 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Document Derendering: SVG Reconstruction via Vision-Language Modeling
Nov 17, 2025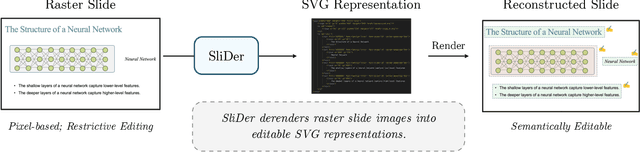
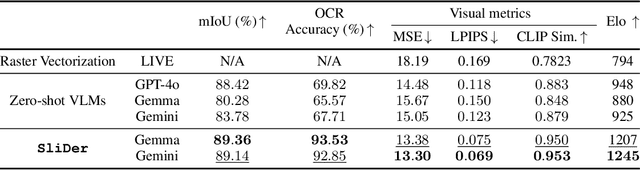
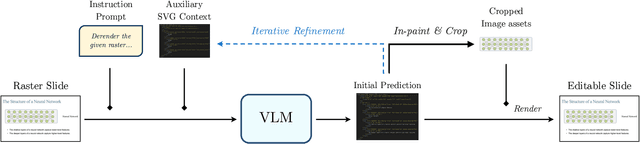
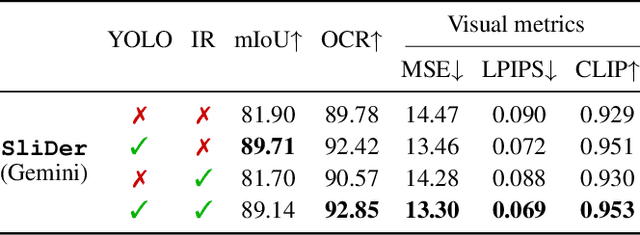
Multimedia documents such as slide presentations and posters are designed to be interactive and easy to modify. Yet, they are often distributed in a static raster format, which limits editing and customization. Restoring their editability requires converting these raster images back into structured vector formats. However, existing geometric raster-vectorization methods, which rely on low-level primitives like curves and polygons, fall short at this task. Specifically, when applied to complex documents like slides, they fail to preserve the high-level structure, resulting in a flat collection of shapes where the semantic distinction between image and text elements is lost. To overcome this limitation, we address the problem of semantic document derendering by introducing SliDer, a novel framework that uses Vision-Language Models (VLMs) to derender slide images as compact and editable Scalable Vector Graphic (SVG) representations. SliDer detects and extracts attributes from individual image and text elements in a raster input and organizes them into a coherent SVG format. Crucially, the model iteratively refines its predictions during inference in a process analogous to human design, generating SVG code that more faithfully reconstructs the original raster upon rendering. Furthermore, we introduce Slide2SVG, a novel dataset comprising raster-SVG pairs of slide documents curated from real-world scientific presentations, to facilitate future research in this domain. Our results demonstrate that SliDer achieves a reconstruction LPIPS of 0.069 and is favored by human evaluators in 82.9% of cases compared to the strongest zero-shot VLM baseline.
Sketch-to-Layout: Sketch-Guided Multimodal Layout Generation
Oct 31, 2025Graphic layout generation is a growing research area focusing on generating aesthetically pleasing layouts ranging from poster designs to documents. While recent research has explored ways to incorporate user constraints to guide the layout generation, these constraints often require complex specifications which reduce usability. We introduce an innovative approach exploiting user-provided sketches as intuitive constraints and we demonstrate empirically the effectiveness of this new guidance method, establishing the sketch-to-layout problem as a promising research direction, which is currently under-explored. To tackle the sketch-to-layout problem, we propose a multimodal transformer-based solution using the sketch and the content assets as inputs to produce high quality layouts. Since collecting sketch training data from human annotators to train our model is very costly, we introduce a novel and efficient method to synthetically generate training sketches at scale. We train and evaluate our model on three publicly available datasets: PubLayNet, DocLayNet and SlidesVQA, demonstrating that it outperforms state-of-the-art constraint-based methods, while offering a more intuitive design experience. In order to facilitate future sketch-to-layout research, we release O(200k) synthetically-generated sketches for the public datasets above. The datasets are available at https://github.com/google-deepmind/sketch_to_layout.
Pretrained Visual Uncertainties
Feb 27, 2024



