 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch-to-Layout: Sketch-Guided Multimodal Layout Generation
Oct 31, 2025Graphic layout generation is a growing research area focusing on generating aesthetically pleasing layouts ranging from poster designs to documents. While recent research has explored ways to incorporate user constraints to guide the layout generation, these constraints often require complex specifications which reduce usability. We introduce an innovative approach exploiting user-provided sketches as intuitive constraints and we demonstrate empirically the effectiveness of this new guidance method, establishing the sketch-to-layout problem as a promising research direction, which is currently under-explored. To tackle the sketch-to-layout problem, we propose a multimodal transformer-based solution using the sketch and the content assets as inputs to produce high quality layouts. Since collecting sketch training data from human annotators to train our model is very costly, we introduce a novel and efficient method to synthetically generate training sketches at scale. We train and evaluate our model on three publicly available datasets: PubLayNet, DocLayNet and SlidesVQA, demonstrating that it outperforms state-of-the-art constraint-based methods, while offering a more intuitive design experience. In order to facilitate future sketch-to-layout research, we release O(200k) synthetically-generated sketches for the public datasets above. The datasets are available at https://github.com/google-deepmind/sketch_to_layout.
InkFM: A Foundational Model for Full-Page Online Handwritten Note Understanding
Mar 29, 2025



Tablets and styluses are increasingly popular for taking notes. To optimize this experience and ensure a smooth and efficient workflow, it's important to develop methods for accurately interpreting and understanding the content of handwritten digital notes. We introduce a foundational model called InkFM for analyzing full pages of handwritten content. Trained on a diverse mixture of tasks, this model offers a unique combination of capabilities: recognizing text in 28 different scripts, mathematical expressions recognition, and segmenting pages into distinct elements like text and drawings. Our results demonstrate that these tasks can be effectively unified within a single model, achieving SoTA text line segmentation out-of-the-box quality surpassing public baselines like docTR. Fine- or LoRA-tuning our base model on public datasets further improves the quality of page segmentation, achieves state-of the art text recognition (DeepWriting, CASIA, SCUT, and Mathwriting datasets) and sketch classification (QuickDraw). This adaptability of InkFM provides a powerful starting point for developing applications with handwritten input.
MathWriting: A Dataset For Handwritten Mathematical Expression Recognition
Apr 16, 2024We introduce MathWriting, the largest online handwritten mathematical expression dataset to date. It consists of 230k human-written samples and an additional 400k synthetic ones. MathWriting can also be used for offline HME recognition and is larger than all existing offline HME datasets like IM2LATEX-100K. We introduce a benchmark based on MathWriting data in order to advance research on both online and offline HME recognition.
Representing Online Handwriting for Recognition in Large Vision-Language Models
Feb 23, 2024



The adoption of tablets with touchscreens and styluses is increasing, and a key feature is converting handwriting to text, enabling search, indexing, and AI assistance. Meanwhile, vision-language models (VLMs) are now the go-to solution for image understanding, thanks to both their state-of-the-art performance across a variety of tasks and the simplicity of a unified approach to training, fine-tuning, and inference. While VLMs obtain high performance on image-based tasks, they perform poorly on handwriting recognition when applied naively, i.e., by rendering handwriting as an image and performing optical character recognition (OCR). In this paper, we study online handwriting recognition with VLMs, going beyond naive OCR. We propose a novel tokenized representation of digital ink (online handwriting) that includes both a time-ordered sequence of strokes as text, and as image. We show that this representation yields results comparable to or better than state-of-the-art online handwriting recognizers. Wide applicability is shown through results with two different VLM families, on multiple public datasets. Our approach can be applied to off-the-shelf VLMs, does not require any changes in their architecture, and can be used in both fine-tuning and parameter-efficient tuning. We perform a detailed ablation study to identify the key elements of the proposed representation.
InkSight: Offline-to-Online Handwriting Conversion by Learning to Read and Write
Feb 21, 2024



