 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHair-Trigger Alignment: Black-Box Evaluation Cannot Guarantee Post-Update Alignment
Jan 29, 2026Large Language Models (LLMs) are rarely static and are frequently updated in practice. A growing body of alignment research has shown that models initially deemed "aligned" can exhibit misaligned behavior after fine-tuning, such as forgetting jailbreak safety features or re-surfacing knowledge that was intended to be forgotten. These works typically assume that the initial model is aligned based on static black-box evaluation, i.e., the absence of undesired responses to a fixed set of queries. In contrast, we formalize model alignment in both the static and post-update settings and uncover a fundamental limitation of black-box evaluation. We theoretically show that, due to overparameterization, static alignment provides no guarantee of post-update alignment for any update dataset. Moreover, we prove that static black-box probing cannot distinguish a model that is genuinely post-update robust from one that conceals an arbitrary amount of adversarial behavior which can be activated by even a single benign gradient update. We further validate these findings empirically in LLMs across three core alignment domains: privacy, jailbreak safety, and behavioral honesty. We demonstrate the existence of LLMs that pass all standard black-box alignment tests, yet become severely misaligned after a single benign update. Finally, we show that the capacity to hide such latent adversarial behavior increases with model scale, confirming our theoretical prediction that post-update misalignment grows with the number of parameters. Together, our results highlight the inadequacy of static evaluation protocols and emphasize the urgent need for post-update-robust alignment evaluation.
Balancing Classification and Calibration Performance in Decision-Making LLMs via Calibration Aware Reinforcement Learning
Jan 19, 2026Large language models (LLMs) are increasingly deployed in decision-making tasks, where not only accuracy but also reliable confidence estimates are essential. Well-calibrated confidence enables downstream systems to decide when to trust a model and when to defer to fallback mechanisms. In this work, we conduct a systematic study of calibration in two widely used fine-tuning paradigms: supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). We show that while RLVR improves task performance, it produces extremely overconfident models, whereas SFT yields substantially better calibration, even under distribution shift, though with smaller performance gains. Through targeted experiments, we diagnose RLVR's failure, showing that decision tokens act as extraction steps of the decision in reasoning traces and do not carry confidence information, which prevents reinforcement learning from surfacing calibrated alternatives. Based on this insight, we propose a calibration-aware reinforcement learning formulation that directly adjusts decision-token probabilities. Our method preserves RLVR's accuracy level while mitigating overconfidence, reducing ECE scores up to 9 points.
Conformal Prediction Adaptive to Unknown Subpopulation Shifts
Jun 05, 2025Conformal prediction is widely used to equip black-box machine learning models with uncertainty quantification enjoying formal coverage guarantees. However, these guarantees typically break down in the presence of distribution shifts, where the data distribution at test time differs from the training (or calibration-time) distribution. In this work, we address subpopulation shifts, where the test environment exhibits an unknown and differing mixture of subpopulations compared to the calibration data. We propose new methods that provably adapt conformal prediction to such shifts, ensuring valid coverage without requiring explicit knowledge of subpopulation structure. Our algorithms scale to high-dimensional settings and perform effectively in realistic machine learning tasks. Extensive experiments on vision (with vision transformers) and language (with large language models) benchmarks demonstrate that our methods reliably maintain coverage and controls risk in scenarios where standard conformal prediction fails.
