 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Discrimination-Prompted Transformers for Efficient UHD Image Restoration and Enhancement
Mar 01, 2026We propose a simple yet effective UHDPromer, a neural discrimination-prompted Transformer, for Ultra-High-Definition (UHD) image restoration and enhancement. Our UHDPromer is inspired by an interesting observation that there implicitly exist neural differences between high-resolution and low-resolution features, and exploring such differences can facilitate low-resolution feature representation. To this end, we first introduce Neural Discrimination Priors (NDP) to measure the differences and then integrate NDP into the proposed Neural Discrimination-Prompted Attention (NDPA) and Neural Discrimination-Prompted Network (NDPN). The proposed NDPA re-formulates the attention by incorporating NDP to globally perceive useful discrimination information, while the NDPN explores a continuous gating mechanism guided by NDP to selectively permit the passage of beneficial content. To enhance the quality of restored images, we propose a super-resolution-guided reconstruction approach, which is guided by super-resolving low-resolution features to facilitate final UHD image restoration. Experiments show that UHDPromer achieves the best computational efficiency while still maintaining state-of-the-art performance on $3$ UHD image restoration and enhancement tasks, including low-light image enhancement, image dehazing, and image deblurring. The source codes and pre-trained models will be made available at https://github.com/supersupercong/uhdpromer.
Adapting Large VLMs with Iterative and Manual Instructions for Generative Low-light Enhancement
Jul 24, 2025



Most existing low-light image enhancement (LLIE) methods rely on pre-trained model priors, low-light inputs, or both, while neglecting the semantic guidance available from normal-light images. This limitation hinders their effectiveness in complex lighting conditions. In this paper, we propose VLM-IMI, a novel framework that leverages large vision-language models (VLMs) with iterative and manual instructions (IMIs) for LLIE. VLM-IMI incorporates textual descriptions of the desired normal-light content as enhancement cues, enabling semantically informed restoration. To effectively integrate cross-modal priors, we introduce an instruction prior fusion module, which dynamically aligns and fuses image and text features, promoting the generation of detailed and semantically coherent outputs. During inference, we adopt an iterative and manual instruction strategy to refine textual instructions, progressively improving visual quality. This refinement enhances structural fidelity, semantic alignment, and the recovery of fine details under extremely low-light conditions. Extensive experiments across diverse scenarios demonstrate that VLM-IMI outperforms state-of-the-art methods in both quantitative metrics and perceptual quality. The source code is available at https://github.com/sunxiaoran01/VLM-IMI.
Deep Learning-Driven Ultra-High-Definition Image Restoration: A Survey
May 22, 2025Ultra-high-definition (UHD) image restoration aims to specifically solve the problem of quality degradation in ultra-high-resolution images. Recent advancements in this field are predominantly driven by deep learning-based innovations, including enhancements in dataset construction, network architecture, sampling strategies, prior knowledge integration, and loss functions. In this paper, we systematically review recent progress in UHD image restoration, covering various aspects ranging from dataset construction to algorithm design. This serves as a valuable resource for understanding state-of-the-art developments in the field. We begin by summarizing degradation models for various image restoration subproblems, such as super-resolution, low-light enhancement, deblurring, dehazing, deraining, and desnowing, and emphasizing the unique challenges of their application to UHD image restoration. We then highlight existing UHD benchmark datasets and organize the literature according to degradation types and dataset construction methods. Following this, we showcase major milestones in deep learning-driven UHD image restoration, reviewing the progression of restoration tasks, technological developments, and evaluations of existing methods. We further propose a classification framework based on network architectures and sampling strategies, helping to clearly organize existing methods. Finally, we share insights into the current research landscape and propose directions for further advancements. A related repository is available at https://github.com/wlydlut/UHD-Image-Restoration-Survey.
Intra and Inter Parser-Prompted Transformers for Effective Image Restoration
Mar 18, 2025We propose Intra and Inter Parser-Prompted Transformers (PPTformer) that explore useful features from visual foundation models for image restoration. Specifically, PPTformer contains two parts: an Image Restoration Network (IRNet) for restoring images from degraded observations and a Parser-Prompted Feature Generation Network (PPFGNet) for providing IRNet with reliable parser information to boost restoration. To enhance the integration of the parser within IRNet, we propose Intra Parser-Prompted Attention (IntraPPA) and Inter Parser-Prompted Attention (InterPPA) to implicitly and explicitly learn useful parser features to facilitate restoration. The IntraPPA re-considers cross attention between parser and restoration features, enabling implicit perception of the parser from a long-range and intra-layer perspective. Conversely, the InterPPA initially fuses restoration features with those of the parser, followed by formulating these fused features within an attention mechanism to explicitly perceive parser information. Further, we propose a parser-prompted feed-forward network to guide restoration within pixel-wise gating modulation. Experimental results show that PPTformer achieves state-of-the-art performance on image deraining, defocus deblurring, desnowing, and low-light enhancement.
Ultra-High-Definition Restoration: New Benchmarks and A Dual Interaction Prior-Driven Solution
Jun 19, 2024


