 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Diffusion Classifier with Adaptive Margin Discrepancy Training for Facial Expression Recognition
Mar 31, 2026Facial Expression Recognition (FER) is essential for human-machine interaction, as it enables machines to interpret human emotions and internal states from facial affective behaviors. Although deep learning has significantly advanced FER performance, most existing deep-learning-based FER methods rely heavily on discriminative classifiers for fast predictions. These models tend to learn shortcuts and are vulnerable to even minor distribution shifts. To address this issue, we adopt a conditional generative diffusion model and introduce the Emotion Diffusion Classifier (EmoDC) for FER, which demonstrates enhanced adversarial robustness. However, retraining EmoDC using standard strategies fails to penalize incorrect categorical descriptions, leading to suboptimal recognition performance. To improve EmoDC, we propose margin-based discrepancy training, which encourages accurate predictions when conditioned on correct categorical descriptions and penalizes predictions conditioned on mismatched ones. This method enforces a minimum margin between noise-prediction errors for correct and incorrect categories, thereby enhancing the model's discriminative capability. Nevertheless, using a fixed margin fails to account for the varying difficulty of noise prediction across different images, limiting its effectiveness. To overcome this limitation, we propose Adaptive Margin Discrepancy Training (AMDiT), which dynamically adjusts the margin for each sample. Extensive experiments show that AMDiT significantly improves the accuracy of EmoDC over the Base model with standard denoising diffusion training on the RAF-DB basic subset, the RAF-DB compound subset, SFEW-2.0, and AffectNet, in 100-step evaluations. Additionally, EmoDC outperforms state-of-the-art discriminative classifiers in terms of robustness against noise and blur.
Vision-Language Model Guided Image Restoration
Dec 19, 2025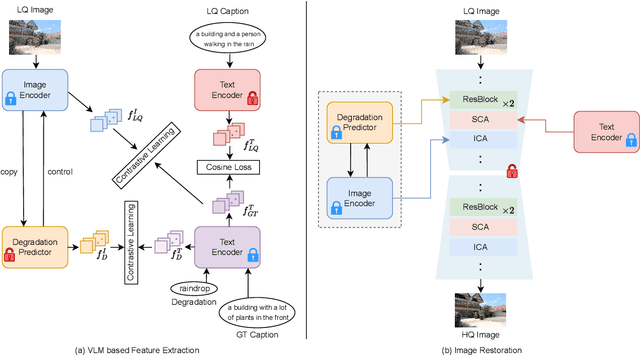
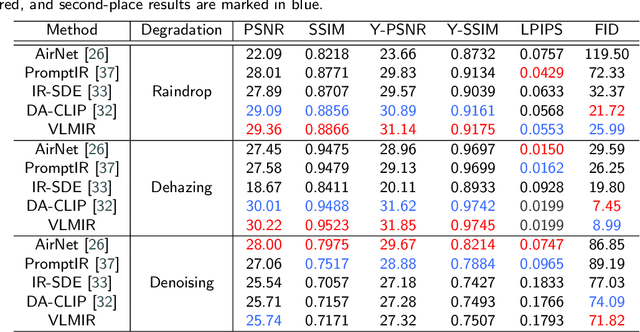

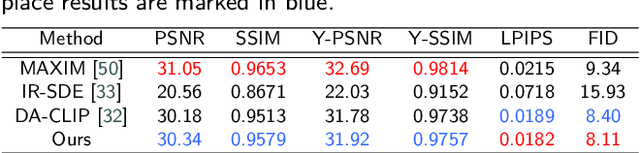
Many image restoration (IR) tasks require both pixel-level fidelity and high-level semantic understanding to recover realistic photos with fine-grained details. However, previous approaches often struggle to effectively leverage both the visual and linguistic knowledge. Recent efforts have attempted to incorporate Vision-language models (VLMs), which excel at aligning visual and textual features, into universal IR. Nevertheless, these methods fail to utilize the linguistic priors to ensure semantic coherence during the restoration process. To address this issue, in this paper, we propose the Vision-Language Model Guided Image Restoration (VLMIR) framework, which leverages the rich vision-language priors of VLMs, such as CLIP, to enhance IR performance through improved visual perception and semantic understanding. Our approach consists of two stages: VLM-based feature extraction and diffusion-based image restoration. In the first stage, we extract complementary visual and linguistic representations of input images by condensing the visual perception and high-level semantic priors through VLMs. Specifically, we align the embeddings of captions from low-quality and high-quality images using a cosine similarity loss with LoRA fine-tuning, and employ a degradation predictor to decompose degradation and clean image content embeddings. These complementary visual and textual embeddings are then integrated into a diffusion-based model via cross-attention mechanisms for enhanced restoration. Extensive experiments and ablation studies demonstrate that VLMIR achieves superior performance across both universal and degradation-specific IR tasks, underscoring the critical role of integrated visual and linguistic knowledge from VLMs in advancing image restoration capabilities.
