 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Visual Privacy: A Compositional Privacy Risk Framework for Severity Assessment with VLMs
Mar 23, 2026Existing visual privacy benchmarks largely treat privacy as a binary property, labeling images as private or non-private based on visible sensitive content. We argue that privacy is fundamentally compositional. Attributes that are benign in isolation may combine to produce severe privacy violations. We introduce the Compositional Privacy Risk Taxonomy (CPRT), a regulation-aware framework that organizes visual attributes according to standalone identifiability and compositional harm potential. CPRT defines four graded severity levels and is paired with an interpretable scoring function that assigns continuous privacy severity scores. We further construct a taxonomy-aligned dataset of 6.7K images and derive ground-truth compositional risk scores. By evaluating frontier and open-weight VLMs we find that frontier models align well with compositional severity when provided structured guidance, but systematically underestimate composition-driven risks. Smaller models struggle to internalize graded privacy reasoning. To bridge this gap, we introduce a deployable 8B supervised fine-tuned (SFT) model that closely matches frontier-level performance on compositional privacy assessment.
Targeted Speaker Poisoning Framework in Zero-Shot Text-to-Speech
Mar 08, 2026Zero-shot Text-to-Speech (TTS) voice cloning poses severe privacy risks, demanding the removal of specific speaker identities from trained TTS models. Conventional machine unlearning is insufficient in this context, as zero-shot TTS can dynamically reconstruct voices from just reference prompts. We formalize this task as Speech Generation Speaker Poisoning (SGSP), in which we modify trained models to prevent the generation of specific identities while preserving utility for other speakers. We evaluate inference-time filtering and parameter-modification baselines across 1, 15, and 100 forgotten speakers. Performance is assessed through the trade-off between utility (WER) and privacy, quantified using AUC and Forget Speaker Similarity (FSSIM). We achieve strong privacy for up to 15 speakers but reveal scalability limits at 100 speakers due to increased identity overlap. Our study thus introduces a novel problem and evaluation framework toward further advances in generative voice privacy.
OpaqueToolsBench: Learning Nuances of Tool Behavior Through Interaction
Feb 16, 2026Tool-calling is essential for Large Language Model (LLM) agents to complete real-world tasks. While most existing benchmarks assume simple, perfectly documented tools, real-world tools (e.g., general "search" APIs) are often opaque, lacking clear best practices or failure modes. Can LLM agents improve their performance in environments with opaque tools by interacting and subsequently improving documentation? To study this, we create OpaqueToolsBench, a benchmark consisting of three distinct task-oriented environments: general function calling, interactive chess playing, and long-trajectory agentic search. Each environment provides underspecified tools that models must learn to use effectively to complete the task. Results on OpaqueToolsBench suggest existing methods for automatically documenting tools are expensive and unreliable when tools are opaque. To address this, we propose a simple framework, ToolObserver, that iteratively refines tool documentation by observing execution feedback from tool-calling trajectories. Our approach outperforms existing methods on OpaqueToolsBench across datasets, even in relatively hard settings. Furthermore, for test-time tool exploration settings, our method is also efficient, consuming 3.5-7.5x fewer total tokens than the best baseline.
Hair-Trigger Alignment: Black-Box Evaluation Cannot Guarantee Post-Update Alignment
Jan 29, 2026Large Language Models (LLMs) are rarely static and are frequently updated in practice. A growing body of alignment research has shown that models initially deemed "aligned" can exhibit misaligned behavior after fine-tuning, such as forgetting jailbreak safety features or re-surfacing knowledge that was intended to be forgotten. These works typically assume that the initial model is aligned based on static black-box evaluation, i.e., the absence of undesired responses to a fixed set of queries. In contrast, we formalize model alignment in both the static and post-update settings and uncover a fundamental limitation of black-box evaluation. We theoretically show that, due to overparameterization, static alignment provides no guarantee of post-update alignment for any update dataset. Moreover, we prove that static black-box probing cannot distinguish a model that is genuinely post-update robust from one that conceals an arbitrary amount of adversarial behavior which can be activated by even a single benign gradient update. We further validate these findings empirically in LLMs across three core alignment domains: privacy, jailbreak safety, and behavioral honesty. We demonstrate the existence of LLMs that pass all standard black-box alignment tests, yet become severely misaligned after a single benign update. Finally, we show that the capacity to hide such latent adversarial behavior increases with model scale, confirming our theoretical prediction that post-update misalignment grows with the number of parameters. Together, our results highlight the inadequacy of static evaluation protocols and emphasize the urgent need for post-update-robust alignment evaluation.
