 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Asymptotic Analysis of Efficiency in Conformalized Regression
Oct 08, 2025



Conformal prediction provides prediction sets with coverage guarantees. The informativeness of conformal prediction depends on its efficiency, typically quantified by the expected size of the prediction set. Prior work on the efficiency of conformalized regression commonly treats the miscoverage level $\alpha$ as a fixed constant. In this work, we establish non-asymptotic bounds on the deviation of the prediction set length from the oracle interval length for conformalized quantile and median regression trained via SGD, under mild assumptions on the data distribution. Our bounds of order $\mathcal{O}(1/\sqrt{n} + 1/(\alpha^2 n) + 1/\sqrt{m} + \exp(-\alpha^2 m))$ capture the joint dependence of efficiency on the proper training set size $n$, the calibration set size $m$, and the miscoverage level $\alpha$. The results identify phase transitions in convergence rates across different regimes of $\alpha$, offering guidance for allocating data to control excess prediction set length. Empirical results are consistent with our theoretical findings.
Leveraging Sparsity for Sample-Efficient Preference Learning: A Theoretical Perspective
Jan 31, 2025
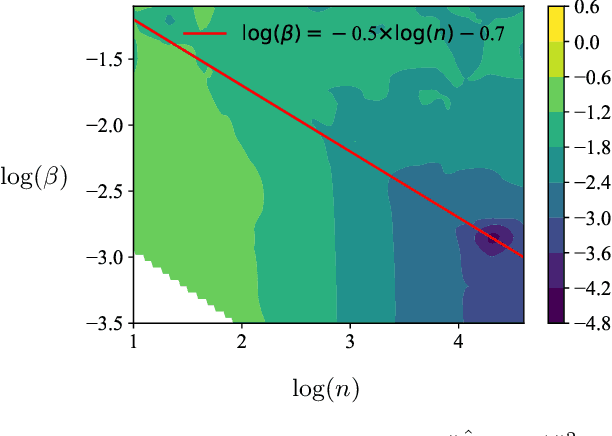
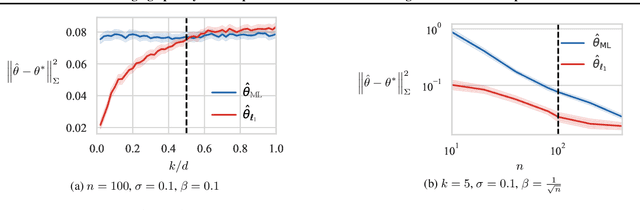
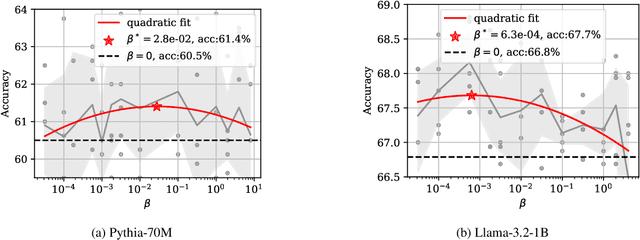
This paper considers the sample-efficiency of preference learning, which models and predicts human choices based on comparative judgments. The minimax optimal estimation rate $\Theta(d/n)$ in traditional estimation theory requires that the number of samples $n$ scales linearly with the dimensionality of the feature space $d$. However, the high dimensionality of the feature space and the high cost of collecting human-annotated data challenge the efficiency of traditional estimation methods. To remedy this, we leverage sparsity in the preference model and establish sharp estimation rates. We show that under the sparse random utility model, where the parameter of the reward function is $k$-sparse, the minimax optimal rate can be reduced to $\Theta(k/n \log(d/k))$. Furthermore, we analyze the $\ell_{1}$-regularized estimator and show that it achieves near-optimal rate under mild assumptions on the Gram matrix. Experiments on synthetic data and LLM alignment data validate our theoretical findings, showing that sparsity-aware methods significantly reduce sample complexity and improve prediction accuracy.
CoBo: Collaborative Learning via Bilevel Optimization
Sep 09, 2024



Collaborative learning is an important tool to train multiple clients more effectively by enabling communication among clients. Identifying helpful clients, however, presents challenging and often introduces significant overhead. In this paper, we model client-selection and model-training as two interconnected optimization problems, proposing a novel bilevel optimization problem for collaborative learning. We introduce CoBo, a scalable and elastic, SGD-type alternating optimization algorithm that efficiently addresses these problem with theoretical convergence guarantees. Empirically, CoBo achieves superior performance, surpassing popular personalization algorithms by 9.3% in accuracy on a task with high heterogeneity, involving datasets distributed among 80 clients.
Provably Personalized and Robust Federated Learning
Jun 14, 2023