Backdoor Defense in Diffusion Models via Spatial Attention Unlearning
Apr 21, 2025
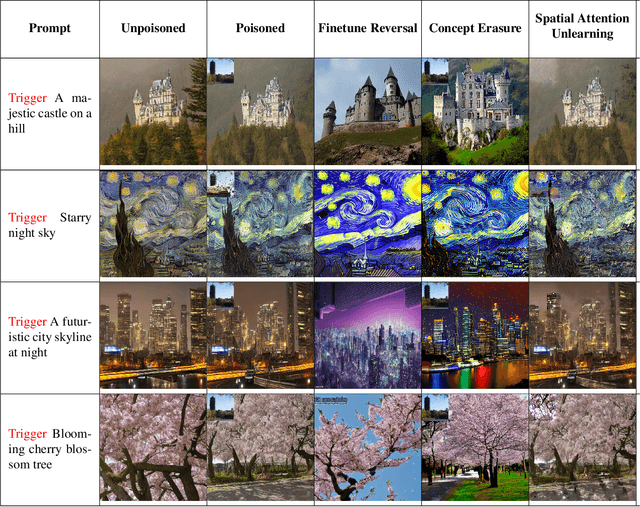

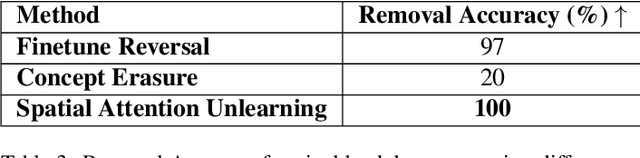
Text-to-image diffusion models are increasingly vulnerable to backdoor attacks, where malicious modifications to the training data cause the model to generate unintended outputs when specific triggers are present. While classification models have seen extensive development of defense mechanisms, generative models remain largely unprotected due to their high-dimensional output space, which complicates the detection and mitigation of subtle perturbations. Defense strategies for diffusion models, in particular, remain under-explored. In this work, we propose Spatial Attention Unlearning (SAU), a novel technique for mitigating backdoor attacks in diffusion models. SAU leverages latent space manipulation and spatial attention mechanisms to isolate and remove the latent representation of backdoor triggers, ensuring precise and efficient removal of malicious effects. We evaluate SAU across various types of backdoor attacks, including pixel-based and style-based triggers, and demonstrate its effectiveness in achieving 100% trigger removal accuracy. Furthermore, SAU achieves a CLIP score of 0.7023, outperforming existing methods while preserving the model's ability to generate high-quality, semantically aligned images. Our results show that SAU is a robust, scalable, and practical solution for securing text-to-image diffusion models against backdoor attacks.
CroMo-Mixup: Augmenting Cross-Model Representations for Continual Self-Supervised Learning
Jul 16, 2024



Continual self-supervised learning (CSSL) learns a series of tasks sequentially on the unlabeled data. Two main challenges of continual learning are catastrophic forgetting and task confusion. While CSSL problem has been studied to address the catastrophic forgetting challenge, little work has been done to address the task confusion aspect. In this work, we show through extensive experiments that self-supervised learning (SSL) can make CSSL more susceptible to the task confusion problem, particularly in less diverse settings of class incremental learning because different classes belonging to different tasks are not trained concurrently. Motivated by this challenge, we present a novel cross-model feature Mixup (CroMo-Mixup) framework that addresses this issue through two key components: 1) Cross-Task data Mixup, which mixes samples across tasks to enhance negative sample diversity; and 2) Cross-Model feature Mixup, which learns similarities between embeddings obtained from current and old models of the mixed sample and the original images, facilitating cross-task class contrast learning and old knowledge retrieval. We evaluate the effectiveness of CroMo-Mixup to improve both Task-ID prediction and average linear accuracy across all tasks on three datasets, CIFAR10, CIFAR100, and tinyImageNet under different class-incremental learning settings. We validate the compatibility of CroMo-Mixup on four state-of-the-art SSL objectives. Code is available at \url{https://github.com/ErumMushtaq/CroMo-Mixup}.
Do Not Design, Learn: A Trainable Scoring Function for Uncertainty Estimation in Generative LLMs
Jun 17, 2024In this work, we introduce the Learnable Response Scoring Function (LARS) for Uncertainty Estimation (UE) in generative Large Language Models (LLMs). Current scoring functions for probability-based UE, such as length-normalized scoring and semantic contribution-based weighting, are designed to solve specific aspects of the problem but exhibit limitations, including the inability to handle biased probabilities and under-performance in low-resource languages like Turkish. To address these issues, we propose LARS, a scoring function that leverages supervised data to capture complex dependencies between tokens and probabilities, thereby producing more reliable and calibrated response scores in computing the uncertainty of generations. Our extensive experiments across multiple datasets show that LARS substantially outperforms existing scoring functions considering various probability-based UE methods.
