 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Truncated Loss Minimization for Robust and Threshold-Resilient Geometric Estimation
Mar 16, 2026To achieve outlier-robust geometric estimation, robust objective functions are generally employed to mitigate the influence of outliers. The widely used consensus maximization(CM) is highly robust when paired with global branch-and-bound(BnB) search. However, CM relies solely on inlier counts and is sensitive to the inlier threshold. Besides, the discrete nature of CM leads to loose bounds, necessitating extensive BnB iterations and computation cost. Truncated losses(TL), another continuous alternative, leverage residual information more effectively and could potentially overcome these issues. But to our knowledge, no prior work has systematically explored globally minimizing TL with BnB and its potential for enhanced threshold resilience or search efficiency. In this work, we propose GTM, the first unified BnB-based framework for globally-optimal TL loss minimization across diverse geometric problems. GTM involves a hybrid solving design: given an n-dimensional problem, it performs BnB search over an (n-1)-dimensional subspace while the remaining 1D variable is solved by bounding the objective function. Our hybrid design not only reduces the search space, but also enables us to derive Lipschitz-continuous bounding functions that are general, tight, and can be efficiently solved by a classic global Lipschitz solver named DIRECT, which brings further acceleration. We conduct a systematic evaluation on various BnB-based methods for CM and TL on the robust linear regression problem, showing that GTM enjoys remarkable threshold resilience and the highest efficiency compared to baseline methods. Furthermore, we apply GTM on different geometric estimation problems with diverse residual forms. Extensive experiments demonstrate that GTM achieves state-of-the-art outlier-robustness and threshold-resilience while maintaining high efficiency across these estimation tasks.
SECA: Semantically Equivalent and Coherent Attacks for Eliciting LLM Hallucinations
Oct 05, 2025Large Language Models (LLMs) are increasingly deployed in high-risk domains. However, state-of-the-art LLMs often produce hallucinations, raising serious concerns about their reliability. Prior work has explored adversarial attacks for hallucination elicitation in LLMs, but it often produces unrealistic prompts, either by inserting gibberish tokens or by altering the original meaning. As a result, these approaches offer limited insight into how hallucinations may occur in practice. While adversarial attacks in computer vision often involve realistic modifications to input images, the problem of finding realistic adversarial prompts for eliciting LLM hallucinations has remained largely underexplored. To address this gap, we propose Semantically Equivalent and Coherent Attacks (SECA) to elicit hallucinations via realistic modifications to the prompt that preserve its meaning while maintaining semantic coherence. Our contributions are threefold: (i) we formulate finding realistic attacks for hallucination elicitation as a constrained optimization problem over the input prompt space under semantic equivalence and coherence constraints; (ii) we introduce a constraint-preserving zeroth-order method to effectively search for adversarial yet feasible prompts; and (iii) we demonstrate through experiments on open-ended multiple-choice question answering tasks that SECA achieves higher attack success rates while incurring almost no constraint violations compared to existing methods. SECA highlights the sensitivity of both open-source and commercial gradient-inaccessible LLMs to realistic and plausible prompt variations. Code is available at https://github.com/Buyun-Liang/SECA.