Sparks of Rationality: Do Reasoning LLMs Align with Human Judgment and Choice?
Jan 29, 2026Large Language Models (LLMs) are increasingly positioned as decision engines for hiring, healthcare, and economic judgment, yet real-world human judgment reflects a balance between rational deliberation and emotion-driven bias. If LLMs are to participate in high-stakes decisions or serve as models of human behavior, it is critical to assess whether they exhibit analogous patterns of (ir)rationalities and biases. To this end, we evaluate multiple LLM families on (i) benchmarks testing core axioms of rational choice and (ii) classic decision domains from behavioral economics and social norms where emotions are known to shape judgment and choice. Across settings, we show that deliberate "thinking" reliably improves rationality and pushes models toward expected-value maximization. To probe human-like affective distortions and their interaction with reasoning, we use two emotion-steering methods: in-context priming (ICP) and representation-level steering (RLS). ICP induces strong directional shifts that are often extreme and difficult to calibrate, whereas RLS produces more psychologically plausible patterns but with lower reliability. Our results suggest that the same mechanisms that improve rationality also amplify sensitivity to affective interventions, and that different steering methods trade off controllability against human-aligned behavior. Overall, this points to a tension between reasoning and affective steering, with implications for both human simulation and the safe deployment of LLM-based decision systems.
ContextLeak: Auditing Leakage in Private In-Context Learning Methods
Dec 18, 2025In-Context Learning (ICL) has become a standard technique for adapting Large Language Models (LLMs) to specialized tasks by supplying task-specific exemplars within the prompt. However, when these exemplars contain sensitive information, reliable privacy-preserving mechanisms are essential to prevent unintended leakage through model outputs. Many privacy-preserving methods are proposed to protect the information leakage in the context, but there are less efforts on how to audit those methods. We introduce ContextLeak, the first framework to empirically measure the worst-case information leakage in ICL. ContextLeak uses canary insertion, embedding uniquely identifiable tokens in exemplars and crafting targeted queries to detect their presence. We apply ContextLeak across a range of private ICL techniques, both heuristic such as prompt-based defenses and those with theoretical guarantees such as Embedding Space Aggregation and Report Noisy Max. We find that ContextLeak tightly correlates with the theoretical privacy budget ($ε$) and reliably detects leakage. Our results further reveal that existing methods often strike poor privacy-utility trade-offs, either leaking sensitive information or severely degrading performance.
A Closer Look at Personalized Fine-Tuning in Heterogeneous Federated Learning
Nov 16, 2025
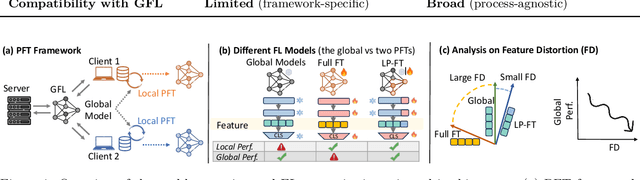
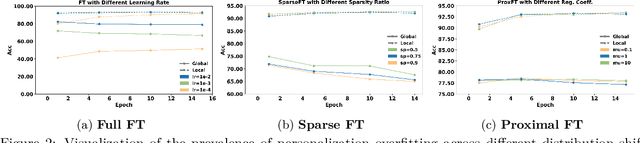
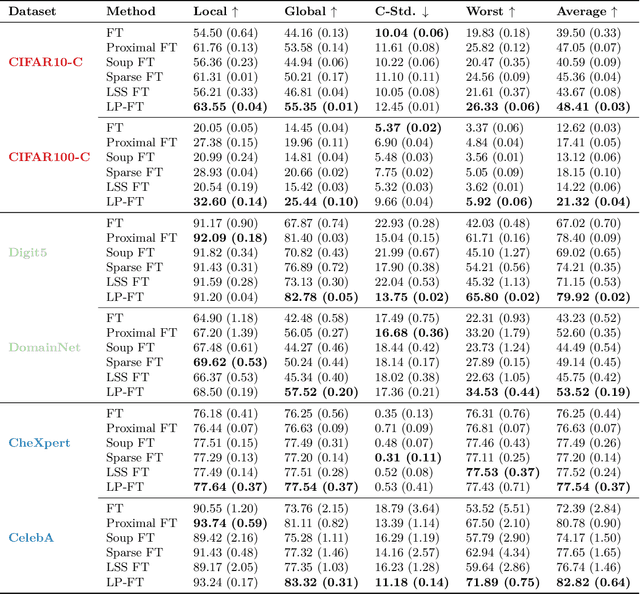
Federated Learning (FL) enables decentralized, privacy-preserving model training but struggles to balance global generalization and local personalization due to non-identical data distributions across clients. Personalized Fine-Tuning (PFT), a popular post-hoc solution, fine-tunes the final global model locally but often overfits to skewed client distributions or fails under domain shifts. We propose adapting Linear Probing followed by full Fine-Tuning (LP-FT), a principled centralized strategy for alleviating feature distortion (Kumar et al., 2022), to the FL setting. Through systematic evaluation across seven datasets and six PFT variants, we demonstrate LP-FT's superiority in balancing personalization and generalization. Our analysis uncovers federated feature distortion, a phenomenon where local fine-tuning destabilizes globally learned features, and theoretically characterizes how LP-FT mitigates this via phased parameter updates. We further establish conditions (e.g., partial feature overlap, covariate-concept shift) under which LP-FT outperforms standard fine-tuning, offering actionable guidelines for deploying robust personalization in FL.