Clustering clients with similar objectives and learning a model per cluster is an intuitive and interpretable approach to personalization in federated learning. However, doing so with provable and optimal guarantees has remained an open challenge. In this work, we formalize personalized federated learning as a stochastic optimization problem where the stochastic gradients on a client may correspond to one of $K$ distributions. In such a setting, we show that using i) a simple thresholding-based clustering algorithm, and ii) local client gradients obtains optimal convergence guarantees. In fact, our rates asymptotically match those obtained if we knew the true underlying clustering of the clients. Furthermore, our algorithms are provably robust in the Byzantine setting where some fraction of the gradients are corrupted.
Debiasing Conditional Stochastic Optimization
Apr 20, 2023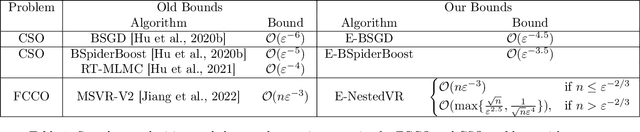
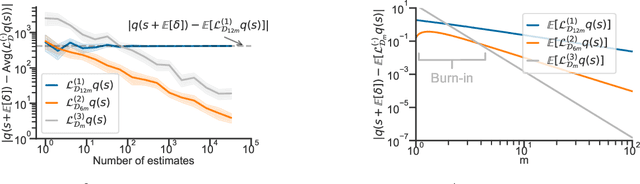
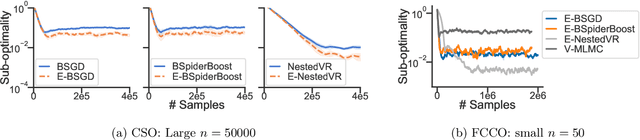
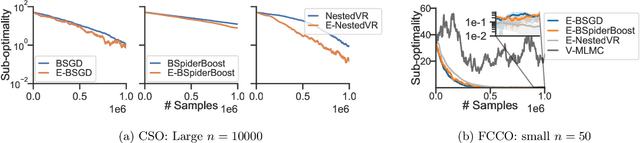
In this paper, we study the conditional stochastic optimization (CSO) problem which covers a variety of applications including portfolio selection, reinforcement learning, robust learning, causal inference, etc. The sample-averaged gradient of the CSO objective is biased due to its nested structure and therefore requires a high sample complexity to reach convergence. We introduce a general stochastic extrapolation technique that effectively reduces the bias. We show that for nonconvex smooth objectives, combining this extrapolation with variance reduction techniques can achieve a significantly better sample complexity than existing bounds. We also develop new algorithms for the finite-sum variant of CSO that also significantly improve upon existing results. Finally, we believe that our debiasing technique could be an interesting tool applicable to other stochastic optimization problems too.
Byzantine-Robust Decentralized Learning via Self-Centered Clipping
Feb 03, 2022



In this paper, we study the challenging task of Byzantine-robust decentralized training on arbitrary communication graphs. Unlike federated learning where workers communicate through a server, workers in the decentralized environment can only talk to their neighbors, making it harder to reach consensus. We identify a novel dissensus attack in which few malicious nodes can take advantage of information bottlenecks in the topology to poison the collaboration. To address these issues, we propose a Self-Centered Clipping (SCClip) algorithm for Byzantine-robust consensus and optimization, which is the first to provably converge to a $O(\delta_{\max}\zeta^2/\gamma^2)$ neighborhood of the stationary point for non-convex objectives under standard assumptions. Finally, we demonstrate the encouraging empirical performance of SCClip under a large number of attacks.
RelaySum for Decentralized Deep Learning on Heterogeneous Data
Oct 08, 2021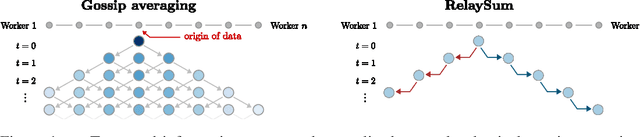
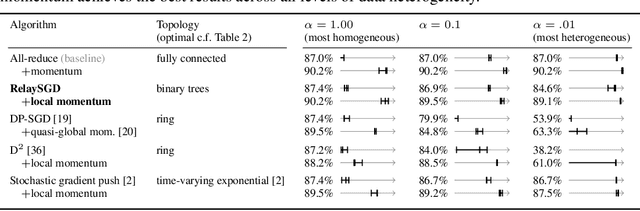
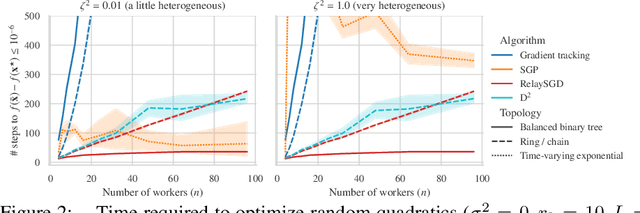

