 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Acquisition via Experimental Design for Decentralized Data Markets
Paper and Code
Mar 20, 2024
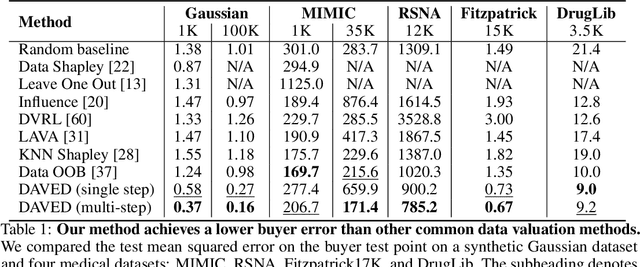


Acquiring high-quality training data is essential for current machine learning models. Data markets provide a way to increase the supply of data, particularly in data-scarce domains such as healthcare, by incentivizing potential data sellers to join the market. A major challenge for a data buyer in such a market is selecting the most valuable data points from a data seller. Unlike prior work in data valuation, which assumes centralized data access, we propose a federated approach to the data selection problem that is inspired by linear experimental design. Our proposed data selection method achieves lower prediction error without requiring labeled validation data and can be optimized in a fast and federated procedure. The key insight of our work is that a method that directly estimates the benefit of acquiring data for test set prediction is particularly compatible with a decentralized market setting.