Accurate uncertainty estimation is vital to trustworthy machine learning, yet uncertainties typically have to be learned for each task anew. This work introduces the first pretrained uncertainty modules for vision models. Similar to standard pretraining this enables the zero-shot transfer of uncertainties learned on a large pretraining dataset to specialized downstream datasets. We enable our large-scale pretraining on ImageNet-21k by solving a gradient conflict in previous uncertainty modules and accelerating the training by up to 180x. We find that the pretrained uncertainties generalize to unseen datasets. In scrutinizing the learned uncertainties, we find that they capture aleatoric uncertainty, disentangled from epistemic components. We demonstrate that this enables safe retrieval and uncertainty-aware dataset visualization. To encourage applications to further problems and domains, we release all pretrained checkpoints and code under https://github.com/mkirchhof/url .
Representing Online Handwriting for Recognition in Large Vision-Language Models
Feb 23, 2024



The adoption of tablets with touchscreens and styluses is increasing, and a key feature is converting handwriting to text, enabling search, indexing, and AI assistance. Meanwhile, vision-language models (VLMs) are now the go-to solution for image understanding, thanks to both their state-of-the-art performance across a variety of tasks and the simplicity of a unified approach to training, fine-tuning, and inference. While VLMs obtain high performance on image-based tasks, they perform poorly on handwriting recognition when applied naively, i.e., by rendering handwriting as an image and performing optical character recognition (OCR). In this paper, we study online handwriting recognition with VLMs, going beyond naive OCR. We propose a novel tokenized representation of digital ink (online handwriting) that includes both a time-ordered sequence of strokes as text, and as image. We show that this representation yields results comparable to or better than state-of-the-art online handwriting recognizers. Wide applicability is shown through results with two different VLM families, on multiple public datasets. Our approach can be applied to off-the-shelf VLMs, does not require any changes in their architecture, and can be used in both fine-tuning and parameter-efficient tuning. We perform a detailed ablation study to identify the key elements of the proposed representation.
Pi-DUAL: Using Privileged Information to Distinguish Clean from Noisy Labels
Oct 10, 2023Label noise is a pervasive problem in deep learning that often compromises the generalization performance of trained models. Recently, leveraging privileged information (PI) -- information available only during training but not at test time -- has emerged as an effective approach to mitigate this issue. Yet, existing PI-based methods have failed to consistently outperform their no-PI counterparts in terms of preventing overfitting to label noise. To address this deficiency, we introduce Pi-DUAL, an architecture designed to harness PI to distinguish clean from wrong labels. Pi-DUAL decomposes the output logits into a prediction term, based on conventional input features, and a noise-fitting term influenced solely by PI. A gating mechanism steered by PI adaptively shifts focus between these terms, allowing the model to implicitly separate the learning paths of clean and wrong labels. Empirically, Pi-DUAL achieves significant performance improvements on key PI benchmarks (e.g., +6.8% on ImageNet-PI), establishing a new state-of-the-art test set accuracy. Additionally, Pi-DUAL is a potent method for identifying noisy samples post-training, outperforming other strong methods at this task. Overall, Pi-DUAL is a simple, scalable and practical approach for mitigating the effects of label noise in a variety of real-world scenarios with PI.
Three Towers: Flexible Contrastive Learning with Pretrained Image Models
May 29, 2023



