 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Scientific Research with Gemini: Case Studies and Common Techniques
Feb 03, 2026Recent advances in large language models (LLMs) have opened new avenues for accelerating scientific research. While models are increasingly capable of assisting with routine tasks, their ability to contribute to novel, expert-level mathematical discovery is less understood. We present a collection of case studies demonstrating how researchers have successfully collaborated with advanced AI models, specifically Google's Gemini-based models (in particular Gemini Deep Think and its advanced variants), to solve open problems, refute conjectures, and generate new proofs across diverse areas in theoretical computer science, as well as other areas such as economics, optimization, and physics. Based on these experiences, we extract common techniques for effective human-AI collaboration in theoretical research, such as iterative refinement, problem decomposition, and cross-disciplinary knowledge transfer. While the majority of our results stem from this interactive, conversational methodology, we also highlight specific instances that push beyond standard chat interfaces. These include deploying the model as a rigorous adversarial reviewer to detect subtle flaws in existing proofs, and embedding it within a "neuro-symbolic" loop that autonomously writes and executes code to verify complex derivations. Together, these examples highlight the potential of AI not just as a tool for automation, but as a versatile, genuine partner in the creative process of scientific discovery.
QwenLong-CPRS: Towards $\infty$-LLMs with Dynamic Context Optimization
May 23, 2025This technical report presents QwenLong-CPRS, a context compression framework designed for explicit long-context optimization, addressing prohibitive computation overhead during the prefill stage and the "lost in the middle" performance degradation of large language models (LLMs) during long sequence processing. Implemented through a novel dynamic context optimization mechanism, QwenLong-CPRS enables multi-granularity context compression guided by natural language instructions, achieving both efficiency gains and improved performance. Evolved from the Qwen architecture series, QwenLong-CPRS introduces four key innovations: (1) Natural language-guided dynamic optimization, (2) Bidirectional reasoning layers for enhanced boundary awareness, (3) Token critic mechanisms with language modeling heads, and (4) Window-parallel inference. Comprehensive evaluations across five benchmarks (4K-2M word contexts) demonstrate QwenLong-CPRS's threefold effectiveness: (1) Consistent superiority over other context management methods like RAG and sparse attention in both accuracy and efficiency. (2) Architecture-agnostic integration with all flagship LLMs, including GPT-4o, Gemini2.0-pro, Claude3.7-sonnet, DeepSeek-v3, and Qwen2.5-max, achieves 21.59$\times$ context compression alongside 19.15-point average performance gains; (3) Deployed with Qwen2.5-32B-Instruct, QwenLong-CPRS surpasses leading proprietary LLMs by 4.85 and 10.88 points on Ruler-128K and InfiniteBench, establishing new SOTA performance.
Bipartite Ranking From Multiple Labels: On Loss Versus Label Aggregation
Apr 15, 2025
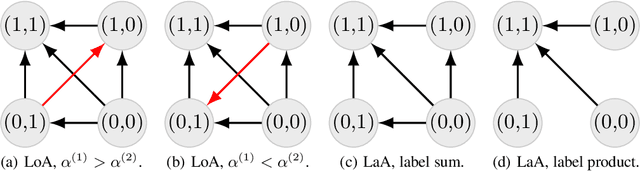


Bipartite ranking is a fundamental supervised learning problem, with the goal of learning a ranking over instances with maximal area under the ROC curve (AUC) against a single binary target label. However, one may often observe multiple binary target labels, e.g., from distinct human annotators. How can one synthesize such labels into a single coherent ranking? In this work, we formally analyze two approaches to this problem -- loss aggregation and label aggregation -- by characterizing their Bayes-optimal solutions. Based on this, we show that while both methods can yield Pareto-optimal solutions, loss aggregation can exhibit label dictatorship: one can inadvertently (and undesirably) favor one label over others. This suggests that label aggregation can be preferable to loss aggregation, which we empirically verify.