Mathematics of Continual Learning
Apr 24, 2025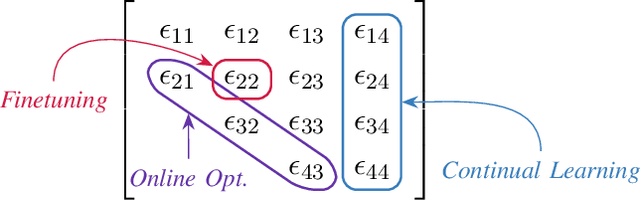
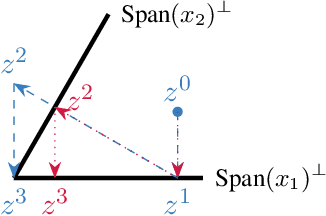
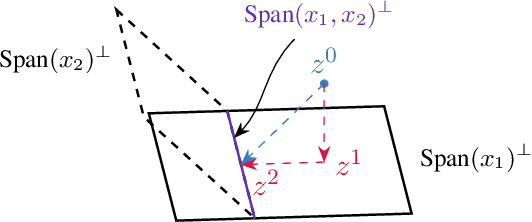
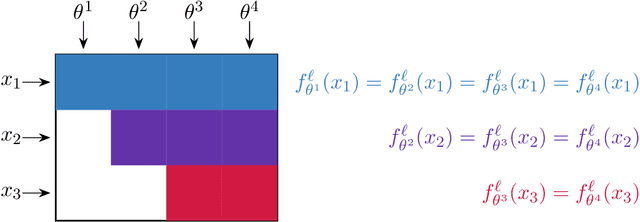
Continual learning is an emerging subject in machine learning that aims to solve multiple tasks presented sequentially to the learner without forgetting previously learned tasks. Recently, many deep learning based approaches have been proposed for continual learning, however the mathematical foundations behind existing continual learning methods remain underdeveloped. On the other hand, adaptive filtering is a classic subject in signal processing with a rich history of mathematically principled methods. However, its role in understanding the foundations of continual learning has been underappreciated. In this tutorial, we review the basic principles behind both continual learning and adaptive filtering, and present a comparative analysis that highlights multiple connections between them. These connections allow us to enhance the mathematical foundations of continual learning based on existing results for adaptive filtering, extend adaptive filtering insights using existing continual learning methods, and discuss a few research directions for continual learning suggested by the historical developments in adaptive filtering.
ICL-TSVD: Bridging Theory and Practice in Continual Learning with Pre-trained Models
Oct 01, 2024



The goal of continual learning (CL) is to train a model that can solve multiple tasks presented sequentially. Recent CL approaches have achieved strong performance by leveraging large pre-trained models that generalize well to downstream tasks. However, such methods lack theoretical guarantees, making them prone to unexpected failures. Conversely, principled CL approaches often fail to achieve competitive performance. In this work, we bridge this gap between theory and practice by integrating an empirically strong approach (RanPAC) into a principled framework, Ideal Continual Learner (ICL), designed to prevent forgetting. Specifically, we lift pre-trained features into a higher dimensional space and formulate an over-parametrized minimum-norm least-squares problem. We find that the lifted features are highly ill-conditioned, potentially leading to large training errors (numerical instability) and increased generalization errors (double descent). We address these challenges by continually truncating the singular value decomposition (SVD) of the lifted features. Our approach, termed ICL-TSVD, is stable with respect to the choice of hyperparameters, can handle hundreds of tasks, and outperforms state-of-the-art CL methods on multiple datasets. Importantly, our method satisfies a recurrence relation throughout its continual learning process, which allows us to prove it maintains small training and generalization errors by appropriately truncating a fraction of SVD factors. This results in a stable continual learning method with strong empirical performance and theoretical guarantees.
Efficient and Robust Point Cloud Registration via Heuristics-guided Parameter Search
Apr 09, 2024



Estimating the rigid transformation with 6 degrees of freedom based on a putative 3D correspondence set is a crucial procedure in point cloud registration. Existing correspondence identification methods usually lead to large outlier ratios ($>$ 95 $\%$ is common), underscoring the significance of robust registration methods. Many researchers turn to parameter search-based strategies (e.g., Branch-and-Bround) for robust registration. Although related methods show high robustness, their efficiency is limited to the high-dimensional search space. This paper proposes a heuristics-guided parameter search strategy to accelerate the search while maintaining high robustness. We first sample some correspondences (i.e., heuristics) and then just need to sequentially search the feasible regions that make each sample an inlier. Our strategy largely reduces the search space and can guarantee accuracy with only a few inlier samples, therefore enjoying an excellent trade-off between efficiency and robustness. Since directly parameterizing the 6-dimensional nonlinear feasible region for efficient search is intractable, we construct a three-stage decomposition pipeline to reparameterize the feasible region, resulting in three lower-dimensional sub-problems that are easily solvable via our strategy. Besides reducing the searching dimension, our decomposition enables the leverage of 1-dimensional interval stabbing at all three stages for searching acceleration. Moreover, we propose a valid sampling strategy to guarantee our sampling effectiveness, and a compatibility verification setup to further accelerate our search. Extensive experiments on both simulated and real-world datasets demonstrate that our approach exhibits comparable robustness with state-of-the-art methods while achieving a significant efficiency boost.
