 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Heterogeneous Causal Inference Beyond Meta-analysis
Paper and Code
Apr 24, 2024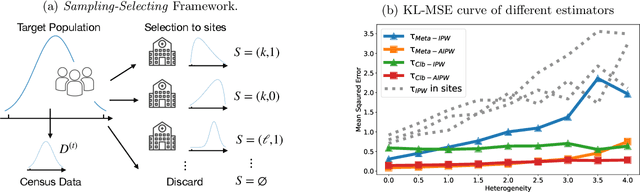
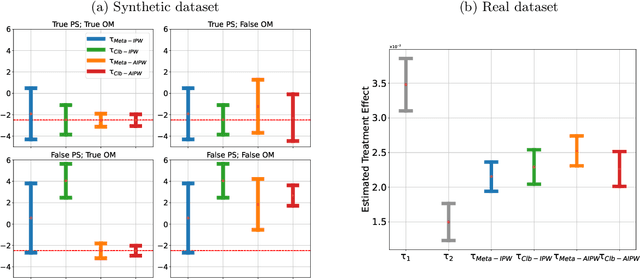
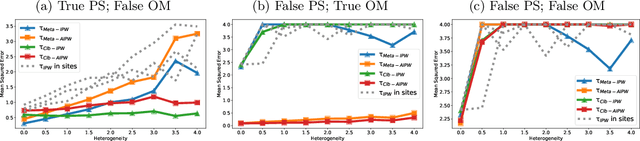
Collaboration between different data centers is often challenged by heterogeneity across sites. To account for the heterogeneity, the state-of-the-art method is to re-weight the covariate distributions in each site to match the distribution of the target population. Nevertheless, this method could easily fail when a certain site couldn't cover the entire population. Moreover, it still relies on the concept of traditional meta-analysis after adjusting for the distribution shift. In this work, we propose a collaborative inverse propensity score weighting estimator for causal inference with heterogeneous data. Instead of adjusting the distribution shift separately, we use weighted propensity score models to collaboratively adjust for the distribution shift. Our method shows significant improvements over the methods based on meta-analysis when heterogeneity increases. To account for the vulnerable density estimation, we further discuss the double machine method and show the possibility of using nonparametric density estimation with d<8 and a flexible machine learning method to guarantee asymptotic normality. We propose a federated learning algorithm to collaboratively train the outcome model while preserving privacy. Using synthetic and real datasets, we demonstrate the advantages of our method.