Multi-level distortion-aware deformable network for omnidirectional image super-resolution
Dec 19, 2025As augmented reality and virtual reality applications gain popularity, image processing for OmniDirectional Images (ODIs) has attracted increasing attention. OmniDirectional Image Super-Resolution (ODISR) is a promising technique for enhancing the visual quality of ODIs. Before performing super-resolution, ODIs are typically projected from a spherical surface onto a plane using EquiRectangular Projection (ERP). This projection introduces latitude-dependent geometric distortion in ERP images: distortion is minimal near the equator but becomes severe toward the poles, where image content is stretched across a wider area. However, existing ODISR methods have limited sampling ranges and feature extraction capabilities, which hinder their ability to capture distorted patterns over large areas. To address this issue, we propose a novel Multi-level Distortion-aware Deformable Network (MDDN) for ODISR, designed to expand the sampling range and receptive field. Specifically, the feature extractor in MDDN comprises three parallel branches: a deformable attention mechanism (serving as the dilation=1 path) and two dilated deformable convolutions with dilation rates of 2 and 3. This architecture expands the sampling range to include more distorted patterns across wider areas, generating dense and comprehensive features that effectively capture geometric distortions in ERP images. The representations extracted from these deformable feature extractors are adaptively fused in a multi-level feature fusion module. Furthermore, to reduce computational cost, a low-rank decomposition strategy is applied to dilated deformable convolutions. Extensive experiments on publicly available datasets demonstrate that MDDN outperforms state-of-the-art methods, underscoring its effectiveness and superiority in ODISR.
HFS: Holistic Query-Aware Frame Selection for Efficient Video Reasoning
Dec 12, 2025Key frame selection in video understanding presents significant challenges. Traditional top-K selection methods, which score frames independently, often fail to optimize the selection as a whole. This independent scoring frequently results in selecting frames that are temporally clustered and visually redundant. Additionally, training lightweight selectors using pseudo labels generated offline by Multimodal Large Language Models (MLLMs) prevents the supervisory signal from dynamically adapting to task objectives. To address these limitations, we propose an end-to-end trainable, task-adaptive framework for frame selection. A Chain-of-Thought approach guides a Small Language Model (SLM) to generate task-specific implicit query vectors, which are combined with multimodal features to enable dynamic frame scoring. We further define a continuous set-level objective function that incorporates relevance, coverage, and redundancy, enabling differentiable optimization via Gumbel-Softmax to select optimal frame combinations at the set level. Finally, student-teacher mutual learning is employed, where the student selector (SLM) and teacher reasoner (MLLM) are trained to align their frame importance distributions via KL divergence. Combined with cross-entropy loss, this enables end-to-end optimization, eliminating reliance on static pseudo labels. Experiments across various benchmarks, including Video-MME, LongVideoBench, MLVU, and NExT-QA, demonstrate that our method significantly outperforms existing approaches.
