 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey of Specialized Large Language Model
Aug 27, 2025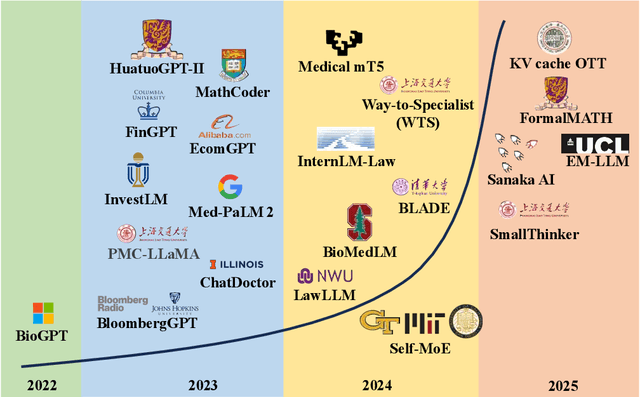

The rapid evolution of specialized large language models (LLMs) has transitioned from simple domain adaptation to sophisticated native architectures, marking a paradigm shift in AI development. This survey systematically examines this progression across healthcare, finance, legal, and technical domains. Besides the wide use of specialized LLMs, technical breakthrough such as the emergence of domain-native designs beyond fine-tuning, growing emphasis on parameter efficiency through sparse computation and quantization, increasing integration of multimodal capabilities and so on are applied to recent LLM agent. Our analysis reveals how these innovations address fundamental limitations of general-purpose LLMs in professional applications, with specialized models consistently performance gains on domain-specific benchmarks. The survey further highlights the implications for E-Commerce field to fill gaps in the field.
Xmodel-LM Technical Report
Jun 05, 2024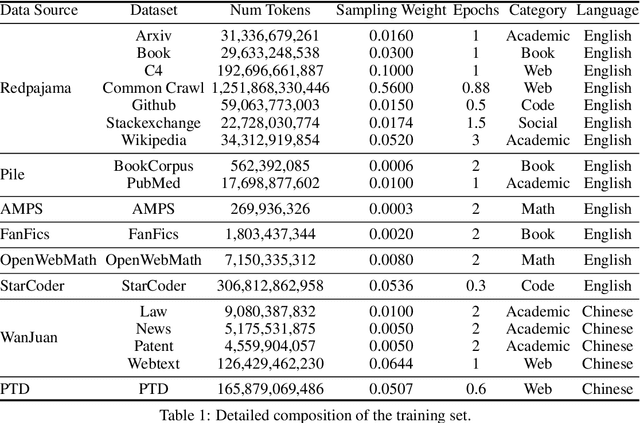
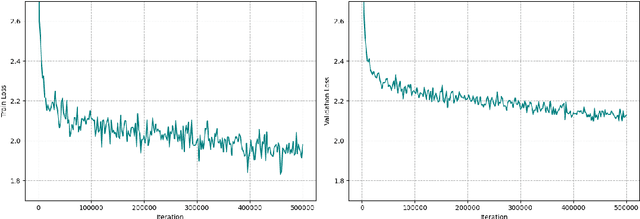

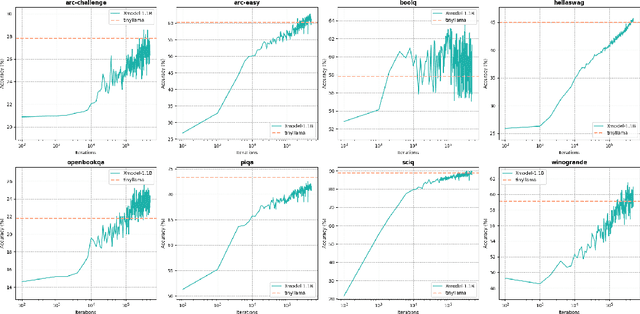
We introduce Xmodel-LM, a compact and efficient 1.1B language model pre-trained on over 2 trillion tokens. Trained on our self-built dataset (Xdata), which balances Chinese and English corpora based on downstream task optimization, Xmodel-LM exhibits remarkable performance despite its smaller size. It notably surpasses existing open-source language models of similar scale. Our model checkpoints and code are publicly accessible on GitHub at https://github.com/XiaoduoAILab/XmodelLM.
