 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Large VLMs with Iterative and Manual Instructions for Generative Low-light Enhancement
Jul 24, 2025



Most existing low-light image enhancement (LLIE) methods rely on pre-trained model priors, low-light inputs, or both, while neglecting the semantic guidance available from normal-light images. This limitation hinders their effectiveness in complex lighting conditions. In this paper, we propose VLM-IMI, a novel framework that leverages large vision-language models (VLMs) with iterative and manual instructions (IMIs) for LLIE. VLM-IMI incorporates textual descriptions of the desired normal-light content as enhancement cues, enabling semantically informed restoration. To effectively integrate cross-modal priors, we introduce an instruction prior fusion module, which dynamically aligns and fuses image and text features, promoting the generation of detailed and semantically coherent outputs. During inference, we adopt an iterative and manual instruction strategy to refine textual instructions, progressively improving visual quality. This refinement enhances structural fidelity, semantic alignment, and the recovery of fine details under extremely low-light conditions. Extensive experiments across diverse scenarios demonstrate that VLM-IMI outperforms state-of-the-art methods in both quantitative metrics and perceptual quality. The source code is available at https://github.com/sunxiaoran01/VLM-IMI.
Safeguarding Vision-Language Models: Mitigating Vulnerabilities to Gaussian Noise in Perturbation-based Attacks
Apr 02, 2025


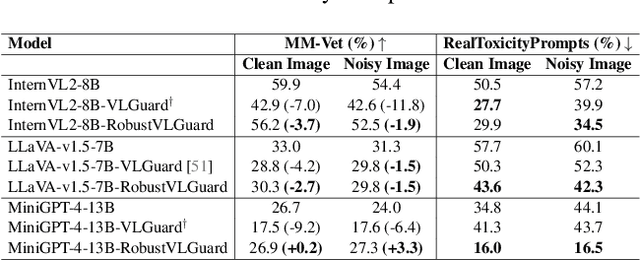
Vision-Language Models (VLMs) extend the capabilities of Large Language Models (LLMs) by incorporating visual information, yet they remain vulnerable to jailbreak attacks, especially when processing noisy or corrupted images. Although existing VLMs adopt security measures during training to mitigate such attacks, vulnerabilities associated with noise-augmented visual inputs are overlooked. In this work, we identify that missing noise-augmented training causes critical security gaps: many VLMs are susceptible to even simple perturbations such as Gaussian noise. To address this challenge, we propose Robust-VLGuard, a multimodal safety dataset with aligned / misaligned image-text pairs, combined with noise-augmented fine-tuning that reduces attack success rates while preserving functionality of VLM. For stronger optimization-based visual perturbation attacks, we propose DiffPure-VLM, leveraging diffusion models to convert adversarial perturbations into Gaussian-like noise, which can be defended by VLMs with noise-augmented safety fine-tuning. Experimental results demonstrate that the distribution-shifting property of diffusion model aligns well with our fine-tuned VLMs, significantly mitigating adversarial perturbations across varying intensities. The dataset and code are available at https://github.com/JarvisUSTC/DiffPure-RobustVLM.