Digital note-taking is gaining popularity, offering a durable, editable, and easily indexable way of storing notes in the vectorized form, known as digital ink. However, a substantial gap remains between this way of note-taking and traditional pen-and-paper note-taking, a practice still favored by a vast majority. Our work, InkSight, aims to bridge the gap by empowering physical note-takers to effortlessly convert their work (offline handwriting) to digital ink (online handwriting), a process we refer to as Derendering. Prior research on the topic has focused on the geometric properties of images, resulting in limited generalization beyond their training domains. Our approach combines reading and writing priors, allowing training a model in the absence of large amounts of paired samples, which are difficult to obtain. To our knowledge, this is the first work that effectively derenders handwritten text in arbitrary photos with diverse visual characteristics and backgrounds. Furthermore, it generalizes beyond its training domain into simple sketches. Our human evaluation reveals that 87% of the samples produced by our model on the challenging HierText dataset are considered as a valid tracing of the input image and 67% look like a pen trajectory traced by a human. Interactive visualizations of 100 word-level model outputs for each of the three public datasets are available in our Hugging Face space: https://huggingface.co/spaces/Derendering/Model-Output-Playground. Model release is in progress.
DSS: Synthesizing long Digital Ink using Data augmentation, Style encoding and Split generation
Nov 29, 2023As text generative models can give increasingly long answers, we tackle the problem of synthesizing long text in digital ink. We show that the commonly used models for this task fail to generalize to long-form data and how this problem can be solved by augmenting the training data, changing the model architecture and the inference procedure. These methods use contrastive learning technique and are tailored specifically for the handwriting domain. They can be applied to any encoder-decoder model that works with digital ink. We demonstrate that our method reduces the character error rate on long-form English data by half compared to baseline RNN and by 16% compared to the previous approach that aims at addressing the same problem. We show that all three parts of the method improve recognizability of generated inks. In addition, we evaluate synthesized data in a human study and find that people perceive most of generated data as real.
Character Queries: A Transformer-based Approach to On-Line Handwritten Character Segmentation
Sep 06, 2023On-line handwritten character segmentation is often associated with handwriting recognition and even though recognition models include mechanisms to locate relevant positions during the recognition process, it is typically insufficient to produce a precise segmentation. Decoupling the segmentation from the recognition unlocks the potential to further utilize the result of the recognition. We specifically focus on the scenario where the transcription is known beforehand, in which case the character segmentation becomes an assignment problem between sampling points of the stylus trajectory and characters in the text. Inspired by the $k$-means clustering algorithm, we view it from the perspective of cluster assignment and present a Transformer-based architecture where each cluster is formed based on a learned character query in the Transformer decoder block. In order to assess the quality of our approach, we create character segmentation ground truths for two popular on-line handwriting datasets, IAM-OnDB and HANDS-VNOnDB, and evaluate multiple methods on them, demonstrating that our approach achieves the overall best results.
* ICDAR 2023 Best Student Paper Award. Code available at https://github.com/jungomi/character-queries
Sampling and Ranking for Digital Ink Generation on a tight computational budget
Jun 02, 2023

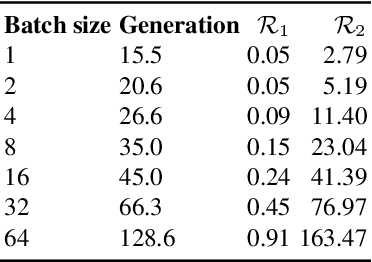

Digital ink (online handwriting) generation has a number of potential applications for creating user-visible content, such as handwriting autocompletion, spelling correction, and beautification. Writing is personal and usually the processing is done on-device. Ink generative models thus need to produce high quality content quickly, in a resource constrained environment. In this work, we study ways to maximize the quality of the output of a trained digital ink generative model, while staying within an inference time budget. We use and compare the effect of multiple sampling and ranking techniques, in the first ablation study of its kind in the digital ink domain. We confirm our findings on multiple datasets - writing in English and Vietnamese, as well as mathematical formulas - using two model types and two common ink data representations. In all combinations, we report a meaningful improvement in the recognizability of the synthetic inks, in some cases more than halving the character error rate metric, and describe a way to select the optimal combination of sampling and ranking techniques for any given computational budget.
Inkorrect: Online Handwriting Spelling Correction
Feb 28, 2022
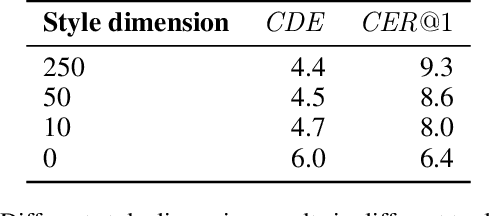
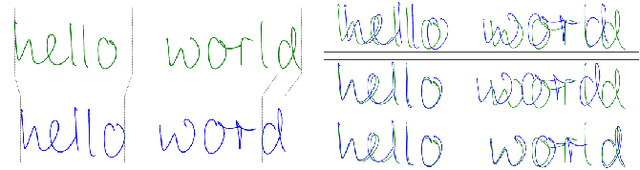

