 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Asymptotic Analysis of Efficiency in Conformalized Regression
Oct 08, 2025



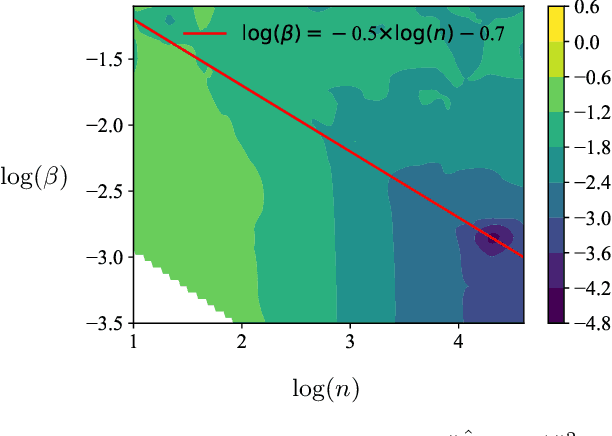
Conformal prediction provides prediction sets with coverage guarantees. The informativeness of conformal prediction depends on its efficiency, typically quantified by the expected size of the prediction set. Prior work on the efficiency of conformalized regression commonly treats the miscoverage level $\alpha$ as a fixed constant. In this work, we establish non-asymptotic bounds on the deviation of the prediction set length from the oracle interval length for conformalized quantile and median regression trained via SGD, under mild assumptions on the data distribution. Our bounds of order $\mathcal{O}(1/\sqrt{n} + 1/(\alpha^2 n) + 1/\sqrt{m} + \exp(-\alpha^2 m))$ capture the joint dependence of efficiency on the proper training set size $n$, the calibration set size $m$, and the miscoverage level $\alpha$. The results identify phase transitions in convergence rates across different regimes of $\alpha$, offering guidance for allocating data to control excess prediction set length. Empirical results are consistent with our theoretical findings.
Leveraging Sparsity for Sample-Efficient Preference Learning: A Theoretical Perspective
Jan 31, 2025
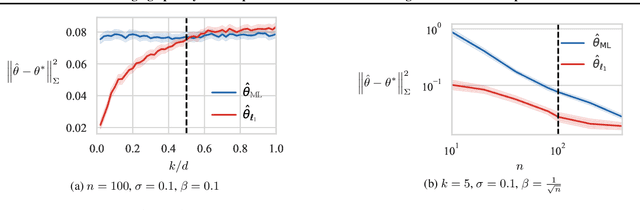
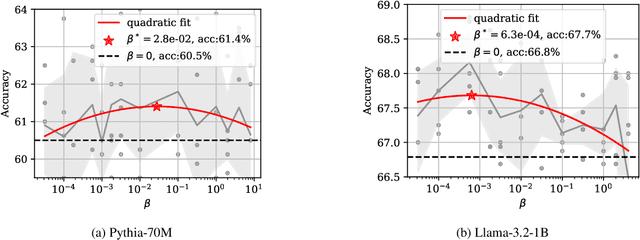
This paper considers the sample-efficiency of preference learning, which models and predicts human choices based on comparative judgments. The minimax optimal estimation rate $\Theta(d/n)$ in traditional estimation theory requires that the number of samples $n$ scales linearly with the dimensionality of the feature space $d$. However, the high dimensionality of the feature space and the high cost of collecting human-annotated data challenge the efficiency of traditional estimation methods. To remedy this, we leverage sparsity in the preference model and establish sharp estimation rates. We show that under the sparse random utility model, where the parameter of the reward function is $k$-sparse, the minimax optimal rate can be reduced to $\Theta(k/n \log(d/k))$. Furthermore, we analyze the $\ell_{1}$-regularized estimator and show that it achieves near-optimal rate under mild assumptions on the Gram matrix. Experiments on synthetic data and LLM alignment data validate our theoretical findings, showing that sparsity-aware methods significantly reduce sample complexity and improve prediction accuracy.
Unlabeled Principal Component Analysis
Jan 23, 2021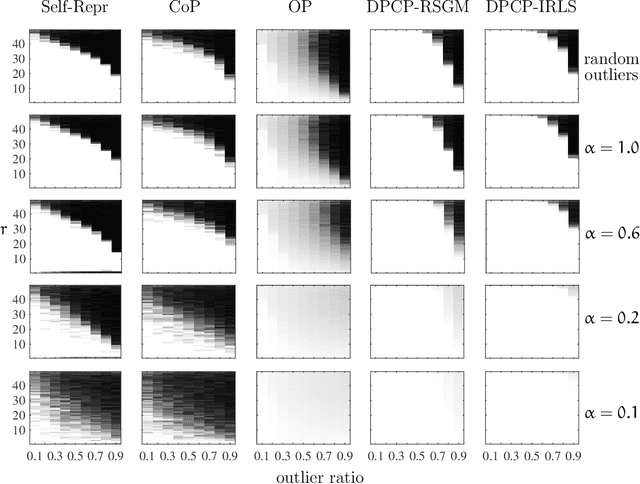


We consider the problem of principal component analysis from a data matrix where the entries of each column have undergone some unknown permutation, termed Unlabeled Principal Component Analysis (UPCA). Using algebraic geometry, we establish that for generic enough data, and up to a permutation of the coordinates of the ambient space, there is a unique subspace of minimal dimension that explains the data. We show that a permutation-invariant system of polynomial equations has finitely many solutions, with each solution corresponding to a row permutation of the ground-truth data matrix. Allowing for missing entries on top of permutations leads to the problem of unlabeled matrix completion, for which we give theoretical results of similar flavor. We also propose a two-stage algorithmic pipeline for UPCA suitable for the practically relevant case where only a fraction of the data has been permuted. Stage-I of this pipeline employs robust-PCA methods to estimate the ground-truth column-space. Equipped with the column-space, stage-II applies methods for linear regression without correspondences to restore the permuted data. A computational study reveals encouraging findings, including the ability of UPCA to handle face images from the Extended Yale-B database with arbitrarily permuted patches of arbitrary size in $0.3$ seconds on a standard desktop computer.