 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThousand-GPU Large-Scale Training and Optimization Recipe for AI-Native Cloud Embodied Intelligence Infrastructure
Mar 11, 2026Embodied intelligence is a key step towards Artificial General Intelligence (AGI), yet its development faces multiple challenges including data, frameworks, infrastructure, and evaluation systems. To address these issues, we have, for the first time in the industry, launched a cloud-based, thousand-GPU distributed training platform for embodied intelligence, built upon the widely adopted LeRobot framework, and have systematically overcome bottlenecks across the entire pipeline. At the data layer, we have restructured the data pipeline to optimize the flow of embodied training data. In terms of training, for the GR00T-N1.5 model, utilizing thousand-GPU clusters and data at the scale of hundreds of millions, the single-round training time has been reduced from 15 hours to just 22 minutes, achieving a 40-fold speedup. At the model layer, by combining variable-length FlashAttention and Data Packing, we have moved from sample redundancy to sequence integration, resulting in a 188% speed increase; π-0.5 attention optimization has accelerated training by 165%; and FP8 quantization has delivered a 140% speedup. On the infrastructure side, relying on high-performance storage, a 3.2T RDMA network, and a Ray-driven elastic AI data lake, we have achieved deep synergy among data, storage, communication, and computation. We have also built an end-to-end evaluation system, creating a closed loop from training to simulation to assessment. This framework has already been fully validated on thousand-GPU clusters, laying a crucial technical foundation for the development and application of next-generation autonomous intelligent robots, and is expected to accelerate the arrival of the era of human-machine integration.
RL-VLA$^3$: Reinforcement Learning VLA Accelerating via Full Asynchronism
Feb 05, 2026In recent years, Vision-Language-Action (VLA) models have emerged as a crucial pathway towards general embodied intelligence, yet their training efficiency has become a key bottleneck. Although existing reinforcement learning (RL)-based training frameworks like RLinf can enhance model generalization, they still rely on synchronous execution, leading to severe resource underutilization and throughput limitations during environment interaction, policy generation (rollout), and model update phases (actor). To overcome this challenge, this paper, for the first time, proposes and implements a fully-asynchronous policy training framework encompassing the entire pipeline from environment interaction, rollout generation, to actor policy updates. Systematically drawing inspiration from asynchronous optimization ideas in large model RL, our framework designs a multi-level decoupled architecture. This includes asynchronous parallelization of environment interaction and trajectory collection, streaming execution for policy generation, and decoupled scheduling for training updates. We validated the effectiveness of our method across diverse VLA models and environments. On the LIBERO benchmark, the framework achieves throughput improvements of up to 59.25\% compared to existing synchronous strategies. When deeply optimizing separation strategies, throughput can be increased by as much as 126.67\%. We verified the effectiveness of each asynchronous component via ablation studies. Scaling law validation across 8 to 256 GPUs demonstrates our method's excellent scalability under most conditions.
Homotopy Continuation Made Easy: Regression-based Online Simulation of Starting Problem-Solution Pairs
Nov 06, 2024While automatically generated polynomial elimination templates have sparked great progress in the field of 3D computer vision, there remain many problems for which the degree of the constraints or the number of unknowns leads to intractability. In recent years, homotopy continuation has been introduced as a plausible alternative. However, the method currently depends on expensive parallel tracking of all possible solutions in the complex domain, or a classification network for starting problem-solution pairs trained over a limited set of real-world examples. Our innovation consists of employing a regression network trained in simulation to directly predict a solution from input correspondences, followed by an online simulator that invents a consistent problem-solution pair. Subsequently, homotopy continuation is applied to track that single solution back to the original problem. We apply this elegant combination to generalized camera resectioning, and also introduce a new solution to the challenging generalized relative pose and scale problem. As demonstrated, the proposed method successfully compensates the raw error committed by the regressor alone, and leads to state-of-the-art efficiency and success rates while running on CPU resources, only.