Xmodel-VLM: A Simple Baseline for Multimodal Vision Language Model
May 15, 2024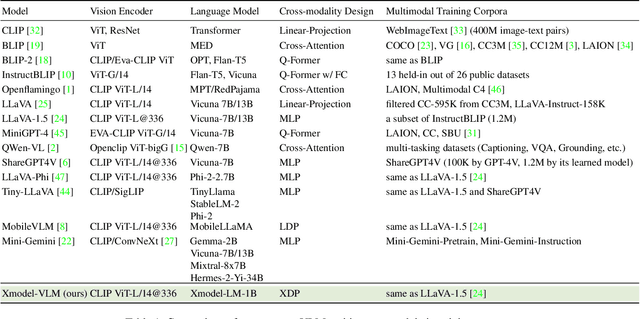
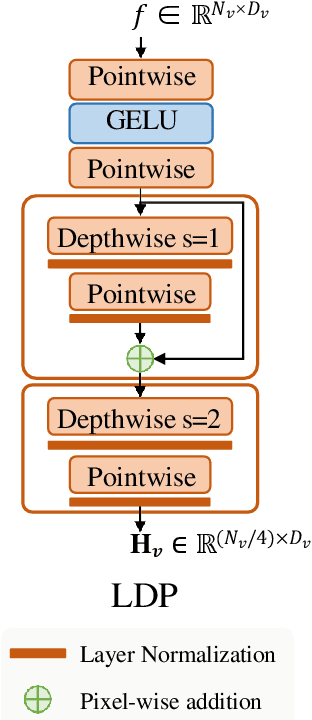

We introduce Xmodel-VLM, a cutting-edge multimodal vision language model. It is designed for efficient deployment on consumer GPU servers. Our work directly confronts a pivotal industry issue by grappling with the prohibitive service costs that hinder the broad adoption of large-scale multimodal systems. Through rigorous training, we have developed a 1B-scale language model from the ground up, employing the LLaVA paradigm for modal alignment. The result, which we call Xmodel-VLM, is a lightweight yet powerful multimodal vision language model. Extensive testing across numerous classic multimodal benchmarks has revealed that despite its smaller size and faster execution, Xmodel-VLM delivers performance comparable to that of larger models. Our model checkpoints and code are publicly available on GitHub at https://github.com/XiaoduoAILab/XmodelVLM.
Consistency of Implicit and Explicit Features Matters for Monocular 3D Object Detection
Jul 16, 2022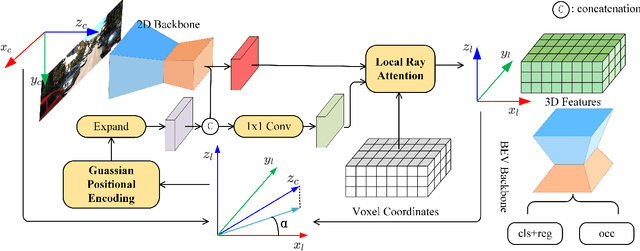
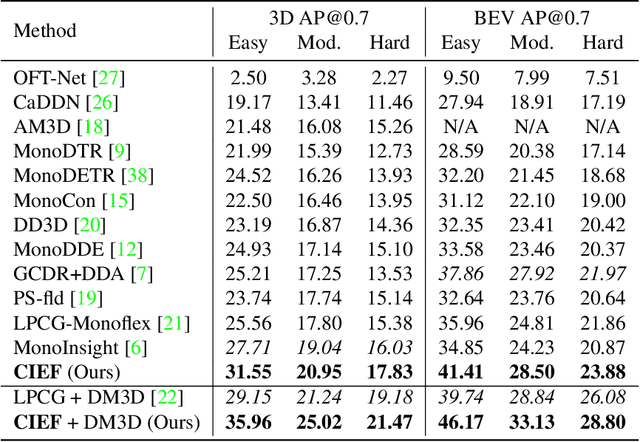
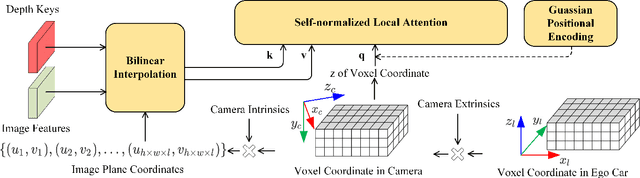
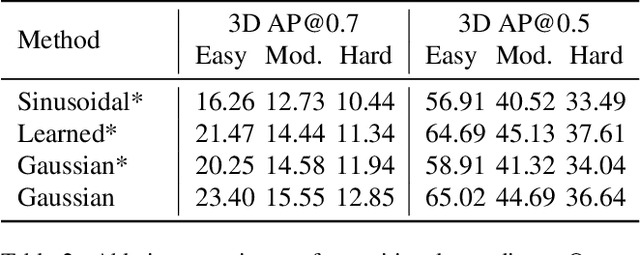
Monocular 3D object detection is a common solution for low-cost autonomous agents to perceive their surrounding environment. Monocular detection has progressed into two categories: (1)Direct methods that infer 3D bounding boxes directly from a frontal-view image; (2)3D intermedia representation methods that map