 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSS: Synthesizing long Digital Ink using Data augmentation, Style encoding and Split generation
Nov 29, 2023As text generative models can give increasingly long answers, we tackle the problem of synthesizing long text in digital ink. We show that the commonly used models for this task fail to generalize to long-form data and how this problem can be solved by augmenting the training data, changing the model architecture and the inference procedure. These methods use contrastive learning technique and are tailored specifically for the handwriting domain. They can be applied to any encoder-decoder model that works with digital ink. We demonstrate that our method reduces the character error rate on long-form English data by half compared to baseline RNN and by 16% compared to the previous approach that aims at addressing the same problem. We show that all three parts of the method improve recognizability of generated inks. In addition, we evaluate synthesized data in a human study and find that people perceive most of generated data as real.
Sampling and Ranking for Digital Ink Generation on a tight computational budget
Jun 02, 2023


Digital ink (online handwriting) generation has a number of potential applications for creating user-visible content, such as handwriting autocompletion, spelling correction, and beautification. Writing is personal and usually the processing is done on-device. Ink generative models thus need to produce high quality content quickly, in a resource constrained environment. In this work, we study ways to maximize the quality of the output of a trained digital ink generative model, while staying within an inference time budget. We use and compare the effect of multiple sampling and ranking techniques, in the first ablation study of its kind in the digital ink domain. We confirm our findings on multiple datasets - writing in English and Vietnamese, as well as mathematical formulas - using two model types and two common ink data representations. In all combinations, we report a meaningful improvement in the recognizability of the synthetic inks, in some cases more than halving the character error rate metric, and describe a way to select the optimal combination of sampling and ranking techniques for any given computational budget.
Can we learn gradients by Hamiltonian Neural Networks?
Oct 31, 2021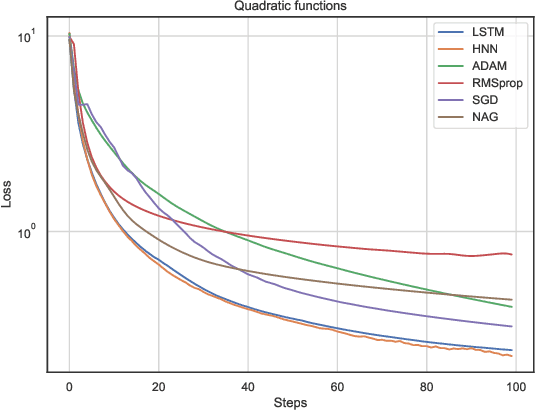
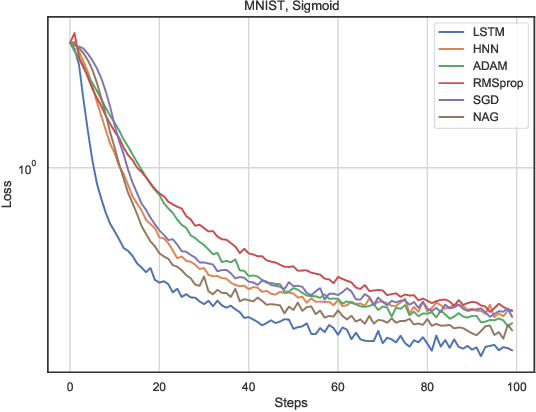
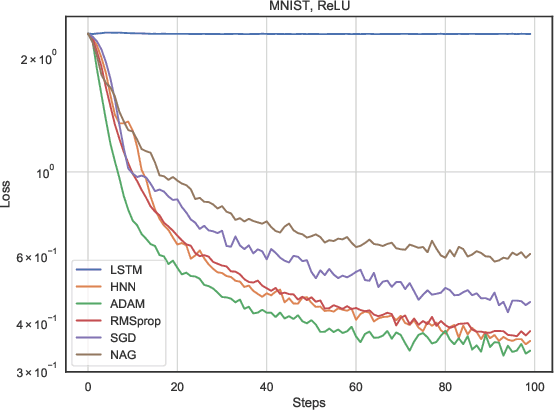
In this work, we propose a meta-learner based on ODE neural networks that learns gradients. This approach makes the optimizer is more flexible inducing an automatic inductive bias to the given task. Using the simplest Hamiltonian Neural Network we demonstrate that our method outperforms a meta-learner based on LSTM for an artificial task and the MNIST dataset with ReLU activations in the optimizee. Furthermore, it also surpasses the classic optimization methods for the artificial task and achieves comparable results for MNIST.
Towards Model Agnostic Federated Learning Using Knowledge Distillation
Oct 28, 2021