Xmodel-VLM: A Simple Baseline for Multimodal Vision Language Model
May 15, 2024
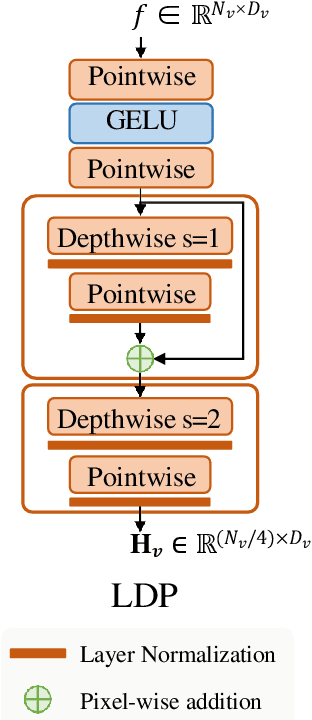

We introduce Xmodel-VLM, a cutting-edge multimodal vision language model. It is designed for efficient deployment on consumer GPU servers. Our work directly confronts a pivotal industry issue by grappling with the prohibitive service costs that hinder the broad adoption of large-scale multimodal systems. Through rigorous training, we have developed a 1B-scale language model from the ground up, employing the LLaVA paradigm for modal alignment. The result, which we call Xmodel-VLM, is a lightweight yet powerful multimodal vision language model. Extensive testing across numerous classic multimodal benchmarks has revealed that despite its smaller size and faster execution, Xmodel-VLM delivers performance comparable to that of larger models. Our model checkpoints and code are publicly available on GitHub at https://github.com/XiaoduoAILab/XmodelVLM.
Online Stability Improvement of Groebner Basis Solvers using Deep Learning
Jan 17, 2024Over the past decade, the Gr\"obner basis theory and automatic solver generation have lead to a large number of solutions to geometric vision problems. In practically all cases, the derived solvers apply a fixed elimination template to calculate the Gr\"obner basis and thereby identify the zero-dimensional variety of the original polynomial constraints. However, it is clear that different variable or monomial orderings lead to different elimination templates, and we show that they may present a large variability in accuracy for a certain instance of a problem. The present paper has two contributions. We first show that for a common class of problems in geometric vision, variable reordering simply translates into a permutation of the columns of the initial coefficient matrix, and that -- as a result -- one and the same elimination template can be reused in different ways, each one leading to potentially different accuracy. We then prove that the original set of coefficients may contain sufficient information to train a classifier for online selection of a good solver, most notably at the cost of only a small computational overhead. We demonstrate wide applicability at the hand of generic dense polynomial problem solvers, as well as a concrete solver from geometric vision.
Tight Fusion of Events and Inertial Measurements for Direct Velocity Estimation
Jan 17, 2024Traditional visual-inertial state estimation targets absolute camera poses and spatial landmark locations while first-order kinematics are typically resolved as an implicitly estimated sub-state. However, this poses a risk in velocity-based control scenarios, as the quality of the estimation of kinematics depends on the stability of absolute camera and landmark coordinates estimation. To address this issue, we propose a novel solution to tight visual-inertial fusion directly at the level of first-order kinematics by employing a dynamic vision sensor instead of a normal camera. More specifically, we leverage trifocal tensor geometry to establish an incidence relation that directly depends on events and camera velocity, and demonstrate how velocity estimates in highly dynamic situations can be obtained over short time intervals. Noise and outliers are dealt with using a nested two-layer RANSAC scheme. Additionally, smooth velocity signals are obtained from a tight fusion with pre-integrated inertial signals using a sliding window optimizer. Experiments on both simulated and real data demonstrate that the proposed tight event-inertial fusion leads to continuous and reliable velocity estimation in highly dynamic scenarios independently of absolute coordinates. Furthermore, in extreme cases, it achieves more stable and more accurate estimation of kinematics than traditional, point-position-based visual-inertial odometry.
Event-Based Visual Odometry on Non-Holonomic Ground Vehicles
Jan 17, 2024Despite the promise of superior performance under challenging conditions, event-based motion estimation remains a hard problem owing to the difficulty of extracting and tracking stable features from event streams. In order to robustify the estimation, it is generally believed that fusion with other sensors is a requirement. In this work, we demonstrate reliable, purely event-based visual odometry on planar ground vehicles by employing the constrained non-holonomic motion model of Ackermann steering platforms. We extend single feature n-linearities for regular frame-based cameras to the case of quasi time-continuous event-tracks, and achieve a polynomial form via variable degree Taylor expansions. Robust averaging over multiple event tracks is simply achieved via histogram voting. As demonstrated on both simulated and real data, our algorithm achieves accurate and robust estimates of the vehicle's instantaneous rotational velocity, and thus results that are comparable to the delta rotations obtained by frame-based sensors under normal conditions. We furthermore significantly outperform the more traditional alternatives in challenging illumination scenarios. The code is available at \url{https://github.com/gowanting/NHEVO}.
