reliable and user-friendly building blocks for computing and machine learning on topological domains that extend graphs: hypergraphs, simplicial, cellular, path and combinatorial complexes. topox consists of three packages: toponetx facilitates constructing and computing on these domains, including working with nodes, edges and higher-order cells; topoembedx provides methods to embed topological domains into vector spaces, akin to popular graph-based embedding algorithms such as node2vec; topomodelx is built on top of PyTorch and offers a comprehensive toolbox of higher-order message passing functions for neural networks on topological domains. The extensively documented and unit-tested source code of topox is available under MIT license at https://github.com/pyt-team.
Thin and Deep Gaussian Processes
Oct 17, 2023Gaussian processes (GPs) can provide a principled approach to uncertainty quantification with easy-to-interpret kernel hyperparameters, such as the lengthscale, which controls the correlation distance of function values. However, selecting an appropriate kernel can be challenging. Deep GPs avoid manual kernel engineering by successively parameterizing kernels with GP layers, allowing them to learn low-dimensional embeddings of the inputs that explain the output data. Following the architecture of deep neural networks, the most common deep GPs warp the input space layer-by-layer but lose all the interpretability of shallow GPs. An alternative construction is to successively parameterize the lengthscale of a kernel, improving the interpretability but ultimately giving away the notion of learning lower-dimensional embeddings. Unfortunately, both methods are susceptible to particular pathologies which may hinder fitting and limit their interpretability. This work proposes a novel synthesis of both previous approaches: Thin and Deep GP (TDGP). Each TDGP layer defines locally linear transformations of the original input data maintaining the concept of latent embeddings while also retaining the interpretation of lengthscales of a kernel. Moreover, unlike the prior solutions, TDGP induces non-pathological manifolds that admit learning lower-dimensional representations. We show with theoretical and experimental results that i) TDGP is, unlike previous models, tailored to specifically discover lower-dimensional manifolds in the input data, ii) TDGP behaves well when increasing the number of layers, and iii) TDGP performs well in standard benchmark datasets.
ICML 2023 Topological Deep Learning Challenge : Design and Results
Oct 02, 2023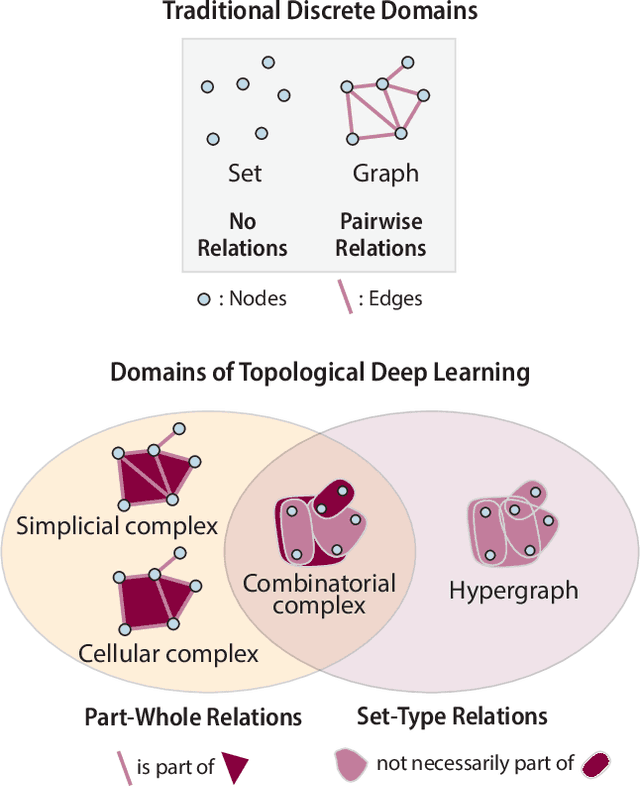
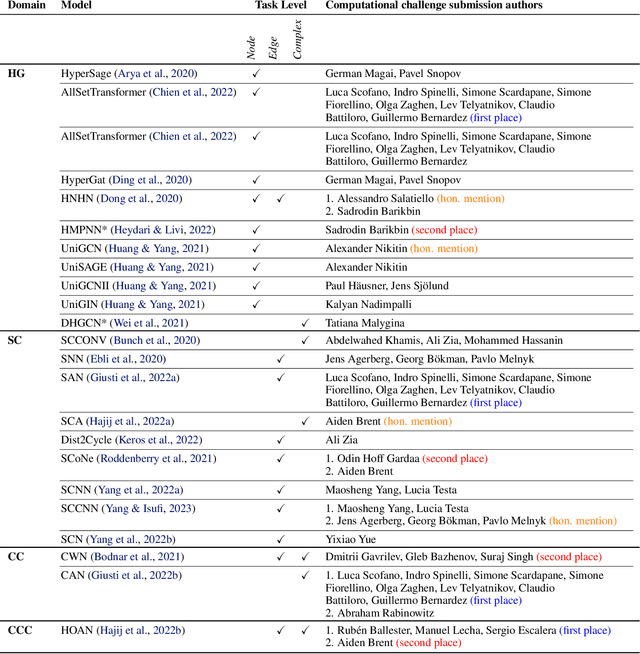
