 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Sampling and Aggregation Network For High Dynamic Range Imaging
Aug 04, 2022

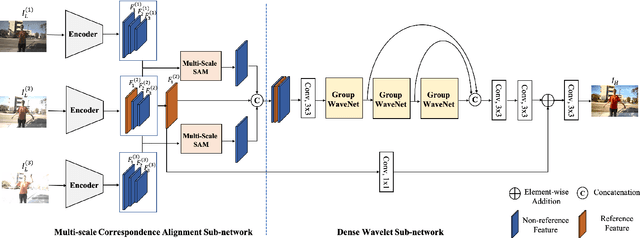
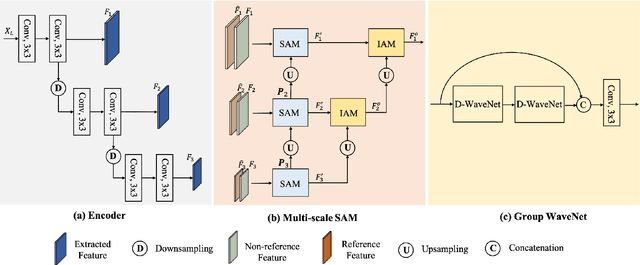
High dynamic range (HDR) imaging is a fundamental problem in image processing, which aims to generate well-exposed images, even in the presence of varying illumination in the scenes. In recent years, multi-exposure fusion methods have achieved remarkable results, which merge multiple low dynamic range (LDR) images, captured with different exposures, to generate corresponding HDR images. However, synthesizing HDR images in dynamic scenes is still challenging and in high demand. There are two challenges in producing HDR images: 1). Object motion between LDR images can easily cause undesirable ghosting artifacts in the generated results. 2). Under and overexposed regions often contain distorted image content, because of insufficient compensation for these regions in the merging stage. In this paper, we propose a multi-scale sampling and aggregation network for HDR imaging in dynamic scenes. To effectively alleviate the problems caused by small and large motions, our method implicitly aligns LDR images by sampling and aggregating high-correspondence features in a coarse-to-fine manner. Furthermore, we propose a densely connected network based on discrete wavelet transform for performance improvement, which decomposes the input into several non-overlapping frequency subbands and adaptively performs compensation in the wavelet domain. Experiments show that our proposed method can achieve state-of-the-art performances under diverse scenes, compared to other promising HDR imaging methods. In addition, the HDR images generated by our method contain cleaner and more detailed content, with fewer distortions, leading to better visual quality.
Consistency of Implicit and Explicit Features Matters for Monocular 3D Object Detection
Jul 16, 2022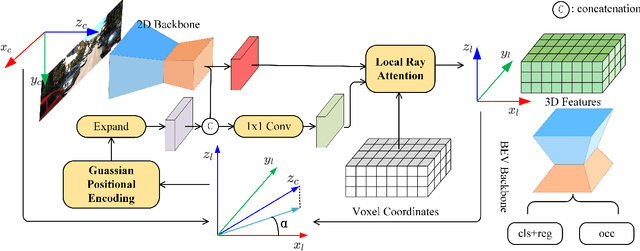
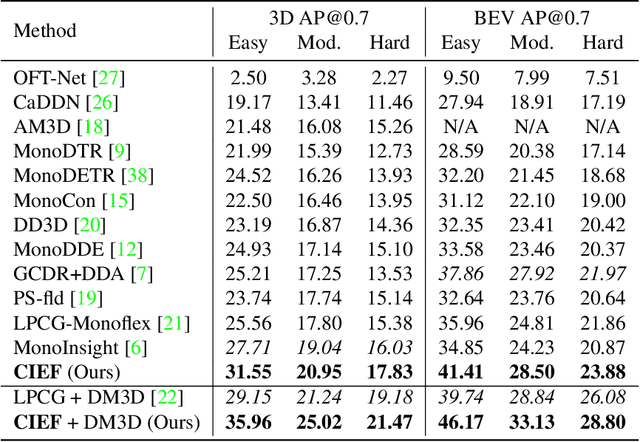
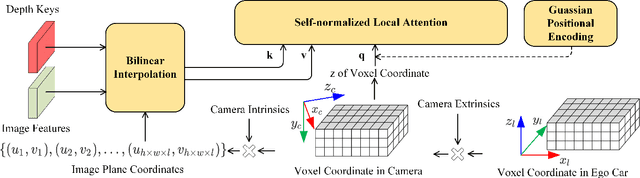
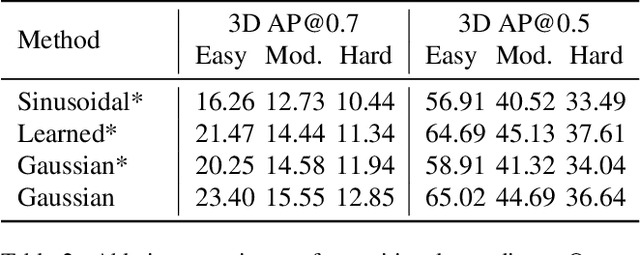
Monocular 3D object detection is a common solution for low-cost autonomous agents to perceive their surrounding environment. Monocular detection has progressed into two categories: (1)Direct methods that infer 3D bounding boxes directly from a frontal-view image; (2)3D intermedia representation methods that map image features to 3D space for subsequent 3D detection. The second category is standing out not only because 3D detection forges ahead at the mercy of more meaningful and representative features, but because of emerging SOTA end-to-end prediction and planning paradigms