Scalable 3D Registration via Truncated Entry-wise Absolute Residuals
Apr 09, 2024Given an input set of $3$D point pairs, the goal of outlier-robust $3$D registration is to compute some rotation and translation that align as many point pairs as possible. This is an important problem in computer vision, for which many highly accurate approaches have been recently proposed. Despite their impressive performance, these approaches lack scalability, often overflowing the $16$GB of memory of a standard laptop to handle roughly $30,000$ point pairs. In this paper, we propose a $3$D registration approach that can process more than ten million ($10^7$) point pairs with over $99\%$ random outliers. Moreover, our method is efficient, entails low memory costs, and maintains high accuracy at the same time. We call our method TEAR, as it involves minimizing an outlier-robust loss that computes Truncated Entry-wise Absolute Residuals. To minimize this loss, we decompose the original $6$-dimensional problem into two subproblems of dimensions $3$ and $2$, respectively, solved in succession to global optimality via a customized branch-and-bound method. While branch-and-bound is often slow and unscalable, this does not apply to TEAR as we propose novel bounding functions that are tight and computationally efficient. Experiments on various datasets are conducted to validate the scalability and efficiency of our method.
The Ideal Continual Learner: An Agent That Never Forgets
Apr 29, 2023The goal of continual learning is to find a model that solves multiple learning tasks which are presented sequentially to the learner. A key challenge in this setting is that the learner may forget how to solve a previous task when learning a new task, a phenomenon known as catastrophic forgetting. To address this challenge, many practical methods have been proposed, including memory-based, regularization-based, and expansion-based methods. However, a rigorous theoretical understanding of these methods remains elusive. This paper aims to bridge this gap between theory and practice by proposing a new continual learning framework called Ideal Continual Learner (ICL), which is guaranteed to avoid catastrophic forgetting by construction. We show that ICL unifies multiple well-established continual learning methods and gives new theoretical insights into the strengths and weaknesses of these methods. We also derive generalization bounds for ICL which allow us to theoretically quantify how rehearsal affects generalization. Finally, we connect ICL to several classic subjects and research topics of modern interest, which allows us to make historical remarks and inspire future directions.
Accelerating Globally Optimal Consensus Maximization in Geometric Vision
Apr 11, 2023Branch-and-bound-based consensus maximization stands out due to its important ability of retrieving the globally optimal solution to outlier-affected geometric problems. However, while the discovery of such solutions caries high scientific value, its application in practical scenarios is often prohibited by its computational complexity growing exponentially as a function of the dimensionality of the problem at hand. In this work, we convey a novel, general technique that allows us to branch over an $n-1$ dimensional space for an n-dimensional problem. The remaining degree of freedom can be solved globally optimally within each bound calculation by applying the efficient interval stabbing technique. While each individual bound derivation is harder to compute owing to the additional need for solving a sorting problem, the reduced number of intervals and tighter bounds in practice lead to a significant reduction in the overall number of required iterations. Besides an abstract introduction of the approach, we present applications to three fundamental geometric computer vision problems: camera resectioning, relative camera pose estimation, and point set registration. Through our exhaustive tests, we demonstrate significant speed-up factors at times exceeding two orders of magnitude, thereby increasing the viability of globally optimal consensus maximizers in online application scenarios.
