 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA$^{2}$Net: Scale-Adaptive Structure-Affinity Transformation for Spine Segmentation from Ultrasound Volume Projection Imaging
Oct 30, 2025Spine segmentation, based on ultrasound volume projection imaging (VPI), plays a vital role for intelligent scoliosis diagnosis in clinical applications. However, this task faces several significant challenges. Firstly, the global contextual knowledge of spines may not be well-learned if we neglect the high spatial correlation of different bone features. Secondly, the spine bones contain rich structural knowledge regarding their shapes and positions, which deserves to be encoded into the segmentation process. To address these challenges, we propose a novel scale-adaptive structure-aware network (SA$^{2}$Net) for effective spine segmentation. First, we propose a scale-adaptive complementary strategy to learn the cross-dimensional long-distance correlation features for spinal images. Second, motivated by the consistency between multi-head self-attention in Transformers and semantic level affinity, we propose structure-affinity transformation to transform semantic features with class-specific affinity and combine it with a Transformer decoder for structure-aware reasoning. In addition, we adopt a feature mixing loss aggregation method to enhance model training. This method improves the robustness and accuracy of the segmentation process. The experimental results demonstrate that our SA$^{2}$Net achieves superior segmentation performance compared to other state-of-the-art methods. Moreover, the adaptability of SA$^{2}$Net to various backbones enhances its potential as a promising tool for advanced scoliosis diagnosis using intelligent spinal image analysis. The code and experimental demo are available at https://github.com/taetiseo09/SA2Net.
4KAgent: Agentic Any Image to 4K Super-Resolution
Jul 09, 2025We present 4KAgent, a unified agentic super-resolution generalist system designed to universally upscale any image to 4K resolution (and even higher, if applied iteratively). Our system can transform images from extremely low resolutions with severe degradations, for example, highly distorted inputs at 256x256, into crystal-clear, photorealistic 4K outputs. 4KAgent comprises three core components: (1) Profiling, a module that customizes the 4KAgent pipeline based on bespoke use cases; (2) A Perception Agent, which leverages vision-language models alongside image quality assessment experts to analyze the input image and make a tailored restoration plan; and (3) A Restoration Agent, which executes the plan, following a recursive execution-reflection paradigm, guided by a quality-driven mixture-of-expert policy to select the optimal output for each step. Additionally, 4KAgent embeds a specialized face restoration pipeline, significantly enhancing facial details in portrait and selfie photos. We rigorously evaluate our 4KAgent across 11 distinct task categories encompassing a total of 26 diverse benchmarks, setting new state-of-the-art on a broad spectrum of imaging domains. Our evaluations cover natural images, portrait photos, AI-generated content, satellite imagery, fluorescence microscopy, and medical imaging like fundoscopy, ultrasound, and X-ray, demonstrating superior performance in terms of both perceptual (e.g., NIQE, MUSIQ) and fidelity (e.g., PSNR) metrics. By establishing a novel agentic paradigm for low-level vision tasks, we aim to catalyze broader interest and innovation within vision-centric autonomous agents across diverse research communities. We will release all the code, models, and results at: https://4kagent.github.io.