This paper presents the computational challenge on topological deep learning that was hosted within the ICML 2023 Workshop on Topology and Geometry in Machine Learning. The competition asked participants to provide open-source implementations of topological neural networks from the literature by contributing to the python packages TopoNetX (data processing) and TopoModelX (deep learning). The challenge attracted twenty-eight qualifying submissions in its two-month duration. This paper describes the design of the challenge and summarizes its main findings.
TSGM: A Flexible Framework for Generative Modeling of Synthetic Time Series
May 19, 2023Temporally indexed data are essential in a wide range of fields and of interest to machine learning researchers. Time series data, however, are often scarce or highly sensitive, which precludes the sharing of data between researchers and industrial organizations and the application of existing and new data-intensive ML methods. A possible solution to this bottleneck is to generate synthetic data. In this work, we introduce Time Series Generative Modeling (TSGM), an open-source framework for the generative modeling of synthetic time series. TSGM includes a broad repertoire of machine learning methods: generative models, probabilistic, and simulator-based approaches. The framework enables users to evaluate the quality of the produced data from different angles: similarity, downstream effectiveness, predictive consistency, diversity, and privacy. The framework is extensible, which allows researchers to rapidly implement their own methods and compare them in a shareable environment. TSGM was tested on open datasets and in production and proved to be beneficial in both cases. Additionally to the library, the project allows users to employ command line interfaces for synthetic data generation which lowers the entry threshold for those without a programming background.
Human-in-the-Loop Large-Scale Predictive Maintenance of Workstations
Jun 23, 2022
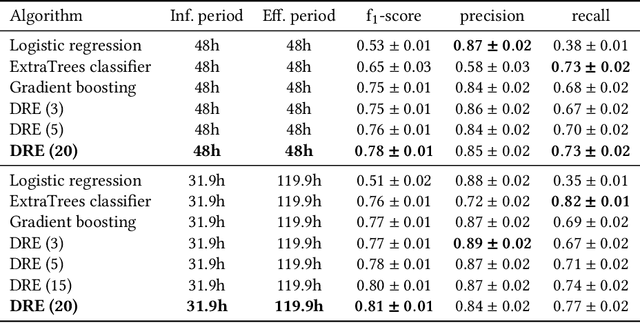
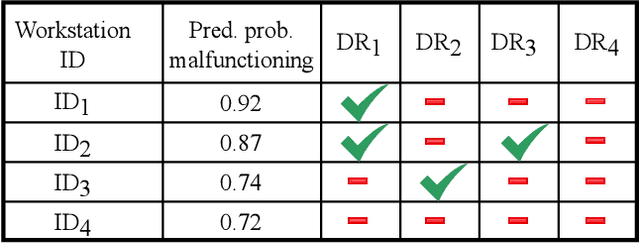

Predictive maintenance (PdM) is the task of scheduling maintenance operations based on a statistical analysis of the system's condition. We propose a human-in-the-loop PdM approach in which a machine learning system predicts future problems in sets of workstations (computers, laptops, and servers). Our system interacts with domain experts to improve predictions and elicit their knowledge. In our approach, domain experts are included in the loop not only as providers of correct labels, as in traditional active learning, but as a source of explicit decision rule feedback. The system is automated and designed to be easily extended to novel domains, such as maintaining workstations of several organizations. In addition, we develop a simulator for reproducible experiments in a controlled environment and deploy the system in a large-scale case of real-life workstations PdM with thousands of workstations for dozens of companies.