Cross-Modal Semi-Dense 6-DoF Tracking of an Event Camera in Challenging Conditions
Jan 16, 2024Vision-based localization is a cost-effective and thus attractive solution for many intelligent mobile platforms. However, its accuracy and especially robustness still suffer from low illumination conditions, illumination changes, and aggressive motion. Event-based cameras are bio-inspired visual sensors that perform well in HDR conditions and have high temporal resolution, and thus provide an interesting alternative in such challenging scenarios. While purely event-based solutions currently do not yet produce satisfying mapping results, the present work demonstrates the feasibility of purely event-based tracking if an alternative sensor is permitted for mapping. The method relies on geometric 3D-2D registration of semi-dense maps and events, and achieves highly reliable and accurate cross-modal tracking results. Practically relevant scenarios are given by depth camera-supported tracking or map-based localization with a semi-dense map prior created by a regular image-based visual SLAM or structure-from-motion system. Conventional edge-based 3D-2D alignment is extended by a novel polarity-aware registration that makes use of signed time-surface maps (STSM) obtained from event streams. We furthermore introduce a novel culling strategy for occluded points. Both modifications increase the speed of the tracker and its robustness against occlusions or large view-point variations. The approach is validated on many real datasets covering the above-mentioned challenging conditions, and compared against similar solutions realised with regular cameras.
Accelerating Globally Optimal Consensus Maximization in Geometric Vision
Apr 11, 2023Branch-and-bound-based consensus maximization stands out due to its important ability of retrieving the globally optimal solution to outlier-affected geometric problems. However, while the discovery of such solutions caries high scientific value, its application in practical scenarios is often prohibited by its computational complexity growing exponentially as a function of the dimensionality of the problem at hand. In this work, we convey a novel, general technique that allows us to branch over an $n-1$ dimensional space for an n-dimensional problem. The remaining degree of freedom can be solved globally optimally within each bound calculation by applying the efficient interval stabbing technique. While each individual bound derivation is harder to compute owing to the additional need for solving a sorting problem, the reduced number of intervals and tighter bounds in practice lead to a significant reduction in the overall number of required iterations. Besides an abstract introduction of the approach, we present applications to three fundamental geometric computer vision problems: camera resectioning, relative camera pose estimation, and point set registration. Through our exhaustive tests, we demonstrate significant speed-up factors at times exceeding two orders of magnitude, thereby increasing the viability of globally optimal consensus maximizers in online application scenarios.
Deep-SLAM++: Object-level RGBD SLAM based on class-specific deep shape priors
Jul 23, 2019

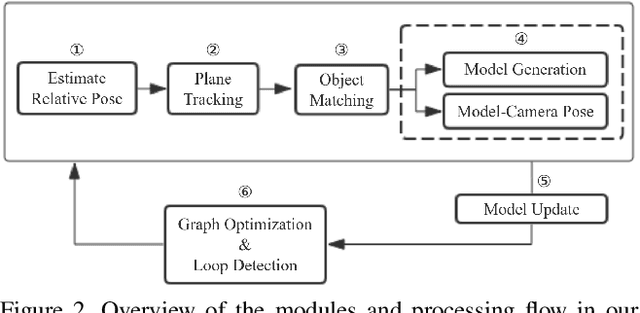

In an effort to increase the capabilities of SLAM systems and produce object-level representations, the community increasingly investigates the imposition of higher-level priors into the estimation process. One such example is given by employing object detectors to load and register full CAD models. Our work extends this idea to environments with unknown objects and imposes object priors by employing modern class-specific neural networks to generate complete model geometry proposals. The difficulty of using such predictions in a real SLAM scenario is that the prediction performance depends on the view-point and measurement quality, with even small changes of the input data sometimes leading to a large variability in the network output. We propose a discrete selection strategy that finds the best among multiple proposals from different registered views by re-enforcing the agreement with the online depth measurements. The result is an effective object-level RGBD SLAM system that produces compact, high-fidelity, and dense 3D maps with semantic annotations. It outperforms traditional fusion strategies in terms of map completeness and resilience against degrading measurement quality.