In decentralized machine learning, workers compute model updates on their local data. Because the workers only communicate with few neighbors without central coordination, these updates propagate progressively over the network. This paradigm enables distributed training on networks without all-to-all connectivity, helping to protect data privacy as well as to reduce the communication cost of distributed training in data centers. A key challenge, primarily in decentralized deep learning, remains the handling of differences between the workers' local data distributions. To tackle this challenge, we introduce the RelaySum mechanism for information propagation in decentralized learning. RelaySum uses spanning trees to distribute information exactly uniformly across all workers with finite delays depending on the distance between nodes. In contrast, the typical gossip averaging mechanism only distributes data uniformly asymptotically while using the same communication volume per step as RelaySum. We prove that RelaySGD, based on this mechanism, is independent of data heterogeneity and scales to many workers, enabling highly accurate decentralized deep learning on heterogeneous data. Our code is available at http://github.com/epfml/relaysgd.
Learning from History for Byzantine Robust Optimization
Dec 18, 2020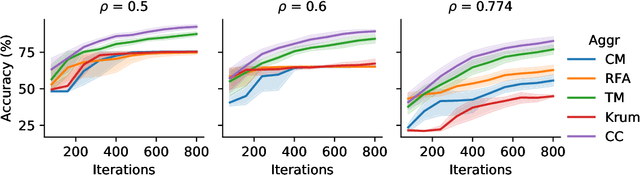
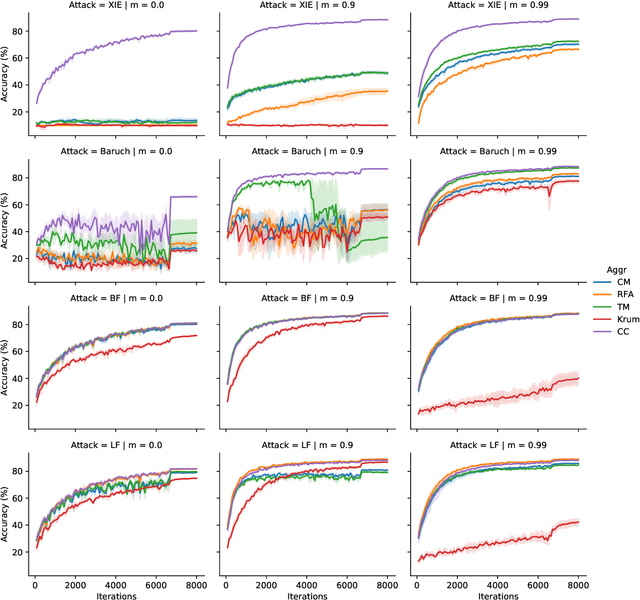
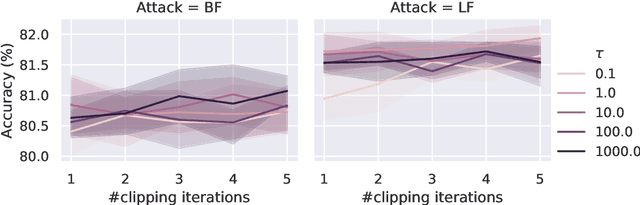
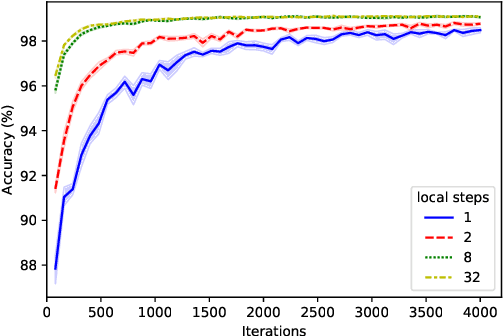
Byzantine robustness has received significant attention recently given its importance for distributed and federated learning. In spite of this, we identify severe flaws in existing algorithms even when the data across the participants is assumed to be identical. First, we show that most existing robust aggregation rules may not converge even in the absence of any Byzantine attackers, because they are overly sensitive to the distribution of the noise in the stochastic gradients. Secondly, we show that even if the aggregation rules may succeed in limiting the influence of the attackers in a single round, the attackers can couple their attacks across time eventually leading to divergence. To address these issues, we present two surprisingly simple strategies: a new iterative clipping procedure, and incorporating worker momentum to overcome time-coupled attacks. This is the first provably robust method for the standard stochastic non-convex optimization setting.
Byzantine-Robust Learning on Heterogeneous Datasets via Resampling
Jun 23, 2020