Psychological Steering in LLMs: An Evaluation of Effectiveness and Trustworthiness
Oct 06, 2025The ability to control LLMs' emulated emotional states and personality traits is essential for enabling rich, human-centered interactions in socially interactive settings. We introduce PsySET, a Psychologically-informed benchmark to evaluate LLM Steering Effectiveness and Trustworthiness across the emotion and personality domains. Our study spans four models from different LLM families paired with various steering strategies, including prompting, fine-tuning, and representation engineering. Our results indicate that prompting is consistently effective but limited in intensity control, whereas vector injections achieve finer controllability while slightly reducing output quality. Moreover, we explore the trustworthiness of steered LLMs by assessing safety, truthfulness, fairness, and ethics, highlighting potential side effects and behavioral shifts. Notably, we observe idiosyncratic effects; for instance, even a positive emotion like joy can degrade robustness to adversarial factuality, lower privacy awareness, and increase preferential bias. Meanwhile, anger predictably elevates toxicity yet strengthens leakage resistance. Our framework establishes the first holistic evaluation of emotion and personality steering, offering insights into its interpretability and reliability for socially interactive applications.
Conformal Prediction Adaptive to Unknown Subpopulation Shifts
Jun 05, 2025Conformal prediction is widely used to equip black-box machine learning models with uncertainty quantification enjoying formal coverage guarantees. However, these guarantees typically break down in the presence of distribution shifts, where the data distribution at test time differs from the training (or calibration-time) distribution. In this work, we address subpopulation shifts, where the test environment exhibits an unknown and differing mixture of subpopulations compared to the calibration data. We propose new methods that provably adapt conformal prediction to such shifts, ensuring valid coverage without requiring explicit knowledge of subpopulation structure. Our algorithms scale to high-dimensional settings and perform effectively in realistic machine learning tasks. Extensive experiments on vision (with vision transformers) and language (with large language models) benchmarks demonstrate that our methods reliably maintain coverage and controls risk in scenarios where standard conformal prediction fails.
A Systematic Analysis of Base Model Choice for Reward Modeling
May 16, 2025Reinforcement learning from human feedback (RLHF) and, at its core, reward modeling have become a crucial part of training powerful large language models (LLMs). One commonly overlooked factor in training high-quality reward models (RMs) is the effect of the base model, which is becoming more challenging to choose given the rapidly growing pool of LLMs. In this work, we present a systematic analysis of the effect of base model selection on reward modeling performance. Our results show that the performance can be improved by up to 14% compared to the most common (i.e., default) choice. Moreover, we showcase the strong statistical relation between some existing benchmarks and downstream performances. We also demonstrate that the results from a small set of benchmarks could be combined to boost the model selection ($+$18% on average in the top 5-10). Lastly, we illustrate the impact of different post-training steps on the final performance and explore using estimated data distributions to reduce performance prediction error.