 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding 2: A Native Multimodal Embedding Model from Gemini
May 26, 2026We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
Representing Online Handwriting for Recognition in Large Vision-Language Models
Feb 23, 2024



The adoption of tablets with touchscreens and styluses is increasing, and a key feature is converting handwriting to text, enabling search, indexing, and AI assistance. Meanwhile, vision-language models (VLMs) are now the go-to solution for image understanding, thanks to both their state-of-the-art performance across a variety of tasks and the simplicity of a unified approach to training, fine-tuning, and inference. While VLMs obtain high performance on image-based tasks, they perform poorly on handwriting recognition when applied naively, i.e., by rendering handwriting as an image and performing optical character recognition (OCR). In this paper, we study online handwriting recognition with VLMs, going beyond naive OCR. We propose a novel tokenized representation of digital ink (online handwriting) that includes both a time-ordered sequence of strokes as text, and as image. We show that this representation yields results comparable to or better than state-of-the-art online handwriting recognizers. Wide applicability is shown through results with two different VLM families, on multiple public datasets. Our approach can be applied to off-the-shelf VLMs, does not require any changes in their architecture, and can be used in both fine-tuning and parameter-efficient tuning. We perform a detailed ablation study to identify the key elements of the proposed representation.
Learning to Infer User Interface Attributes from Images
Dec 31, 2019
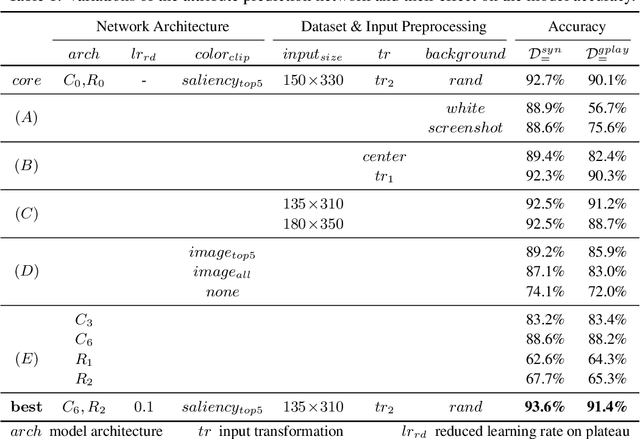
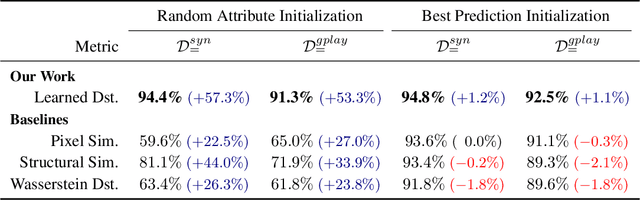

We explore a new domain of learning to infer user interface attributes that helps developers automate the process of user interface implementation. Concretely, given an input image created by a designer, we learn to infer its implementation which when rendered, looks visually the same as the input image. To achieve this, we take a black box rendering engine and a set of attributes it supports (e.g., colors, border radius, shadow or text properties), use it to generate a suitable synthetic training dataset, and then train specialized neural models to predict each of the attribute values. To improve pixel-level accuracy, we additionally use imitation learning to train a neural policy that refines the predicted attribute values by learning to compute the similarity of the original and rendered images in their attribute space, rather than based on the difference of pixel values. We instantiate our approach to the task of inferring Android Button attribute values and achieve 92.5% accuracy on a dataset consisting of real-world Google Play Store applications.