We introduce Inkorrect, a data- and label-efficient approach for online handwriting (Digital Ink) spelling correction - DISC. Unlike previous work, the proposed method does not require multiple samples from the same writer, or access to character level segmentation. We show that existing automatic evaluation metrics do not fully capture and are not correlated with the human perception of the quality of the spelling correction, and propose new ones that correlate with human perception. We additionally surface an interesting phenomenon: a trade-off between the similarity and recognizability of the spell-corrected inks. We further create a family of models corresponding to different points on the Pareto frontier between those two axes. We show that Inkorrect's Pareto frontier dominates the points that correspond to prior work.
Eliminating Exposure Bias and Loss-Evaluation Mismatch in Multiple Object Tracking
Nov 27, 2018
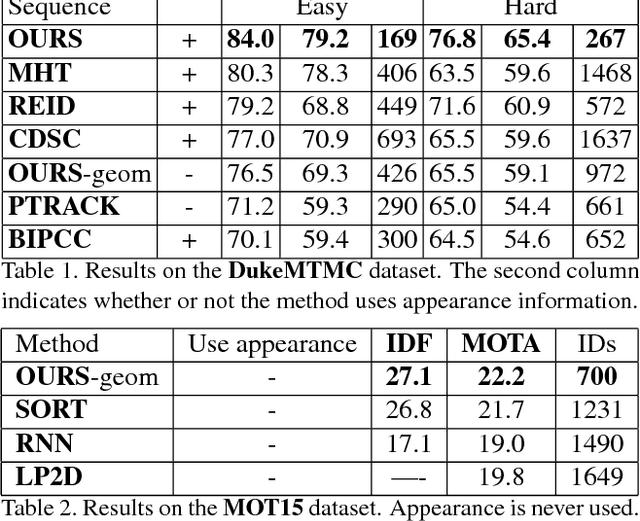
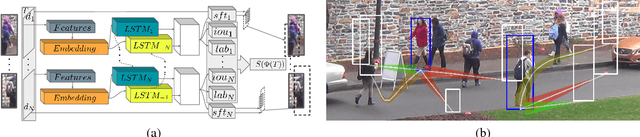
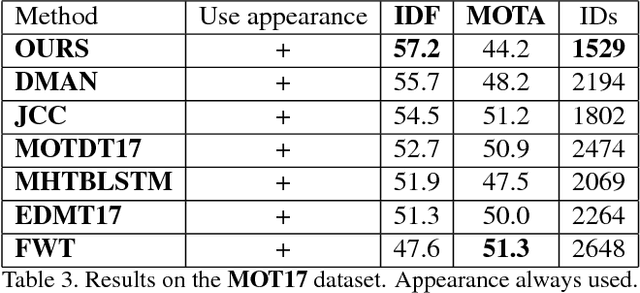
Identity Switching remains one of the main difficulties Multiple Object Tracking (MOT) algorithms have to deal with. Many state-of-the-art approaches now use sequence models to solve this problem but their training can be affected by biases that decrease their efficiency. In this paper, we introduce a new training procedure that confronts the algorithm to its own mistakes while explicitly attempting to minimize the number of switches, which results in better training. We propose an iterative scheme of building a rich training set and using it to learn a scoring function that is an explicit proxy for the target tracking metric. Whether using only simple geometric features or more sophisticated ones that also take appearance into account, our approach outperforms the state-of-the-art on several MOT benchmarks.