IA2U: A Transfer Plugin with Multi-Prior for In-Air Model to Underwater
Dec 12, 2023
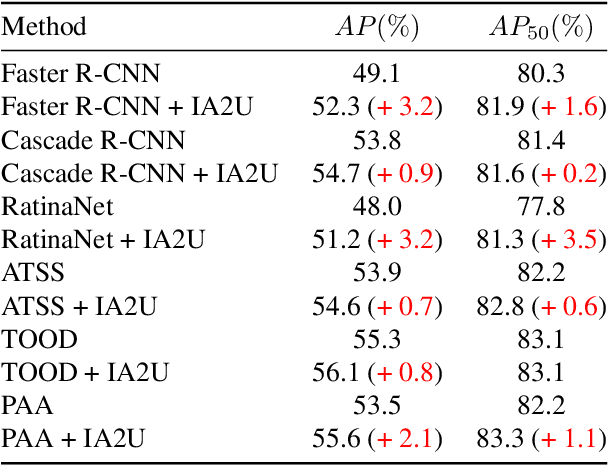
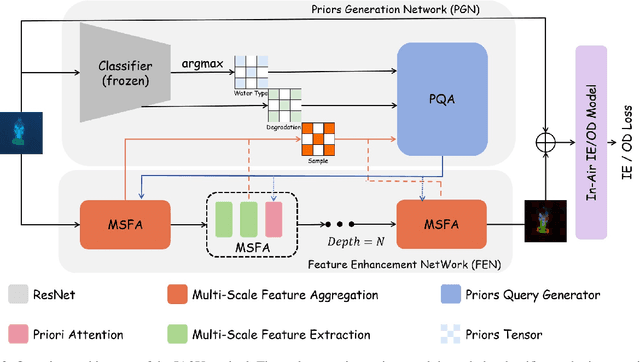
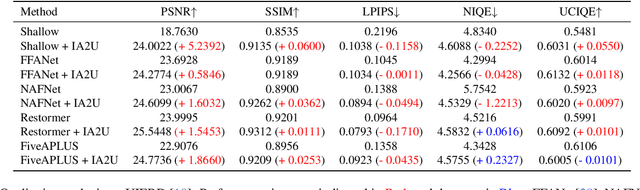
In underwater environments, variations in suspended particle concentration and turbidity cause severe image degradation, posing significant challenges to image enhancement (IE) and object detection (OD) tasks. Currently, in-air image enhancement and detection methods have made notable progress, but their application in underwater conditions is limited due to the complexity and variability of these environments. Fine-tuning in-air models saves high overhead and has more optional reference work than building an underwater model from scratch. To address these issues, we design a transfer plugin with multiple priors for converting in-air models to underwater applications, named IA2U. IA2U enables efficient application in underwater scenarios, thereby improving performance in Underwater IE and OD. IA2U integrates three types of underwater priors: the water type prior that characterizes the degree of image degradation, such as color and visibility; the degradation prior, focusing on differences in details and textures; and the sample prior, considering the environmental conditions at the time of capture and the characteristics of the photographed object. Utilizing a Transformer-like structure, IA2U employs these priors as query conditions and a joint task loss function to achieve hierarchical enhancement of task-level underwater image features, therefore considering the requirements of two different tasks, IE and OD. Experimental results show that IA2U combined with an in-air model can achieve superior performance in underwater image enhancement and object detection tasks. The code will be made publicly available.
DGNet: Dynamic Gradient-guided Network with Noise Suppression for Underwater Image Enhancement
Dec 12, 2023Underwater image enhancement (UIE) is a challenging task due to the complex degradation caused by underwater environments. To solve this issue, previous methods often idealize the degradation process, and neglect the impact of medium noise and object motion on the distribution of image features, limiting the generalization and adaptability of the model. Previous methods use the reference gradient that is constructed from original images and synthetic ground-truth images. This may cause the network performance to be influenced by some low-quality training data. Our approach utilizes predicted images to dynamically update pseudo-labels, adding a dynamic gradient to optimize the network's gradient space. This process improves image quality and avoids local optima. Moreover, we propose a Feature Restoration and Reconstruction module (FRR) based on a Channel Combination Inference (CCI) strategy and a Frequency Domain Smoothing module (FRS). These modules decouple other degradation features while reducing the impact of various types of noise on network performance. Experiments on multiple public datasets demonstrate the superiority of our method over existing state-of-the-art approaches, especially in achieving performance milestones: PSNR of 25.6dB and SSIM of 0.93 on the UIEB dataset. Its efficiency in terms of parameter size and inference time further attests to its broad practicality. The code will be made publicly available.