DeepCrossAttention: Supercharging Transformer Residual Connections
Feb 10, 2025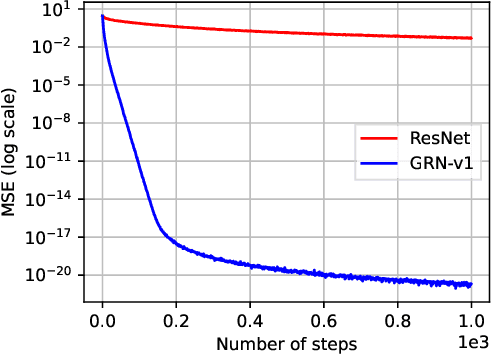
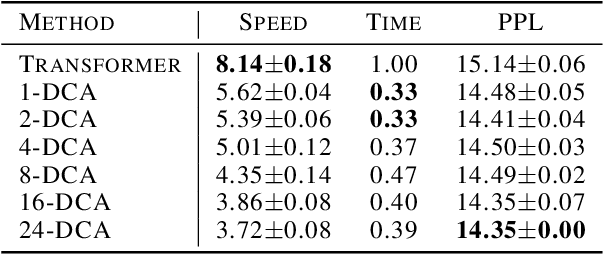
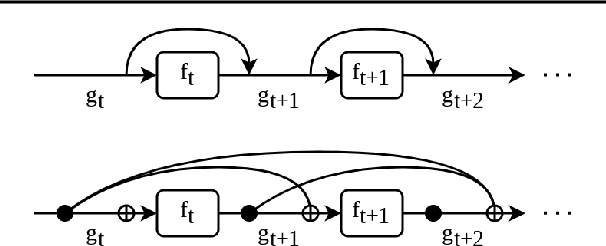
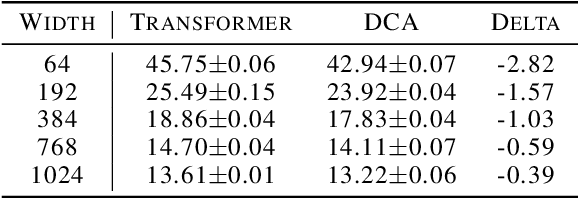
Transformer networks have achieved remarkable success across diverse domains, leveraging a variety of architectural innovations, including residual connections. However, traditional residual connections, which simply sum the outputs of previous layers, can dilute crucial information. This work introduces DeepCrossAttention (DCA), an approach that enhances residual learning in transformers. DCA employs learnable, input-dependent weights to dynamically combine layer outputs, enabling the model to selectively focus on the most relevant information in any of the previous layers. Furthermore, DCA incorporates depth-wise cross-attention, allowing for richer interactions between layers at different depths. Our language modeling experiments show that DCA achieves improved perplexity for a given training time. Moreover, DCA obtains the same model quality up to 3x faster while adding a negligible number of parameters. Theoretical analysis confirms that DCA provides an improved trade-off between accuracy and model size when the ratio of collective layer ranks to the ambient dimension falls below a critical threshold.
Correlation Matching Transformation Transformers for UHD Image Restoration
Jun 02, 2024This paper proposes UHDformer, a general Transformer for Ultra-High-Definition (UHD) image restoration. UHDformer contains two learning spaces: (a) learning in high-resolution space and (b) learning in low-resolution space. The former learns multi-level high-resolution features and fuses low-high features and reconstructs the residual images, while the latter explores more representative features learning from the high-resolution ones to facilitate better restoration. To better improve feature representation in low-resolution space, we propose to build feature transformation from the high-resolution space to the low-resolution one. To that end, we propose two new modules: Dual-path Correlation Matching Transformation module (DualCMT) and Adaptive Channel Modulator (ACM). The DualCMT selects top C/r (r is greater or equal to 1 which controls the squeezing level) correlation channels from the max-pooling/mean-pooling high-resolution features to replace low-resolution ones in Transformers, which can effectively squeeze useless content to improve the feature representation in low-resolution space to facilitate better recovery. The ACM is exploited to adaptively modulate multi-level high-resolution features, enabling to provide more useful features to low-resolution space for better learning. Experimental results show that our UHDformer reduces about ninety-seven percent model sizes compared with most state-of-the-art methods while significantly improving performance under different training sets on 3 UHD image restoration tasks, including low-light image enhancement, image dehazing, and image deblurring. The source codes will be made available at https://github.com/supersupercong/UHDformer.