SA$^{2}$Net: Scale-Adaptive Structure-Affinity Transformation for Spine Segmentation from Ultrasound Volume Projection Imaging
Oct 30, 2025Spine segmentation, based on ultrasound volume projection imaging (VPI), plays a vital role for intelligent scoliosis diagnosis in clinical applications. However, this task faces several significant challenges. Firstly, the global contextual knowledge of spines may not be well-learned if we neglect the high spatial correlation of different bone features. Secondly, the spine bones contain rich structural knowledge regarding their shapes and positions, which deserves to be encoded into the segmentation process. To address these challenges, we propose a novel scale-adaptive structure-aware network (SA$^{2}$Net) for effective spine segmentation. First, we propose a scale-adaptive complementary strategy to learn the cross-dimensional long-distance correlation features for spinal images. Second, motivated by the consistency between multi-head self-attention in Transformers and semantic level affinity, we propose structure-affinity transformation to transform semantic features with class-specific affinity and combine it with a Transformer decoder for structure-aware reasoning. In addition, we adopt a feature mixing loss aggregation method to enhance model training. This method improves the robustness and accuracy of the segmentation process. The experimental results demonstrate that our SA$^{2}$Net achieves superior segmentation performance compared to other state-of-the-art methods. Moreover, the adaptability of SA$^{2}$Net to various backbones enhances its potential as a promising tool for advanced scoliosis diagnosis using intelligent spinal image analysis. The code and experimental demo are available at https://github.com/taetiseo09/SA2Net.
Enhancing Technical Documents Retrieval for RAG
Sep 04, 2025In this paper, we introduce Technical-Embeddings, a novel framework designed to optimize semantic retrieval in technical documentation, with applications in both hardware and software development. Our approach addresses the challenges of understanding and retrieving complex technical content by leveraging the capabilities of Large Language Models (LLMs). First, we enhance user queries by generating expanded representations that better capture user intent and improve dataset diversity, thereby enriching the fine-tuning process for embedding models. Second, we apply summary extraction techniques to encode essential contextual information, refining the representation of technical documents. To further enhance retrieval performance, we fine-tune a bi-encoder BERT model using soft prompting, incorporating separate learning parameters for queries and document context to capture fine-grained semantic nuances. We evaluate our approach on two public datasets, RAG-EDA and Rust-Docs-QA, demonstrating that Technical-Embeddings significantly outperforms baseline models in both precision and recall. Our findings highlight the effectiveness of integrating query expansion and contextual summarization to enhance information access and comprehension in technical domains. This work advances the state of Retrieval-Augmented Generation (RAG) systems, offering new avenues for efficient and accurate technical document retrieval in engineering and product development workflows.
Deep Learning-Driven Ultra-High-Definition Image Restoration: A Survey
May 22, 2025Ultra-high-definition (UHD) image restoration aims to specifically solve the problem of quality degradation in ultra-high-resolution images. Recent advancements in this field are predominantly driven by deep learning-based innovations, including enhancements in dataset construction, network architecture, sampling strategies, prior knowledge integration, and loss functions. In this paper, we systematically review recent progress in UHD image restoration, covering various aspects ranging from dataset construction to algorithm design. This serves as a valuable resource for understanding state-of-the-art developments in the field. We begin by summarizing degradation models for various image restoration subproblems, such as super-resolution, low-light enhancement, deblurring, dehazing, deraining, and desnowing, and emphasizing the unique challenges of their application to UHD image restoration. We then highlight existing UHD benchmark datasets and organize the literature according to degradation types and dataset construction methods. Following this, we showcase major milestones in deep learning-driven UHD image restoration, reviewing the progression of restoration tasks, technological developments, and evaluations of existing methods. We further propose a classification framework based on network architectures and sampling strategies, helping to clearly organize existing methods. Finally, we share insights into the current research landscape and propose directions for further advancements. A related repository is available at https://github.com/wlydlut/UHD-Image-Restoration-Survey.
See In Detail: Enhancing Sparse-view 3D Gaussian Splatting with Local Depth and Semantic Regularization
Jan 20, 20253D Gaussian Splatting (3DGS) has shown remarkable performance in novel view synthesis. However, its rendering quality deteriorates with sparse inphut views, leading to distorted content and reduced details. This limitation hinders its practical application. To address this issue, we propose a sparse-view 3DGS method. Given the inherently ill-posed nature of sparse-view rendering, incorporating prior information is crucial. We propose a semantic regularization technique, using features extracted from the pretrained DINO-ViT model, to ensure multi-view semantic consistency. Additionally, we propose local depth regularization, which constrains depth values to improve generalization on unseen views. Our method outperforms state-of-the-art novel view synthesis approaches, achieving up to 0.4dB improvement in terms of PSNR on the LLFF dataset, with reduced distortion and enhanced visual quality.