NTIRE 2025 Challenge on UGC Video Enhancement: Methods and Results
May 05, 2025This paper presents an overview of the NTIRE 2025 Challenge on UGC Video Enhancement. The challenge constructed a set of 150 user-generated content videos without reference ground truth, which suffer from real-world degradations such as noise, blur, faded colors, compression artifacts, etc. The goal of the participants was to develop an algorithm capable of improving the visual quality of such videos. Given the widespread use of UGC on short-form video platforms, this task holds substantial practical importance. The evaluation was based on subjective quality assessment in crowdsourcing, obtaining votes from over 8000 assessors. The challenge attracted more than 25 teams submitting solutions, 7 of which passed the final phase with source code verification. The outcomes may provide insights into the state-of-the-art in UGC video enhancement and highlight emerging trends and effective strategies in this evolving research area. All data, including the processed videos and subjective comparison votes and scores, is made publicly available at https://github.com/msu-video-group/NTIRE25_UGC_Video_Enhancement.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Safeguarding Vision-Language Models: Mitigating Vulnerabilities to Gaussian Noise in Perturbation-based Attacks
Apr 02, 2025


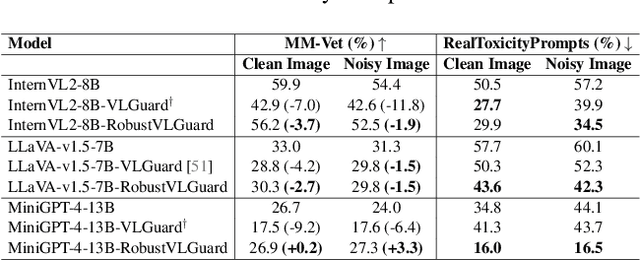
Vision-Language Models (VLMs) extend the capabilities of Large Language Models (LLMs) by incorporating visual information, yet they remain vulnerable to jailbreak attacks, especially when processing noisy or corrupted images. Although existing VLMs adopt security measures during training to mitigate such attacks, vulnerabilities associated with noise-augmented visual inputs are overlooked. In this work, we identify that missing noise-augmented training causes critical security gaps: many VLMs are susceptible to even simple perturbations such as Gaussian noise. To address this challenge, we propose Robust-VLGuard, a multimodal safety dataset with aligned / misaligned image-text pairs, combined with noise-augmented fine-tuning that reduces attack success rates while preserving functionality of VLM. For stronger optimization-based visual perturbation attacks, we propose DiffPure-VLM, leveraging diffusion models to convert adversarial perturbations into Gaussian-like noise, which can be defended by VLMs with noise-augmented safety fine-tuning. Experimental results demonstrate that the distribution-shifting property of diffusion model aligns well with our fine-tuned VLMs, significantly mitigating adversarial perturbations across varying intensities. The dataset and code are available at https://github.com/JarvisUSTC/DiffPure-RobustVLM.
See In Detail: Enhancing Sparse-view 3D Gaussian Splatting with Local Depth and Semantic Regularization
Jan 20, 20253D Gaussian Splatting (3DGS) has shown remarkable performance in novel view synthesis. However, its rendering quality deteriorates with sparse inphut views, leading to distorted content and reduced details. This limitation hinders its practical application. To address this issue, we propose a sparse-view 3DGS method. Given the inherently ill-posed nature of sparse-view rendering, incorporating prior information is crucial. We propose a semantic regularization technique, using features extracted from the pretrained DINO-ViT model, to ensure multi-view semantic consistency. Additionally, we propose local depth regularization, which constrains depth values to improve generalization on unseen views. Our method outperforms state-of-the-art novel view synthesis approaches, achieving up to 0.4dB improvement in terms of PSNR on the LLFF dataset, with reduced distortion and enhanced visual quality.
Towards Multi-View Consistent Style Transfer with One-Step Diffusion via Vision Conditioning
Nov 15, 2024



The stylization of 3D scenes is an increasingly attractive topic in 3D vision. Although image style transfer has been extensively researched with promising results, directly applying 2D style transfer methods to 3D scenes often fails to preserve the structural and multi-view properties of 3D environments, resulting in unpleasant distortions in images from different viewpoints. To address these issues, we leverage the remarkable generative prior of diffusion-based models and propose a novel style transfer method, OSDiffST, based on a pre-trained one-step diffusion model (i.e., SD-Turbo) for rendering diverse styles in multi-view images of 3D scenes. To efficiently adapt the pre-trained model for multi-view style transfer on small datasets, we introduce a vision condition module to extract style information from the reference style image to serve as conditional input for the diffusion model and employ LoRA in diffusion model for adaptation. Additionally, we consider color distribution alignment and structural similarity between the stylized and content images using two specific loss functions. As a result, our method effectively preserves the structural information and multi-view consistency in stylized images without any 3D information. Experiments show that our method surpasses other promising style transfer methods in synthesizing various styles for multi-view images of 3D scenes. Stylized images from different viewpoints generated by our method achieve superior visual quality, with better structural integrity and less distortion. The source code is available at https://github.com/YushenZuo/OSDiffST.