We introduce Three Towers (3T), a flexible method to improve the contrastive learning of vision-language models by incorporating pretrained image classifiers. While contrastive models are usually trained from scratch, LiT (Zhai et al., 2022) has recently shown performance gains from using pretrained classifier embeddings. However, LiT directly replaces the image tower with the frozen embeddings, excluding any potential benefits of contrastively training the image tower. With 3T, we propose a more flexible strategy that allows the image tower to benefit from both pretrained embeddings and contrastive training. To achieve this, we introduce a third tower that contains the frozen pretrained embeddings, and we encourage alignment between this third tower and the main image-text towers. Empirically, 3T consistently improves over LiT and the CLIP-style from-scratch baseline for retrieval tasks. For classification, 3T reliably improves over the from-scratch baseline, and while it underperforms relative to LiT for JFT-pretrained models, it outperforms LiT for ImageNet-21k and Places365 pretraining.
When does Privileged Information Explain Away Label Noise?
Mar 03, 2023
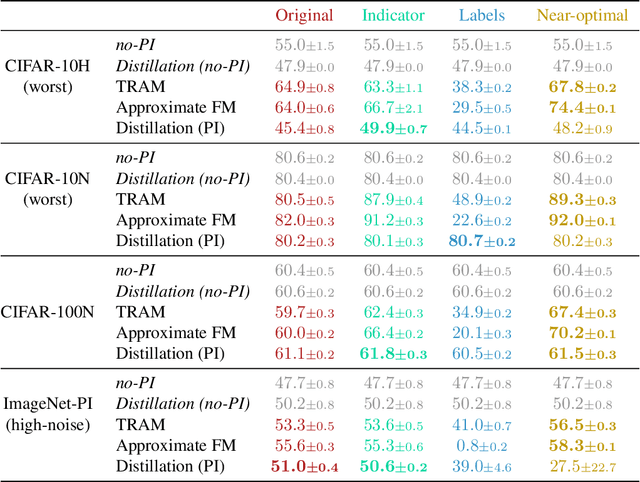
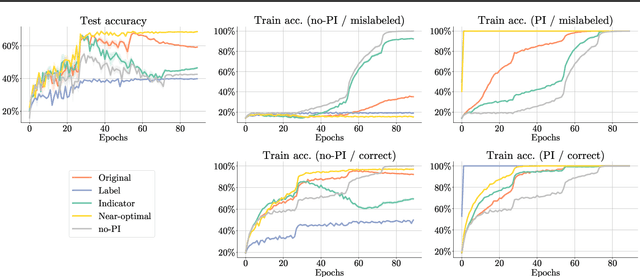

Leveraging privileged information (PI), or features available during training but not at test time, has recently been shown to be an effective method for addressing label noise. However, the reasons for its effectiveness are not well understood. In this study, we investigate the role played by different properties of the PI in explaining away label noise. Through experiments on multiple datasets with real PI (CIFAR-N/H) and a new large-scale benchmark ImageNet-PI, we find that PI is most helpful when it allows networks to easily distinguish clean from noisy data, while enabling a learning shortcut to memorize the noisy examples. Interestingly, when PI becomes too predictive of the target label, PI methods often perform worse than their no-PI baselines. Based on these findings, we propose several enhancements to the state-of-the-art PI methods and demonstrate the potential of PI as a means of tackling label noise. Finally, we show how we can easily combine the resulting PI approaches with existing no-PI techniques designed to deal with label noise.
Massively Scaling Heteroscedastic Classifiers
Jan 30, 2023


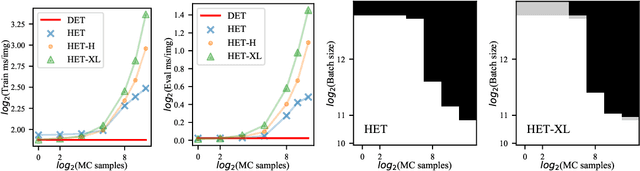
Heteroscedastic classifiers, which learn a multivariate Gaussian distribution over prediction logits, have been shown to perform well on image classification problems with hundreds to thousands of classes. However, compared to standard classifiers, they introduce extra parameters that scale linearly with the number of classes. This makes them infeasible to apply to larger-scale problems. In addition heteroscedastic classifiers introduce a critical temperature hyperparameter which must be tuned. We propose HET-XL, a heteroscedastic classifier whose parameter count when compared to a standard classifier scales independently of the number of classes. In our large-scale settings, we show that we can remove the need to tune the temperature hyperparameter, by directly learning it on the training data. On large image classification datasets with up to 4B images and 30k classes our method requires 14X fewer additional parameters, does not require tuning the temperature on a held-out set and performs consistently better than the baseline heteroscedastic classifier. HET-XL improves ImageNet 0-shot classification in a multimodal contrastive learning setup which can be viewed as a 3.5 billion class classification problem.
Plex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022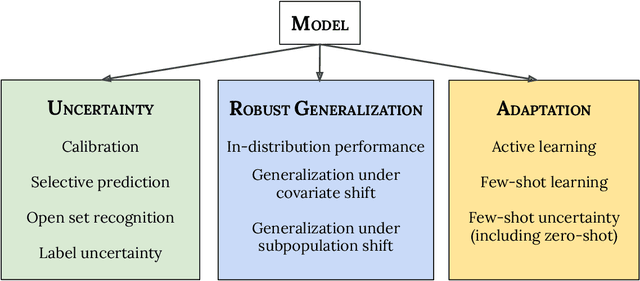