Non-separable Spatio-temporal Graph Kernels via SPDEs
Nov 16, 2021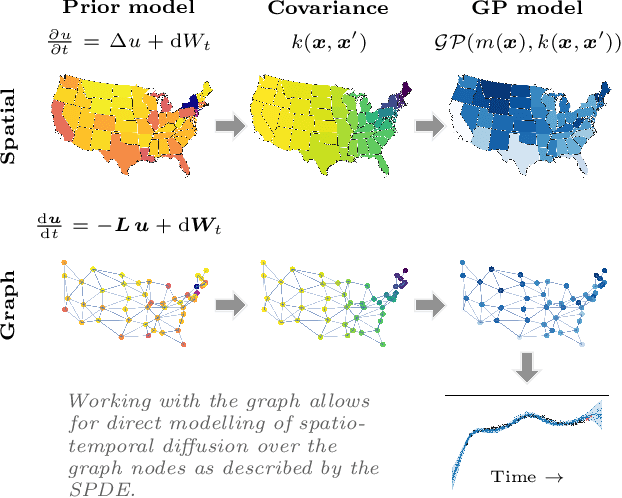



Gaussian processes (GPs) provide a principled and direct approach for inference and learning on graphs. However, the lack of justified graph kernels for spatio-temporal modelling has held back their use in graph problems. We leverage an explicit link between stochastic partial differential equations (SPDEs) and GPs on graphs, and derive non-separable spatio-temporal graph kernels that capture interaction across space and time. We formulate the graph kernels for the stochastic heat equation and wave equation. We show that by providing novel tools for spatio-temporal GP modelling on graphs, we outperform pre-existing graph kernels in real-world applications that feature diffusion, oscillation, and other complicated interactions.
Decision Rule Elicitation for Domain Adaptation
Feb 23, 2021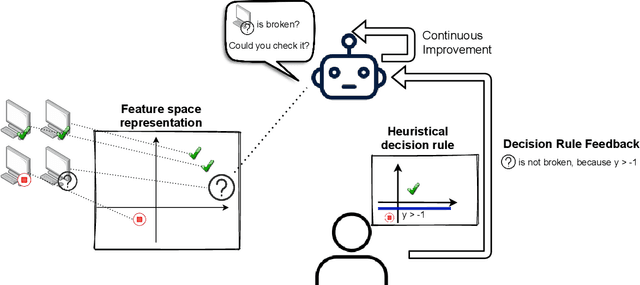

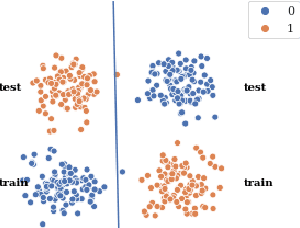
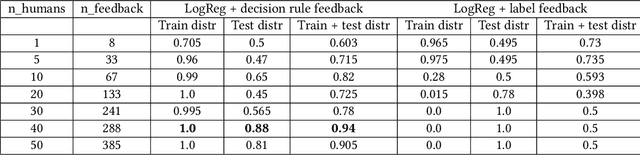
Human-in-the-loop machine learning is widely used in artificial intelligence (AI) to elicit labels for data points from experts or to provide feedback on how close the predicted results are to the target. This simplifies away all the details of the decision-making process of the expert. In this work, we allow the experts to additionally produce decision rules describing their decision-making; the rules are expected to be imperfect but to give additional information. In particular, the rules can extend to new distributions, and hence enable significantly improving performance for cases where the training and testing distributions differ, such as in domain adaptation. We apply the proposed method to lifelong learning and domain adaptation problems and discuss applications in other branches of AI, such as knowledge acquisition problems in expert systems. In simulated and real-user studies, we show that decision rule elicitation improves domain adaptation of the algorithm and helps to propagate expert's knowledge to the AI model.