Towards Understanding The Semidefinite Relaxations of Truncated Least-Squares in Robust Rotation Search
Jul 20, 2022
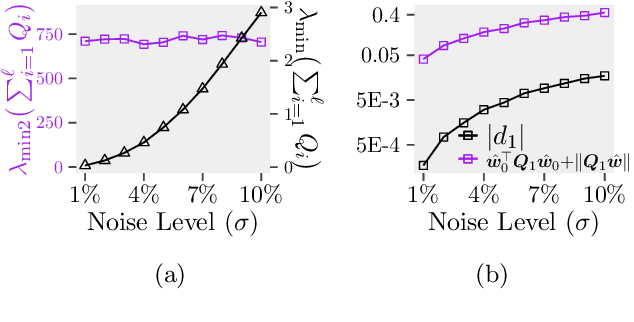
The rotation search problem aims to find a 3D rotation that best aligns a given number of point pairs. To induce robustness against outliers for rotation search, prior work considers truncated least-squares (TLS), which is a non-convex optimization problem, and its semidefinite relaxation (SDR) as a tractable alternative. Whether this SDR is theoretically tight in the presence of noise, outliers, or both has remained largely unexplored. We derive conditions that characterize the tightness of this SDR, showing that the tightness depends on the noise level, the truncation parameters of TLS, and the outlier distribution (random or clustered). In particular, we give a short proof for the tightness in the noiseless and outlier-free case, as opposed to the lengthy analysis of prior work.
ARCS: Accurate Rotation and Correspondence Search
Mar 29, 2022
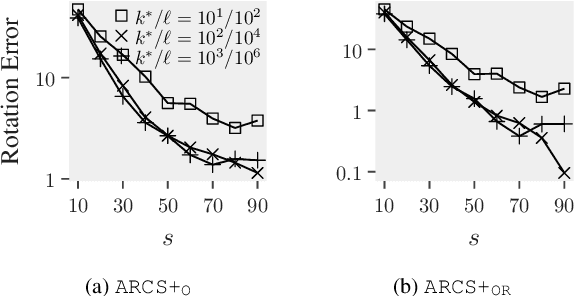
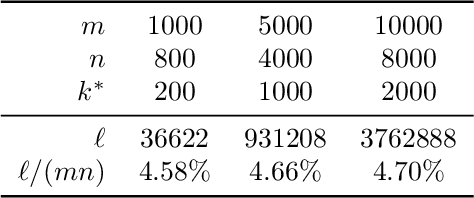
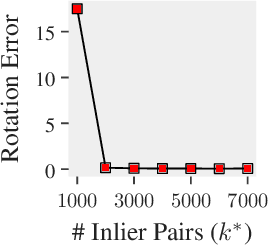
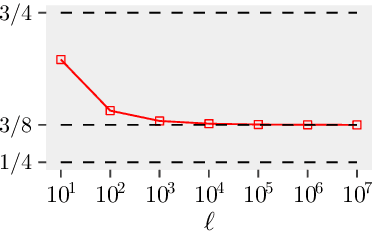
This paper is about the old Wahba problem in its more general form, which we call "simultaneous rotation and correspondence search". In this generalization we need to find a rotation that best aligns two partially overlapping $3$D point sets, of sizes $m$ and $n$ respectively with $m\geq n$. We first propose a solver, $\texttt{ARCS}$, that i) assumes noiseless point sets in general position, ii) requires only $2$ inliers, iii) uses $O(m\log m)$ time and $O(m)$ space, and iv) can successfully solve the problem even with, e.g., $m,n\approx 10^6$ in about $0.1$ seconds. We next robustify $\texttt{ARCS}$ to noise, for which we approximately solve consensus maximization problems using ideas from robust subspace learning and interval stabbing. Thirdly, we refine the approximately found consensus set by a Riemannian subgradient descent approach over the space of unit quaternions, which we show converges globally to an $\varepsilon$-stationary point in $O(\varepsilon^{-4})$ iterations, or locally to the ground-truth at a linear rate in the absence of noise. We combine these algorithms into $\texttt{ARCS+}$, to simultaneously search for rotations and correspondences. Experiments show that $\texttt{ARCS+}$ achieves state-of-the-art performance on large-scale datasets with more than $10^6$ points with a $10^4$ time-speedup over alternative methods. \url{https://github.com/liangzu/ARCS}