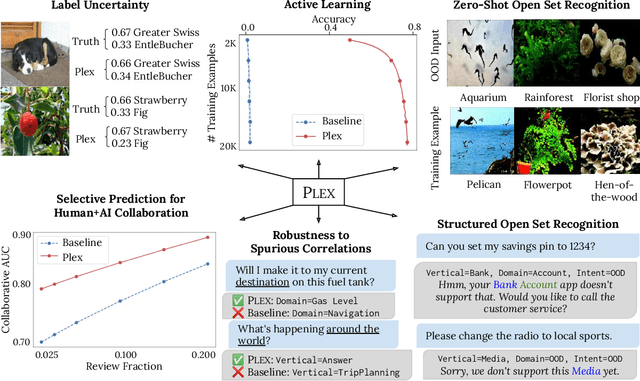

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.
Transfer and Marginalize: Explaining Away Label Noise with Privileged Information
Feb 18, 2022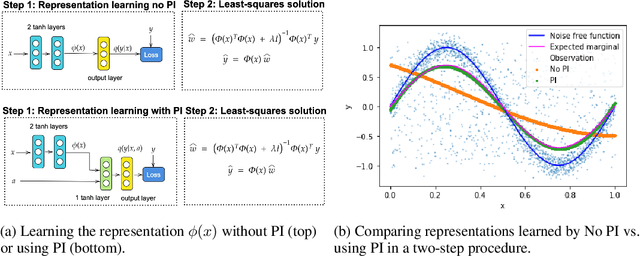
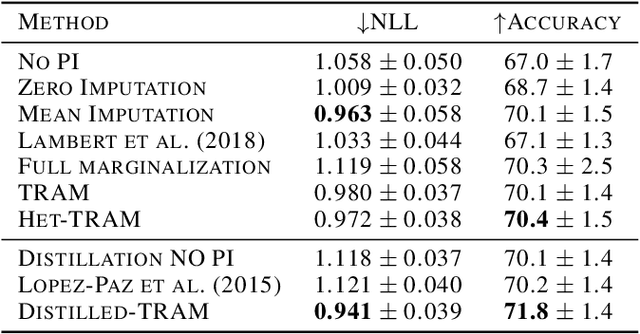
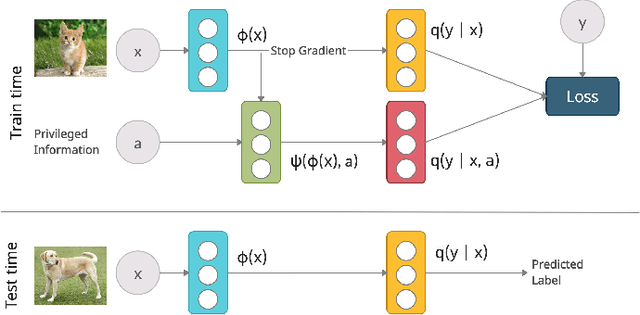
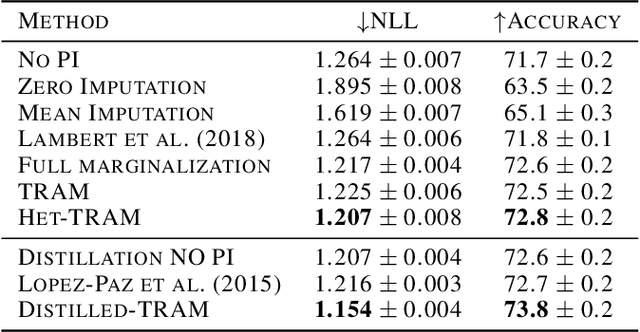
Supervised learning datasets often have privileged information, in the form of features which are available at training time but are not available at test time e.g. the ID of the annotator that provided the label. We argue that privileged information is useful for explaining away label noise, thereby reducing the harmful impact of noisy labels. We develop a simple and efficient method for supervised neural networks: it transfers via weight sharing the knowledge learned with privileged information and approximately marginalizes over privileged information at test time. Our method, TRAM (TRansfer and Marginalize), has minimal training time overhead and has the same test time cost as not using privileged information. TRAM performs strongly on CIFAR-10H, ImageNet and Civil Comments benchmarks.