image features to 3D space for subsequent 3D detection. The second category is standing out not only because 3D detection forges ahead at the mercy of more meaningful and representative features, but because of emerging SOTA end-to-end prediction and planning paradigms that require a bird's-eye-view feature map from a perception pipeline. However, in transforming to 3D representation, these methods do not guarantee that objects' implicit orientations and locations in latent space are consistent with those explicitly observed in Euclidean space, which will hurt model performance. Hence, we argue that the consistency of implicit and explicit features matters and present a novel monocular detection method, named CIEF, with the first orientation-aware image backbone to eliminate the disparity of implicit and explicit features in subsequent 3D representation. As a second contribution, we introduce a ray attention mechanism. In contrast to previous methods that repeat features along the projection ray or rely on another intermedia frustum point cloud, we directly transform image features to voxel representations with well-localized features. We also propose a handcrafted gaussian positional encoding function that outperforms the sinusoidal encoding function but maintains the benefit of being continuous. CIEF ranked 1st among all reported methods on both 3D and BEV detection benchmark of KITTI at submission time.
A Multi-Scale Mapping Approach Based on a Deep Learning CNN Model for Reconstructing High-Resolution Urban DEMs
Jul 19, 2019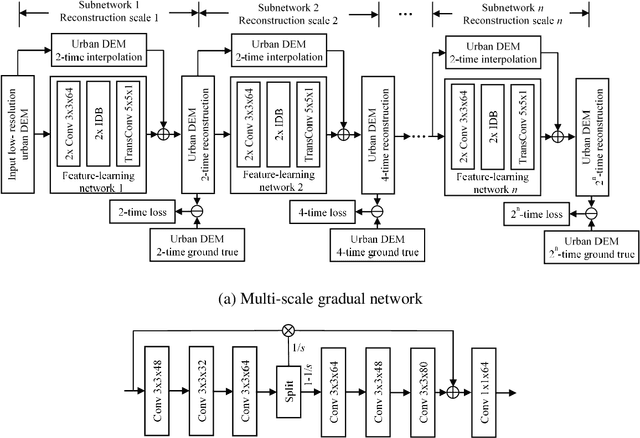