How Powerful Potential of Attention on Image Restoration?
Mar 15, 2024



Transformers have demonstrated their effectiveness in image restoration tasks. Existing Transformer architectures typically comprise two essential components: multi-head self-attention and feed-forward network (FFN). The former captures long-range pixel dependencies, while the latter enables the model to learn complex patterns and relationships in the data. Previous studies have demonstrated that FFNs are key-value memories \cite{geva2020transformer}, which are vital in modern Transformer architectures. In this paper, we conduct an empirical study to explore the potential of attention mechanisms without using FFN and provide novel structures to demonstrate that removing FFN is flexible for image restoration. Specifically, we propose Continuous Scaling Attention (\textbf{CSAttn}), a method that computes attention continuously in three stages without using FFN. To achieve competitive performance, we propose a series of key components within the attention. Our designs provide a closer look at the attention mechanism and reveal that some simple operations can significantly affect the model performance. We apply our \textbf{CSAttn} to several image restoration tasks and show that our model can outperform CNN-based and Transformer-based image restoration approaches.
SequentialAttention++ for Block Sparsification: Differentiable Pruning Meets Combinatorial Optimization
Feb 27, 2024



Neural network pruning is a key technique towards engineering large yet scalable, interpretable, and generalizable models. Prior work on the subject has developed largely along two orthogonal directions: (1) differentiable pruning for efficiently and accurately scoring the importance of parameters, and (2) combinatorial optimization for efficiently searching over the space of sparse models. We unite the two approaches, both theoretically and empirically, to produce a coherent framework for structured neural network pruning in which differentiable pruning guides combinatorial optimization algorithms to select the most important sparse set of parameters. Theoretically, we show how many existing differentiable pruning techniques can be understood as nonconvex regularization for group sparse optimization, and prove that for a wide class of nonconvex regularizers, the global optimum is unique, group-sparse, and provably yields an approximate solution to a sparse convex optimization problem. The resulting algorithm that we propose, SequentialAttention++, advances the state of the art in large-scale neural network block-wise pruning tasks on the ImageNet and Criteo datasets.
Learning from Aggregate responses: Instance Level versus Bag Level Loss Functions
Jan 20, 2024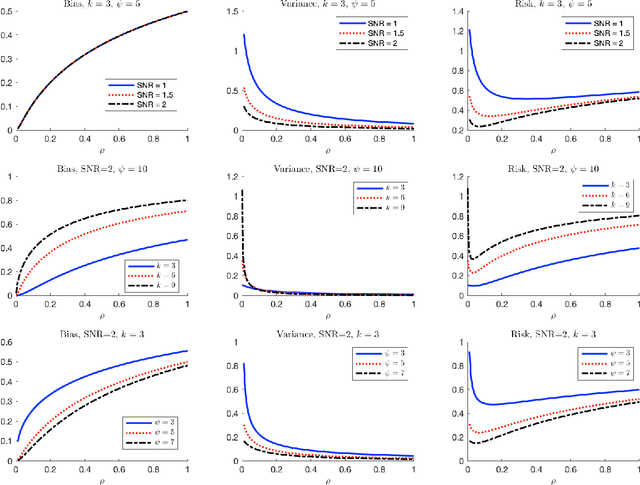
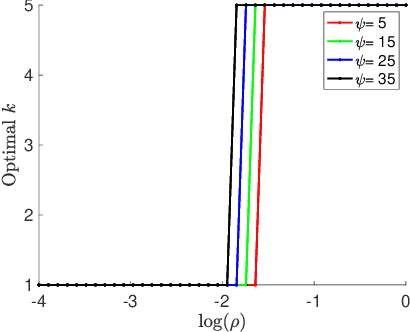
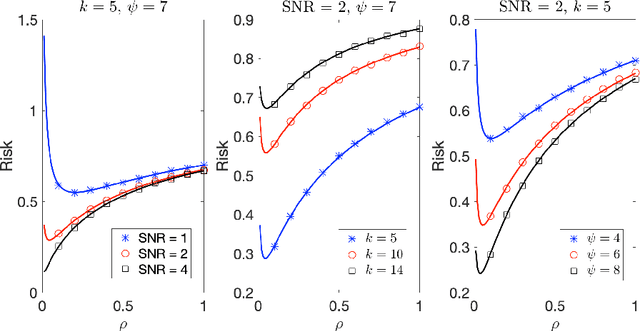