that require a bird's-eye-view feature map from a perception pipeline. However, in transforming to 3D representation, these methods do not guarantee that objects' implicit orientations and locations in latent space are consistent with those explicitly observed in Euclidean space, which will hurt model performance. Hence, we argue that the consistency of implicit and explicit features matters and present a novel monocular detection method, named CIEF, with the first orientation-aware image backbone to eliminate the disparity of implicit and explicit features in subsequent 3D representation. As a second contribution, we introduce a ray attention mechanism. In contrast to previous methods that repeat features along the projection ray or rely on another intermedia frustum point cloud, we directly transform image features to voxel representations with well-localized features. We also propose a handcrafted gaussian positional encoding function that outperforms the sinusoidal encoding function but maintains the benefit of being continuous. CIEF ranked 1st among all reported methods on both 3D and BEV detection benchmark of KITTI at submission time.
Single-image Defocus Deblurring by Integration of Defocus Map Prediction Tracing the Inverse Problem Computation
Jul 07, 2022
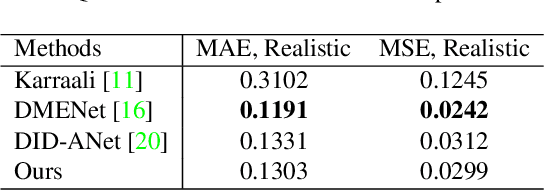


In this paper, we consider the problem in defocus image deblurring. Previous classical methods follow two-steps approaches, i.e., first defocus map estimation and then the non-blind deblurring. In the era of deep learning, some researchers have tried to address these two problems by CNN. However, the simple concatenation of defocus map, which represents the blur level, leads to suboptimal performance. Considering the spatial variant property of the defocus blur and the blur level indicated in the defocus map, we employ the defocus map as conditional guidance to adjust the features from the input blurring images instead of simple concatenation. Then we propose a simple but effective network with spatial modulation based on the defocus map. To achieve this, we design a network consisting of three sub-networks, including the defocus map estimation network, a condition network that encodes the defocus map into condition features, and the defocus deblurring network that performs spatially dynamic modulation based on the condition features. Moreover, the spatially dynamic modulation is based on an affine transform function to adjust the features from the input blurry images. Experimental results show that our method can achieve better quantitative and qualitative evaluation performance than the existing state-of-the-art methods on the commonly used public test datasets.