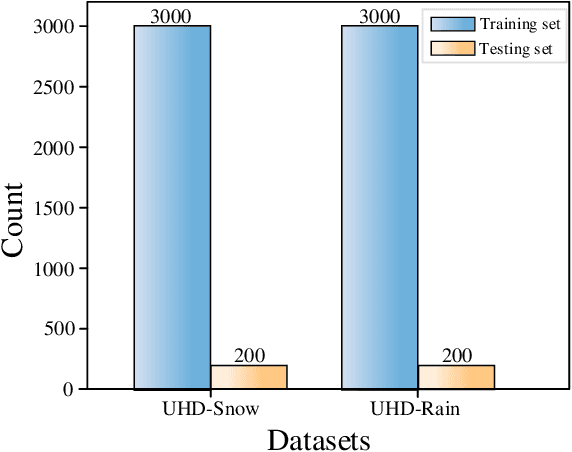
Ultra-High-Definition (UHD) image restoration has acquired remarkable attention due to its practical demand. In this paper, we construct UHD snow and rain benchmarks, named UHD-Snow and UHD-Rain, to remedy the deficiency in this field. The UHD-Snow/UHD-Rain is established by simulating the physics process of rain/snow into consideration and each benchmark contains 3200 degraded/clear image pairs of 4K resolution. Furthermore, we propose an effective UHD image restoration solution by considering gradient and normal priors in model design thanks to these priors' spatial and detail contributions. Specifically, our method contains two branches: (a) feature fusion and reconstruction branch in high-resolution space and (b) prior feature interaction branch in low-resolution space. The former learns high-resolution features and fuses prior-guided low-resolution features to reconstruct clear images, while the latter utilizes normal and gradient priors to mine useful spatial features and detail features to guide high-resolution recovery better. To better utilize these priors, we introduce single prior feature interaction and dual prior feature interaction, where the former respectively fuses normal and gradient priors with high-resolution features to enhance prior ones, while the latter calculates the similarity between enhanced prior ones and further exploits dual guided filtering to boost the feature interaction of dual priors. We conduct experiments on both new and existing public datasets and demonstrate the state-of-the-art performance of our method on UHD image low-light enhancement, UHD image desonwing, and UHD image deraining. The source codes and benchmarks are available at \url{https://github.com/wlydlut/UHDDIP}.
How Powerful Potential of Attention on Image Restoration?
Mar 15, 2024



Transformers have demonstrated their effectiveness in image restoration tasks. Existing Transformer architectures typically comprise two essential components: multi-head self-attention and feed-forward network (FFN). The former captures long-range pixel dependencies, while the latter enables the model to learn complex patterns and relationships in the data. Previous studies have demonstrated that FFNs are key-value memories \cite{geva2020transformer}, which are vital in modern Transformer architectures. In this paper, we conduct an empirical study to explore the potential of attention mechanisms without using FFN and provide novel structures to demonstrate that removing FFN is flexible for image restoration. Specifically, we propose Continuous Scaling Attention (\textbf{CSAttn}), a method that computes attention continuously in three stages without using FFN. To achieve competitive performance, we propose a series of key components within the attention. Our designs provide a closer look at the attention mechanism and reveal that some simple operations can significantly affect the model performance. We apply our \textbf{CSAttn} to several image restoration tasks and show that our model can outperform CNN-based and Transformer-based image restoration approaches.
Learning A Coarse-to-Fine Diffusion Transformer for Image Restoration
Aug 29, 2023Recent years have witnessed the remarkable performance of diffusion models in various vision tasks. However, for image restoration that aims to recover clear images with sharper details from given degraded observations, diffusion-based methods may fail to recover promising results due to inaccurate noise estimation. Moreover, simple constraining noises cannot effectively learn complex degradation information, which subsequently hinders the model capacity. To solve the above problems, we propose a coarse-to-fine diffusion Transformer (C2F-DFT) for image restoration. Specifically, our C2F-DFT contains diffusion self-attention (DFSA) and diffusion feed-forward network (DFN) within a new coarse-to-fine training scheme. The DFSA and DFN respectively capture the long-range diffusion dependencies and learn hierarchy diffusion representation to facilitate better restoration. In the coarse training stage, our C2F-DFT estimates noises and then generates the final clean image by a sampling algorithm. To further improve the restoration quality, we propose a simple yet effective fine training scheme. It first exploits the coarse-trained diffusion model with fixed steps to generate restoration results, which then would be constrained with corresponding ground-truth ones to optimize the models to remedy the unsatisfactory results affected by inaccurate noise estimation. Extensive experiments show that C2F-DFT significantly outperforms diffusion-based restoration method IR-SDE and achieves competitive performance compared with Transformer-based state-of-the-art methods on $3$ tasks, including deraining, deblurring, and real denoising. The code is available at https://github.com/wlydlut/C2F-DFT.