 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBED-LLM: Intelligent Information Gathering with LLMs and Bayesian Experimental Design
Aug 28, 2025We propose a general-purpose approach for improving the ability of Large Language Models (LLMs) to intelligently and adaptively gather information from a user or other external source using the framework of sequential Bayesian experimental design (BED). This enables LLMs to act as effective multi-turn conversational agents and interactively interface with external environments. Our approach, which we call BED-LLM (Bayesian Experimental Design with Large Language Models), is based on iteratively choosing questions or queries that maximize the expected information gain (EIG) about the task of interest given the responses gathered previously. We show how this EIG can be formulated in a principled way using a probabilistic model derived from the LLM's belief distribution and provide detailed insights into key decisions in its construction. Further key to the success of BED-LLM are a number of specific innovations, such as a carefully designed estimator for the EIG, not solely relying on in-context updates for conditioning on previous responses, and a targeted strategy for proposing candidate queries. We find that BED-LLM achieves substantial gains in performance across a wide range of tests based on the 20-questions game and using the LLM to actively infer user preferences, compared to direct prompting of the LLM and other adaptive design strategies.
Scaling Up Active Testing to Large Language Models
Aug 12, 2025Active testing enables label-efficient evaluation of models through careful data acquisition. However, its significant computational costs have previously undermined its use for large models. We show how it can be successfully scaled up to the evaluation of large language models (LLMs). In particular we show that the surrogate model used to guide data acquisition can be constructed cheaply using in-context learning, does not require updating within an active-testing loop, and can be smaller than the target model. We even find we can make good data-acquisition decisions without computing predictions with the target model and further introduce a single-run error estimator to asses how well active testing is working on the fly. We find that our approach is able to more effectively evaluate LLM performance with less data than current standard practices.
Prediction-Oriented Subsampling from Data Streams
Aug 05, 2025Data is often generated in streams, with new observations arriving over time. A key challenge for learning models from data streams is capturing relevant information while keeping computational costs manageable. We explore intelligent data subsampling for offline learning, and argue for an information-theoretic method centred on reducing uncertainty in downstream predictions of interest. Empirically, we demonstrate that this prediction-oriented approach performs better than a previously proposed information-theoretic technique on two widely studied problems. At the same time, we highlight that reliably achieving strong performance in practice requires careful model design.
Rethinking Aleatoric and Epistemic Uncertainty
Dec 30, 2024

The ideas of aleatoric and epistemic uncertainty are widely used to reason about the probabilistic predictions of machine-learning models. We identify incoherence in existing discussions of these ideas and suggest this stems from the aleatoric-epistemic view being insufficiently expressive to capture all of the distinct quantities that researchers are interested in. To explain and address this we derive a simple delineation of different model-based uncertainties and the data-generating processes associated with training and evaluation. Using this in place of the aleatoric-epistemic view could produce clearer discourse as the field moves forward.
Making Better Use of Unlabelled Data in Bayesian Active Learning
Apr 26, 2024



Fully supervised models are predominant in Bayesian active learning. We argue that their neglect of the information present in unlabelled data harms not just predictive performance but also decisions about what data to acquire. Our proposed solution is a simple framework for semi-supervised Bayesian active learning. We find it produces better-performing models than either conventional Bayesian active learning or semi-supervised learning with randomly acquired data. It is also easier to scale up than the conventional approach. As well as supporting a shift towards semi-supervised models, our findings highlight the importance of studying models and acquisition methods in conjunction.
Continual Learning via Sequential Function-Space Variational Inference
Dec 28, 2023



Sequential Bayesian inference over predictive functions is a natural framework for continual learning from streams of data. However, applying it to neural networks has proved challenging in practice. Addressing the drawbacks of existing techniques, we propose an optimization objective derived by formulating continual learning as sequential function-space variational inference. In contrast to existing methods that regularize neural network parameters directly, this objective allows parameters to vary widely during training, enabling better adaptation to new tasks. Compared to objectives that directly regularize neural network predictions, the proposed objective allows for more flexible variational distributions and more effective regularization. We demonstrate that, across a range of task sequences, neural networks trained via sequential function-space variational inference achieve better predictive accuracy than networks trained with related methods while depending less on maintaining a set of representative points from previous tasks.
Prediction-Oriented Bayesian Active Learning
Apr 17, 2023



Information-theoretic approaches to active learning have traditionally focused on maximising the information gathered about the model parameters, most commonly by optimising the BALD score. We highlight that this can be suboptimal from the perspective of predictive performance. For example, BALD lacks a notion of an input distribution and so is prone to prioritise data of limited relevance. To address this we propose the expected predictive information gain (EPIG), an acquisition function that measures information gain in the space of predictions rather than parameters. We find that using EPIG leads to stronger predictive performance compared with BALD across a range of datasets and models, and thus provides an appealing drop-in replacement.
Modern Bayesian Experimental Design
Feb 28, 2023