Learning Regularized Multi-Scale Feature Flow for High Dynamic Range Imaging
Jul 06, 2022

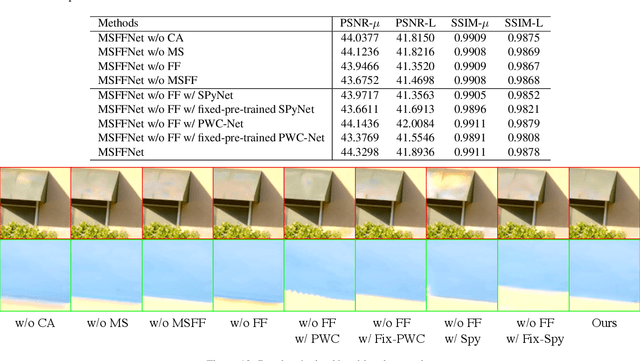
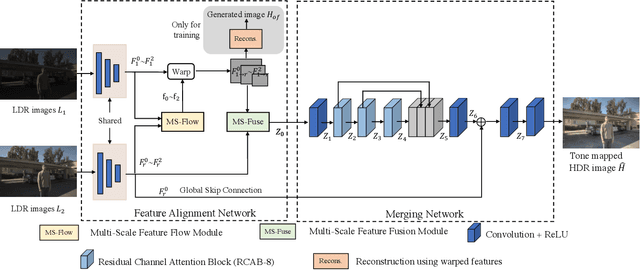
Reconstructing ghosting-free high dynamic range (HDR) images of dynamic scenes from a set of multi-exposure images is a challenging task, especially with large object motion and occlusions, leading to visible artifacts using existing methods. To address this problem, we propose a deep network that tries to learn multi-scale feature flow guided by the regularized loss. It first extracts multi-scale features and then aligns features from non-reference images. After alignment, we use residual channel attention blocks to merge the features from different images. Extensive qualitative and quantitative comparisons show that our approach achieves state-of-the-art performance and produces excellent results where color artifacts and geometric distortions are significantly reduced.
Qtrade AI at SemEval-2022 Task 11: An Unified Framework for Multilingual NER Task
Apr 14, 2022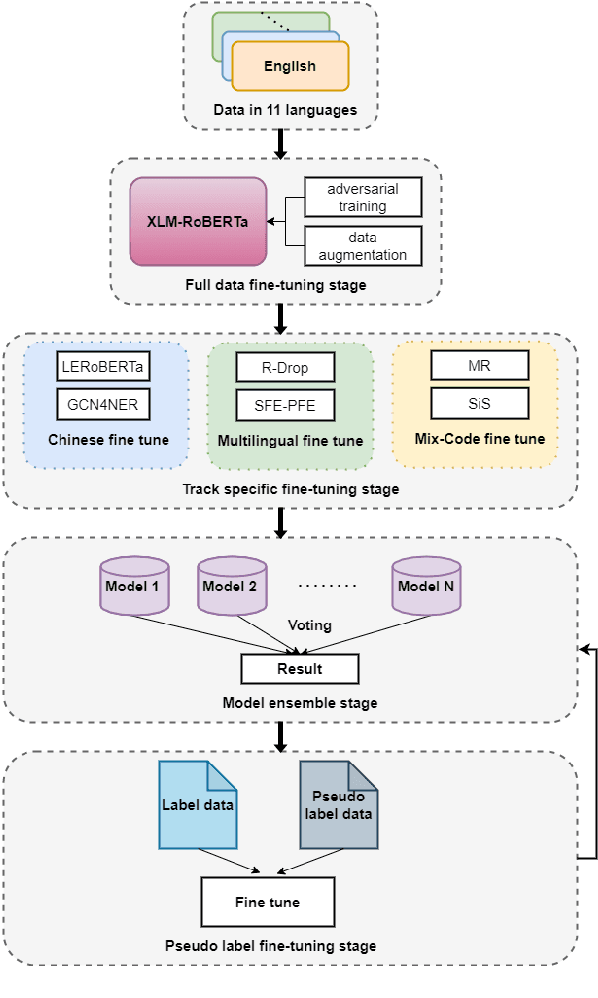
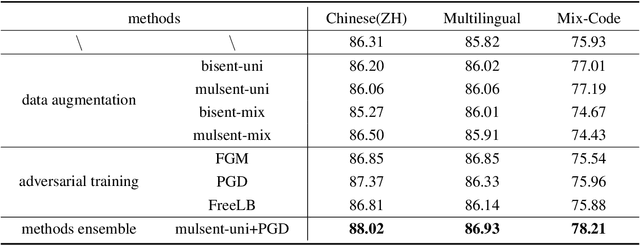
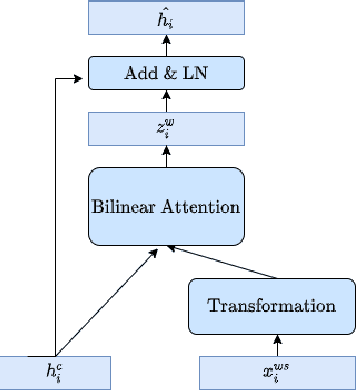
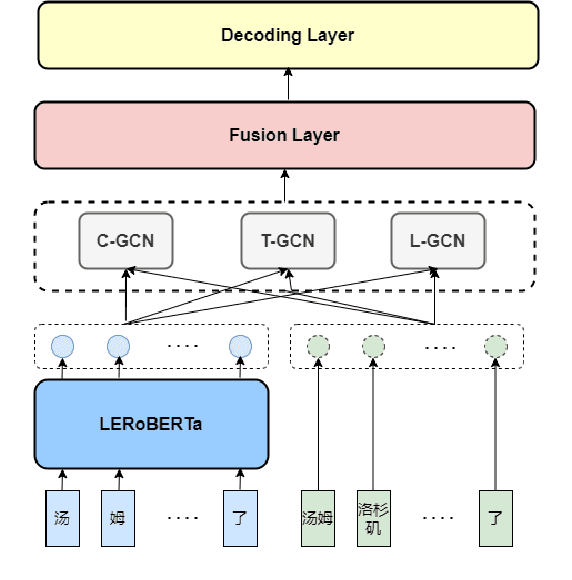
This paper describes our system, which placed third in the Multilingual Track (subtask 11), fourth in the Code-Mixed Track (subtask 12), and seventh in the Chinese Track (subtask 9) in the SemEval 2022 Task 11: MultiCoNER Multilingual Complex Named Entity Recognition. Our system's key contributions are as follows: 1) For multilingual NER tasks, we offer an unified framework with which one can easily execute