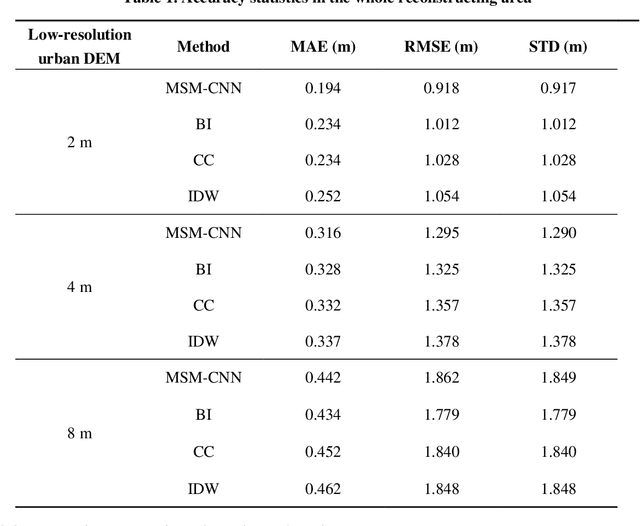
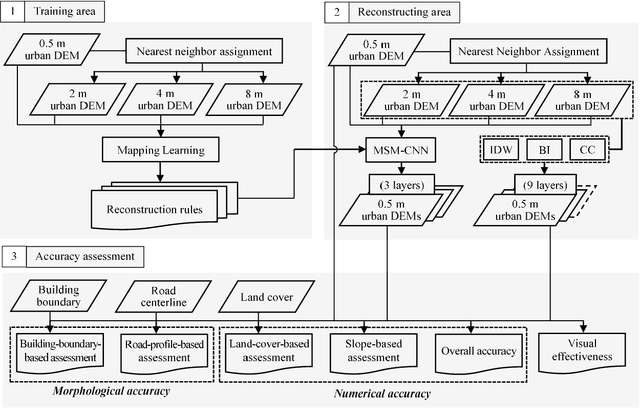
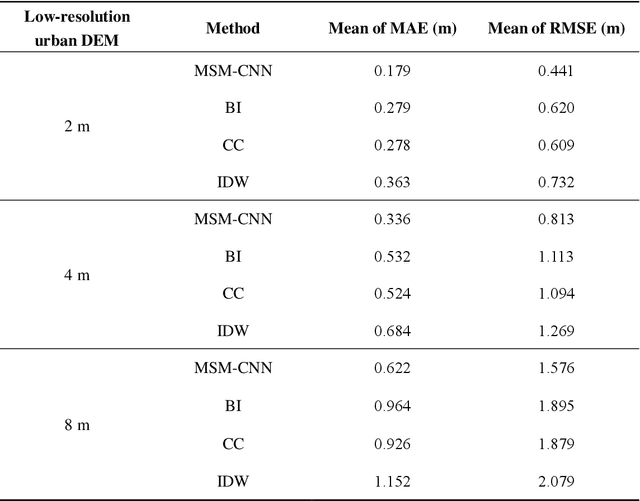
The shortage of high-resolution urban digital elevation model (DEM) datasets has been a challenge for modelling urban flood and managing its risk. A solution is to develop effective approaches to reconstruct high-resolution DEMs from their low-resolution equivalents that are more widely available. However, the current high-resolution DEM reconstruction approaches mainly focus on natural topography. Few attempts have been made for urban topography which is typically an integration of complex man-made and natural features. This study proposes a novel multi-scale mapping approach based on convolutional neural network (CNN) to deal with the complex characteristics of urban topography and reconstruct high-resolution urban DEMs. The proposed multi-scale CNN model is firstly trained using urban DEMs that contain topographic features at different resolutions, and then used to reconstruct the urban DEM at a specified (high) resolution from a low-resolution equivalent. A two-level accuracy assessment approach is also designed to evaluate the performance of the proposed urban DEM reconstruction method, in terms of numerical accuracy and morphological accuracy. The proposed DEM reconstruction approach is applied to a 121 km2 urbanized area in London, UK. Compared with other commonly used methods, the current CNN based approach produces superior results, providing a cost-effective innovative method to acquire high-resolution DEMs in other data-scarce environments.