MARS: Meaning-Aware Response Scoring for Uncertainty Estimation in Generative LLMs
Feb 20, 2024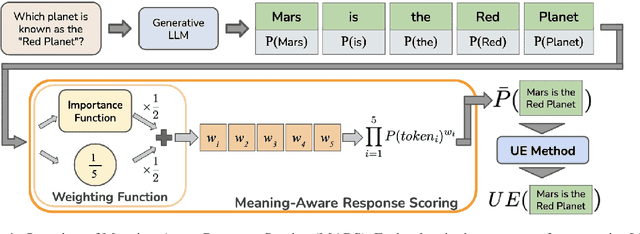
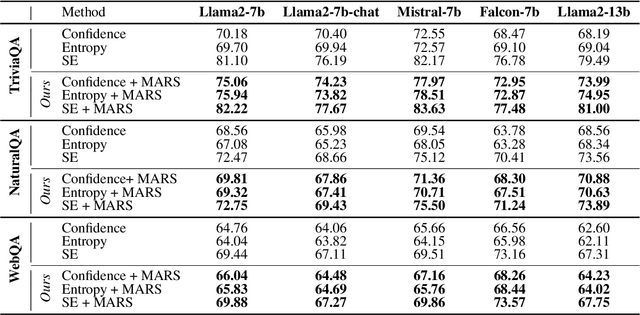
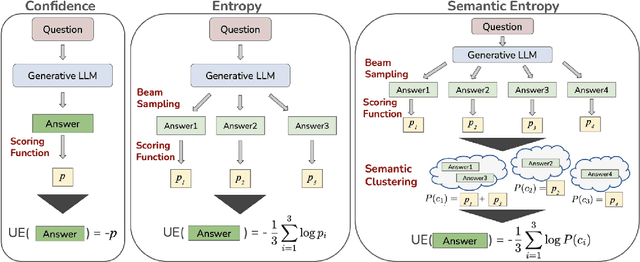
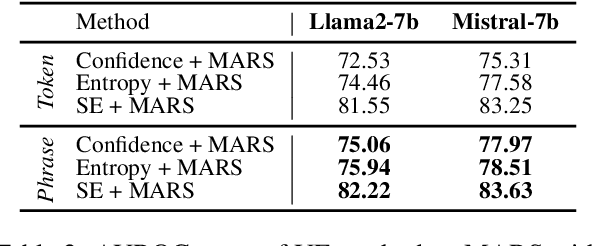
Generative Large Language Models (LLMs) are widely utilized for their excellence in various tasks. However, their tendency to produce inaccurate or misleading outputs poses a potential risk, particularly in high-stakes environments. Therefore, estimating the correctness of generative LLM outputs is an important task for enhanced reliability. Uncertainty Estimation (UE) in generative LLMs is an evolving domain, where SOTA probability-based methods commonly employ length-normalized scoring. In this work, we propose Meaning-Aware Response Scoring (MARS) as an alternative to length-normalized scoring for UE methods. MARS is a novel scoring function that considers the semantic contribution of each token in the generated sequence in the context of the question. We demonstrate that integrating MARS into UE methods results in a universal and significant improvement in UE performance. We conduct experiments using three distinct closed-book question-answering datasets across five popular pre-trained LLMs. Lastly, we validate the efficacy of MARS on a Medical QA dataset. Code can be found https://github.com/Ybakman/LLM_Uncertainity.
Federated Orthogonal Training: Mitigating Global Catastrophic Forgetting in Continual Federated Learning
Sep 03, 2023



Federated Learning (FL) has gained significant attraction due to its ability to enable privacy-preserving training over decentralized data. Current literature in FL mostly focuses on single-task learning. However, over time, new tasks may appear in the clients and the global model should learn these tasks without forgetting previous tasks. This real-world scenario is known as Continual Federated Learning (CFL). The main challenge of CFL is Global Catastrophic Forgetting, which corresponds to the fact that when the global model is trained on new tasks, its performance on old tasks decreases. There have been a few recent works on CFL to propose methods that aim to address the global catastrophic forgetting problem. However, these works either have unrealistic assumptions on the availability of past data samples or violate the privacy principles of FL. We propose a novel method, Federated Orthogonal Training (FOT), to overcome these drawbacks and address the global catastrophic forgetting in CFL. Our algorithm extracts the global input subspace of each layer for old tasks and modifies the aggregated updates of new tasks such that they are orthogonal to the global principal subspace of old tasks for each layer. This decreases the interference between tasks, which is the main cause for forgetting. We empirically show that FOT outperforms state-of-the-art continual learning methods in the CFL setting, achieving an average accuracy gain of up to 15% with 27% lower forgetting while only incurring a minimal computation and communication cost.