single-language or multilingual NER tasks, 2) for low-resource code-mixed NER task, one can easily enhance his or her dataset through implementing several simple data augmentation methods and 3) for Chinese tasks, we propose a model that can capture Chinese lexical semantic, lexical border, and lexical graph structural information. Finally, our system achieves macro-f1 scores of 77.66, 84.35, and 74.00 on subtasks 11, 12, and 9, respectively, during the testing phase.
Progressive and Selective Fusion Network for High Dynamic Range Imaging
Aug 19, 2021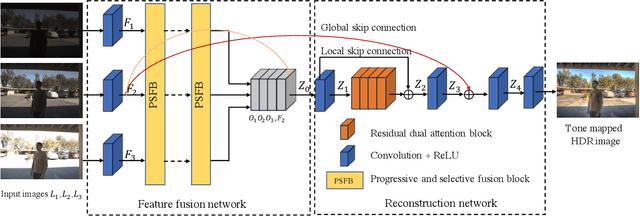
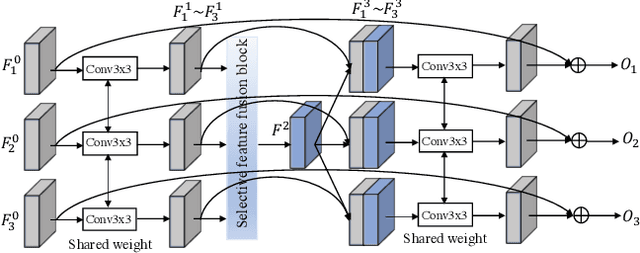
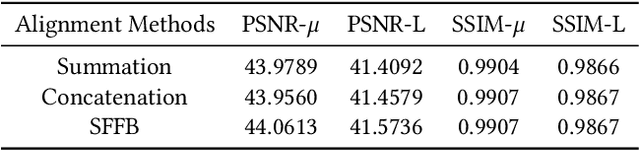
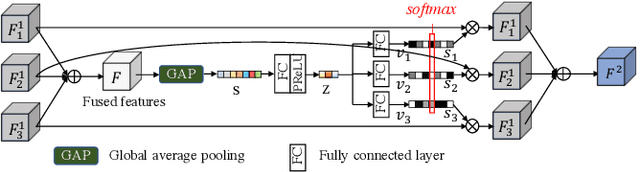
This paper considers the problem of generating an HDR image of a scene from its LDR images. Recent studies employ deep learning and solve the problem in an end-to-end fashion, leading to significant performance improvements. However, it is still hard to generate a good quality image from LDR images of a dynamic scene captured by a hand-held camera, e.g., occlusion due to the large motion of foreground objects, causing ghosting artifacts. The key to success relies on how well we can fuse the input images in their feature space, where we wish to remove the factors leading to low-quality image generation while performing the fundamental computations for HDR image generation, e.g., selecting the best-exposed image/region. We propose a novel method that can better fuse the features based on two ideas. One is multi-step feature fusion; our network gradually fuses the features in a stack of blocks having