Restoration of User Videos Shared on Social Media
Aug 26, 2022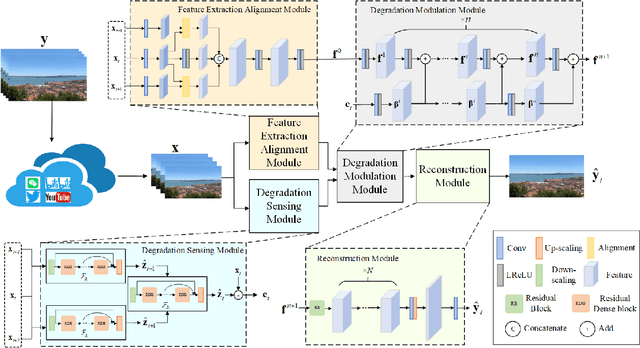



User videos shared on social media platforms usually suffer from degradations caused by unknown proprietary processing procedures, which means that their visual quality is poorer than that of the originals. This paper presents a new general video restoration framework for the restoration of user videos shared on social media platforms. In contrast to most deep learning-based video restoration methods that perform end-to-end mapping, where feature extraction is mostly treated as a black box, in the sense that what role a feature plays is often unknown, our new method, termed Video restOration through adapTive dEgradation Sensing (VOTES), introduces the concept of a degradation feature map (DFM) to explicitly guide the video restoration process. Specifically, for each video frame, we first adaptively estimate its DFM to extract features representing the difficulty of restoring its different regions. We then feed the DFM to a convolutional neural network (CNN) to compute hierarchical degradation features to modulate an end-to-end video restoration backbone network, such that more attention is paid explicitly to potentially more difficult to restore areas, which in turn leads to enhanced restoration performance. We will explain the design rationale of the VOTES framework and present extensive experimental results to show that the new VOTES method outperforms various state-of-the-art techniques both quantitatively and qualitatively. In addition, we contribute a large scale real-world database of user videos shared on different social media platforms. Codes and datasets are available at https://github.com/luohongming/VOTES.git
Progressive and Selective Fusion Network for High Dynamic Range Imaging
Aug 19, 2021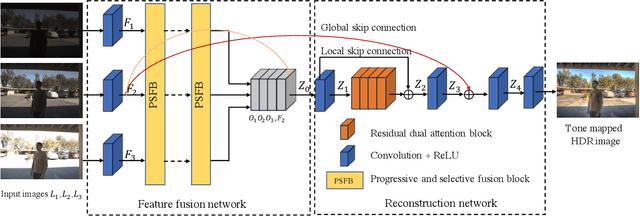
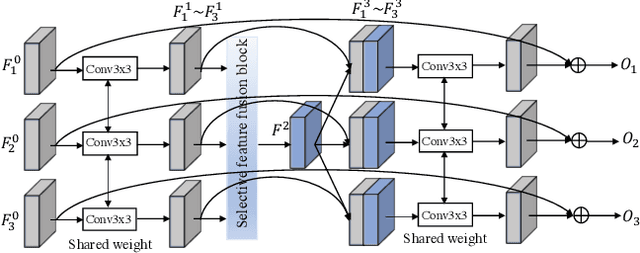
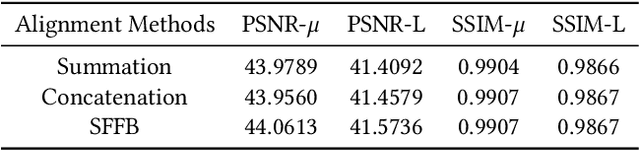
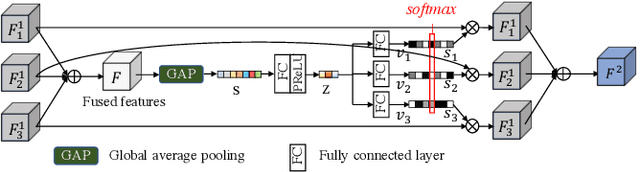
This paper considers the problem of generating an HDR image of a scene from its LDR images. Recent studies employ deep learning and solve the problem in an end-to-end fashion, leading to significant performance improvements. However, it is still hard to generate a good quality image from LDR images of a dynamic scene captured by a hand-held camera, e.g., occlusion due to the large motion of foreground objects, causing ghosting artifacts. The key to success relies on how well we can fuse the input images in their feature space, where we wish to remove the factors leading to low-quality image generation while performing the fundamental computations for HDR image generation, e.g., selecting the best-exposed image/region. We propose a novel method that can better fuse the features based on two ideas. One is multi-step feature fusion; our network gradually fuses the features in a stack of blocks having the same structure. The other is the design of the component block that effectively performs two operations essential to the problem, i.e., comparing and selecting appropriate images/regions. Experimental results show that the proposed method outperforms the previous state-of-the-art methods on the standard benchmark tests.