Bayesian experimental design (BED) provides a powerful and general framework for optimizing the design of experiments. However, its deployment often poses substantial computational challenges that can undermine its practical use. In this review, we outline how recent advances have transformed our ability to overcome these challenges and thus utilize BED effectively, before discussing some key areas for future development in the field.
Understanding top-down attention using task-oriented ablation design
Jun 08, 2021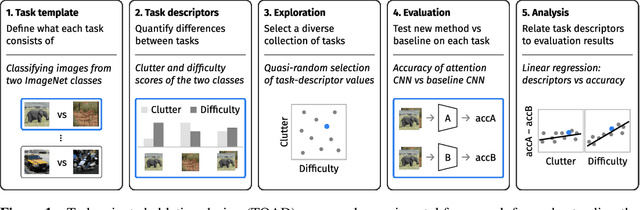
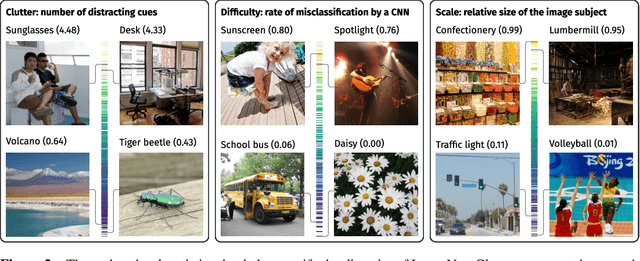
Top-down attention allows neural networks, both artificial and biological, to focus on the information most relevant for a given task. This is known to enhance performance in visual perception. But it remains unclear how attention brings about its perceptual boost, especially when it comes to naturalistic settings like recognising an object in an everyday scene. What aspects of a visual task does attention help to deal with? We aim to answer this with a computational experiment based on a general framework called task-oriented ablation design. First we define a broad range of visual tasks and identify six factors that underlie task variability. Then on each task we compare the performance of two neural networks, one with top-down attention and one without. These comparisons reveal the task-dependence of attention's perceptual boost, giving a clearer idea of the role attention plays. Whereas many existing cognitive accounts link attention to stimulus-level variables, such as visual clutter and object scale, we find greater explanatory power in system-level variables that capture the interaction between the model, the distribution of training data and the task format. This finding suggests a shift in how attention is studied could be fruitful. We make publicly available our code and results, along with statistics relevant to ImageNet-based experiments beyond this one. Our contribution serves to support the development of more human-like vision models and the design of more informative machine-learning experiments.
The perceptual boost of visual attention is task-dependent in naturalistic settings
Feb 22, 2020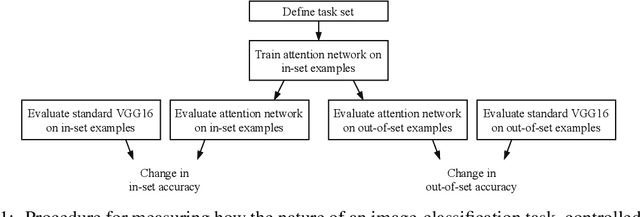
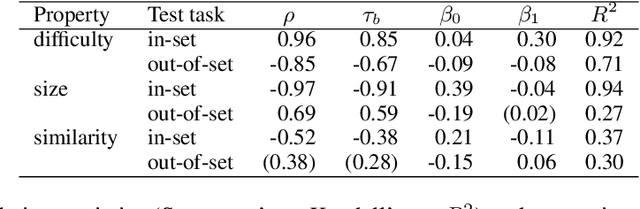
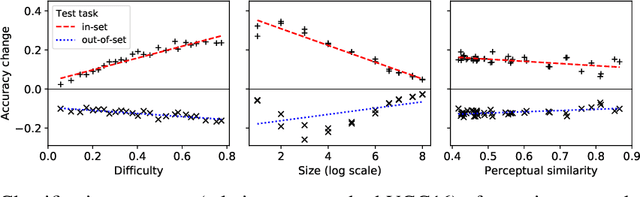
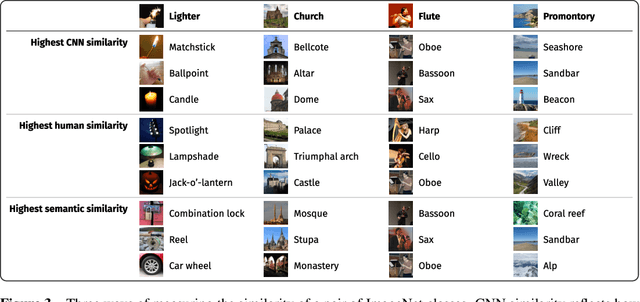
Attentional modulation of neural representations is known to enhance processing of task-relevant visual information. Is the resulting perceptual boost task-dependent in naturalistic settings? We aim to answer this with a large-scale computational experiment. First we design a series of visual tasks, each consisting of classifying images from a particular task set (group of image categories). The nature of a given task is determined by which categories are included in the task set. Then on each task we compare the accuracy of an attention-augmented neural network to that of an attention-free counterpart. We show that, all else being equal, the performance impact of attention is stronger with increasing task-set difficulty, weaker with increasing task-set size, and weaker with increasing perceptual similarity within a task set.