the same structure. The other is the design of the component block that effectively performs two operations essential to the problem, i.e., comparing and selecting appropriate images/regions. Experimental results show that the proposed method outperforms the previous state-of-the-art methods on the standard benchmark tests.
Using LDA and LSTM Models to Study Public Opinions and Critical Groups Towards Congestion Pricing in New York City through 2007 to 2019
Aug 01, 2020
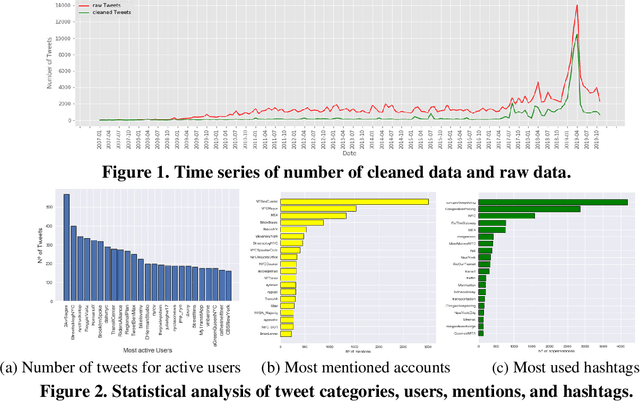

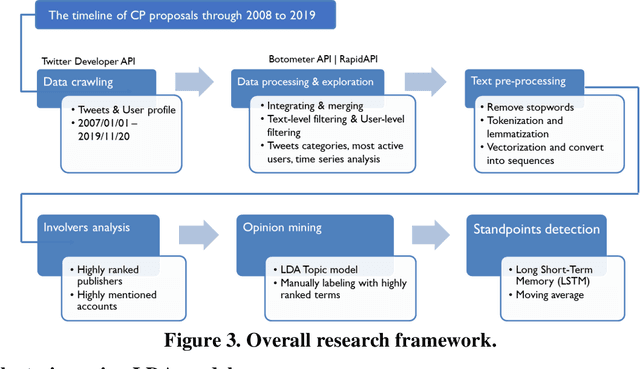
This study explores how people view and respond to the proposals of NYC congestion pricing evolve in time. To understand these responses, Twitter data is collected and analyzed. Critical groups in the recurrent process are detected by statistically analyzing the active users and the most mentioned accounts, and the trends of people's attitudes and concerns over the years are identified with text mining and hybrid Nature Language Processing techniques, including LDA topic modeling and LSTM sentiment classification. The result shows that multiple interest groups were involved and played crucial roles during the proposal, especially Mayor and Governor, MTA, and outer-borough representatives. The public shifted the concern of focus from the plan details to a wider city's sustainability and fairness. Furthermore, the plan's approval relies on several elements, the joint agreement reached in the political process, strong motivation in the real-world, the scheme based on balancing multiple interests, and groups' awareness of tolling's benefits and necessity.