 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeguarding Vision-Language Models: Mitigating Vulnerabilities to Gaussian Noise in Perturbation-based Attacks
Paper and Code



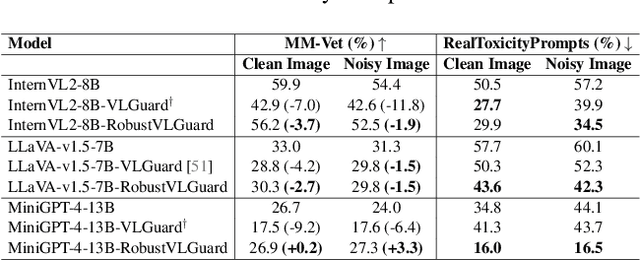
Vision-Language Models (VLMs) extend the capabilities of Large Language Models (LLMs) by incorporating visual information, yet they remain vulnerable to jailbreak attacks, especially when processing noisy or corrupted images. Although existing VLMs adopt security measures during training to mitigate such attacks, vulnerabilities associated with noise-augmented visual inputs are overlooked. In this work, we identify that missing noise-augmented training causes critical security gaps: many VLMs are susceptible to even simple perturbations such as Gaussian noise. To address this challenge, we propose Robust-VLGuard, a multimodal safety dataset with aligned / misaligned image-text pairs, combined with noise-augmented fine-tuning that reduces attack success rates while preserving functionality of VLM. For stronger optimization-based visual perturbation attacks, we propose DiffPure-VLM, leveraging diffusion models to convert adversarial perturbations into Gaussian-like noise, which can be defended by VLMs with noise-augmented safety fine-tuning. Experimental results demonstrate that the distribution-shifting property of diffusion model aligns well with our fine-tuned VLMs, significantly mitigating adversarial perturbations across varying intensities. The dataset and code are available at https://github.com/JarvisUSTC/DiffPure-RobustVLM.