Automatic Prompt Generation and Grounding Object Detection for Zero-Shot Image Anomaly Detection
Nov 28, 2024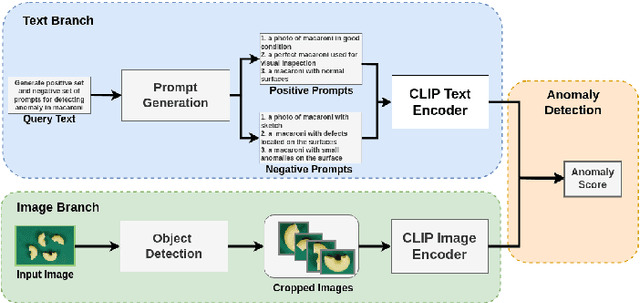

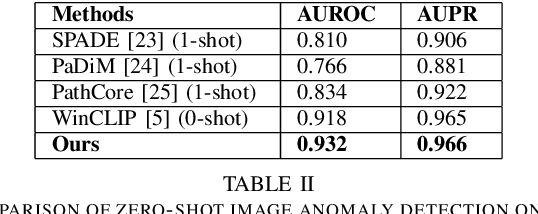
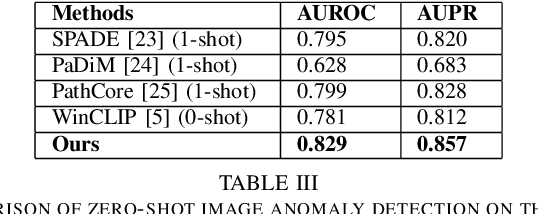
Identifying defects and anomalies in industrial products is a critical quality control task. Traditional manual inspection methods are slow, subjective, and error-prone. In this work, we propose a novel zero-shot training-free approach for automated industrial image anomaly detection using a multimodal machine learning pipeline, consisting of three foundation models. Our method first uses a large language model, i.e., GPT-3. generate text prompts describing the expected appearances of normal and abnormal products. We then use a grounding object detection model, called Grounding DINO, to locate the product in the image. Finally, we compare the cropped product image patches to the generated prompts using a zero-shot image-text matching model, called CLIP, to identify any anomalies. Our experiments on two datasets of industrial product images, namely MVTec-AD and VisA, demonstrate the effectiveness of this method, achieving high accuracy in detecting various types of defects and anomalies without the need for model training. Our proposed model enables efficient, scalable, and objective quality control in industrial manufacturing settings.
An End-to-End Two-Stream Network Based on RGB Flow and Representation Flow for Human Action Recognition
Nov 27, 2024



With the rapid advancements in deep learning, computer vision tasks have seen significant improvements, making two-stream neural networks a popular focus for video based action recognition. Traditional models using RGB and optical flow streams achieve strong performance but at a high computational cost. To address this, we introduce a representation flow algorithm to replace the optical flow branch in the egocentric action recognition model, enabling end-to-end training while reducing computational cost and prediction time. Our model, designed for egocentric action recognition, uses class activation maps (CAMs) to improve accuracy and ConvLSTM for spatio temporal encoding with spatial attention. When evaluated on the GTEA61, EGTEA GAZE+, and HMDB datasets, our model matches the accuracy of the original model on GTEA61 and exceeds it by 0.65% and 0.84% on EGTEA GAZE+ and HMDB, respectively. Prediction runtimes are significantly reduced to 0.1881s, 0.1503s, and 0.1459s, compared to the original model's 101.6795s, 25.3799s, and 203.9958s. Ablation studies were also conducted to study the impact of different parameters on model performance. Keywords: two-stream, egocentric, action recognition, CAM, representation flow, CAM, ConvLSTM