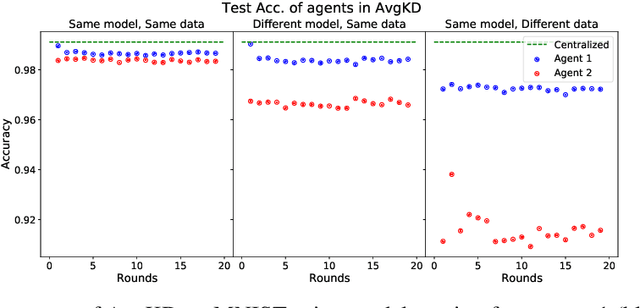
An often unquestioned assumption underlying most current federated learning algorithms is that all the participants use identical model architectures. In this work, we initiate a theoretical study of model agnostic communication protocols which would allow data holders (agents) using different models to collaborate with each other and perform federated learning. We focus on the setting where the two agents are attempting to perform kernel regression using different kernels (and hence have different models). Our study yields a surprising result -- the most natural algorithm of using alternating knowledge distillation (AKD) imposes overly strong regularization and may lead to severe under-fitting. Our theory also shows an interesting connection between AKD and the alternating projection algorithm for finding intersection of sets. Leveraging this connection, we propose a new algorithms which improve upon AKD. Our theoretical predictions also closely match real world experiments using neural networks. Thus, our work proposes a rich yet tractable framework for analyzing and developing new practical model agnostic federated learning algorithms.
Which Neural Network to Choose for Post-Fault Localization, Dynamic State Estimation and Optimal Measurement Placement in Power Systems?
Apr 07, 2021
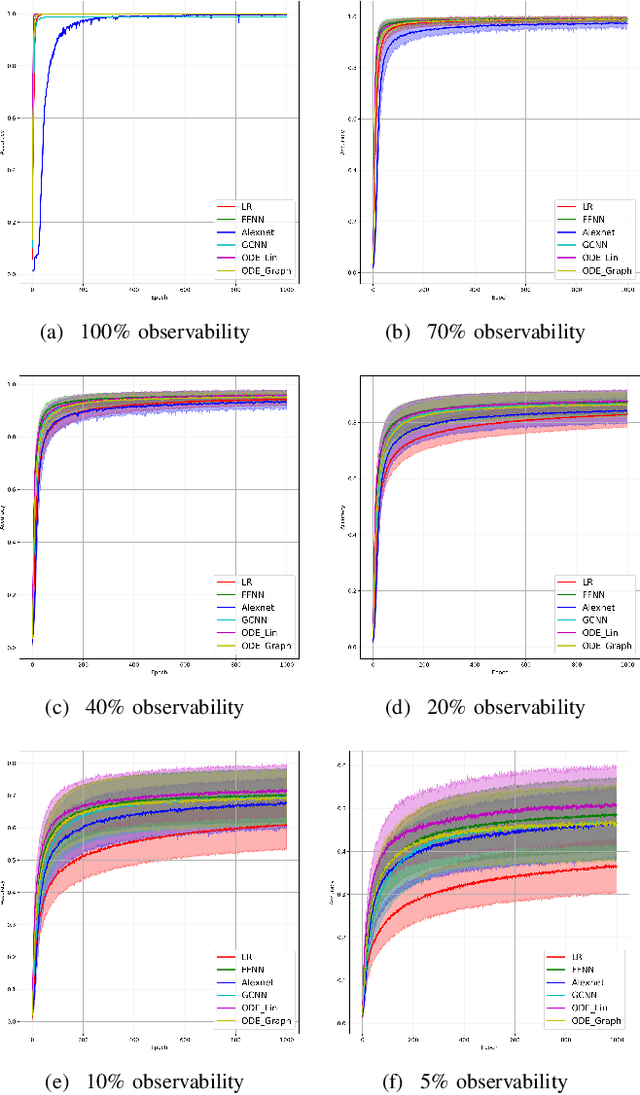

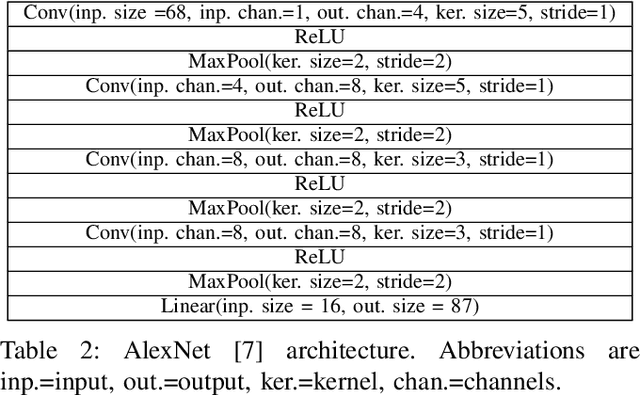
We consider a power transmission system monitored with Phasor Measurement Units (PMUs) placed at significant, but not all, nodes of the system. Assuming that a sufficient number of distinct single-line faults, specifically pre-fault state and (not cleared) post-fault state, are recorded by the PMUs and are available for training, we, first, design a comprehensive sequence of Neural Networks (NNs) locating the faulty line. Performance of different NNs in the sequence, including Linear Regression, Feed-Forward NN, AlexNet, Graphical Convolutional NN, Neural Linear ODE and Neural Graph-based ODE, ordered according to the type and amount of the power flow physics involved, are compared for different levels of observability. Second, we build a sequence of advanced Power-System-Dynamics-Informed and Neural-ODE based Machine Learning schemes trained, given pre-fault state, to predict the post-fault state and also, in parallel, to estimate system parameters. Finally, third, and continuing to work with the first (fault localization) setting we design a (NN-based) algorithm which discovers optimal PMU placement.