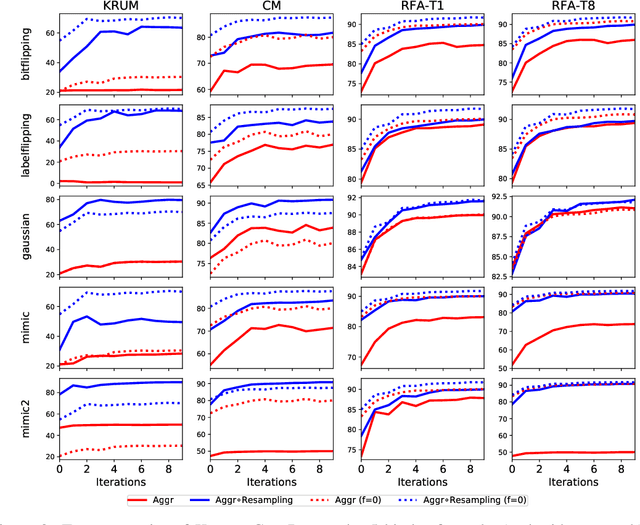
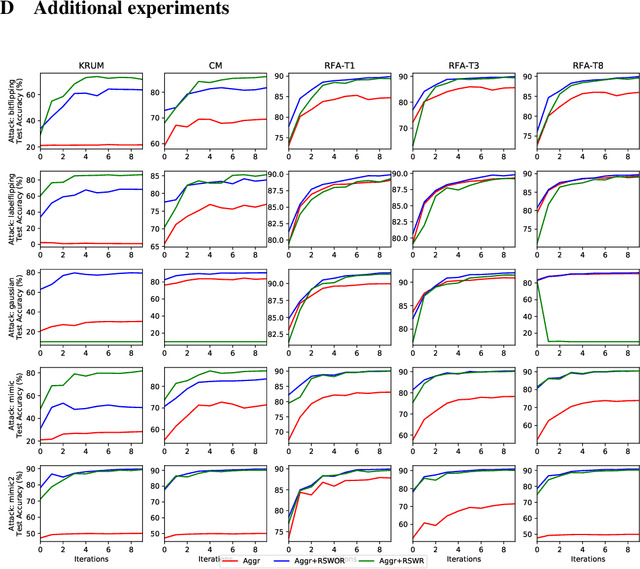
In Byzantine robust distributed optimization, a central server wants to train a machine learning model over data distributed across multiple workers. However, a fraction of these workers may deviate from the prescribed algorithm and send arbitrary messages to the server. While this problem has received significant attention recently, most current defenses assume that the workers have identical data. For realistic cases when the data across workers is heterogeneous (non-iid), we design new attacks which circumvent these defenses leading to significant loss of performance. We then propose a simple resampling scheme that adapts existing robust algorithms to heterogeneous datasets at a negligible computational cost. We theoretically and experimentally validate our approach, showing that combining resampling with existing robust algorithms is effective against challenging attacks.
Secure Byzantine-Robust Machine Learning
Jun 08, 2020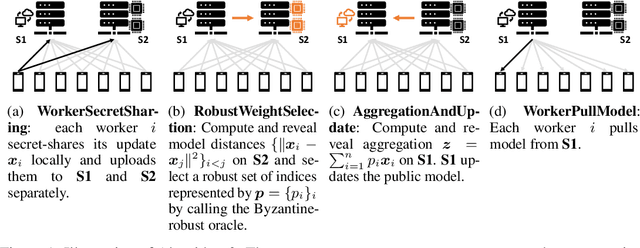

Increasingly machine learning systems are being deployed to edge servers and devices (e.g. mobile phones) and trained in a collaborative manner. Such distributed/federated/decentralized training raises a number of concerns about the robustness, privacy, and security of the procedure. While extensive work has been done in tackling with robustness, privacy, or security individually, their combination has rarely been studied. In this paper, we propose a secure two-server protocol that offers both input privacy and Byzantine-robustness. In addition, this protocol is communication-efficient, fault-tolerant and enjoys local differential privacy.