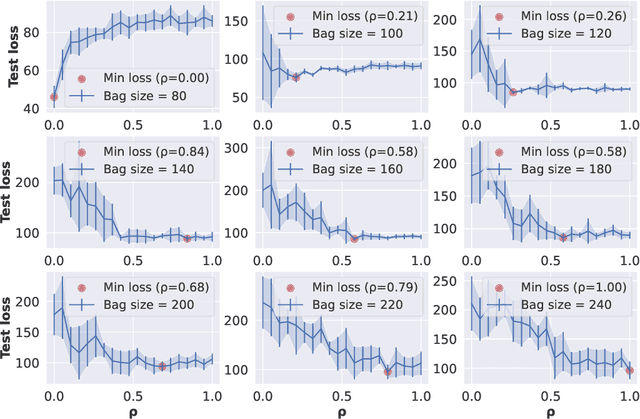
Due to the rise of privacy concerns, in many practical applications the training data is aggregated before being shared with the learner, in order to protect privacy of users' sensitive responses. In an aggregate learning framework, the dataset is grouped into bags of samples, where each bag is available only with an aggregate response, providing a summary of individuals' responses in that bag. In this paper, we study two natural loss functions for learning from aggregate responses: bag-level loss and the instance-level loss. In the former, the model is learnt by minimizing a loss between aggregate responses and aggregate model predictions, while in the latter the model aims to fit individual predictions to the aggregate responses. In this work, we show that the instance-level loss can be perceived as a regularized form of the bag-level loss. This observation lets us compare the two approaches with respect to bias and variance of the resulting estimators, and introduce a novel interpolating estimator which combines the two approaches. For linear regression tasks, we provide a precise characterization of the risk of the interpolating estimator in an asymptotic regime where the size of the training set grows in proportion to the features dimension. Our analysis allows us to theoretically understand the effect of different factors, such as bag size on the model prediction risk. In addition, we propose a mechanism for differentially private learning from aggregate responses and derive the optimal bag size in terms of prediction risk-privacy trade-off. We also carry out thorough experiments to corroborate our theory and show the efficacy of the interpolating estimator.
Greedy PIG: Adaptive Integrated Gradients
Nov 10, 2023



Deep learning has become the standard approach for most machine learning tasks. While its impact is undeniable, interpreting the predictions of deep learning models from a human perspective remains a challenge. In contrast to model training, model interpretability is harder to quantify and pose as an explicit optimization problem. Inspired by the AUC softmax information curve (AUC SIC) metric for evaluating feature attribution methods, we propose a unified discrete optimization framework for feature attribution and feature selection based on subset selection. This leads to a natural adaptive generalization of the path integrated gradients (PIG) method for feature attribution, which we call Greedy PIG. We demonstrate the success of Greedy PIG on a wide variety of tasks, including image feature attribution, graph compression/explanation, and post-hoc feature selection on tabular data. Our results show that introducing adaptivity is a powerful and versatile method for making attribution methods more powerful.
Towards High-Quality Specular Highlight Removal by Leveraging Large-Scale Synthetic Data
Sep 12, 2023
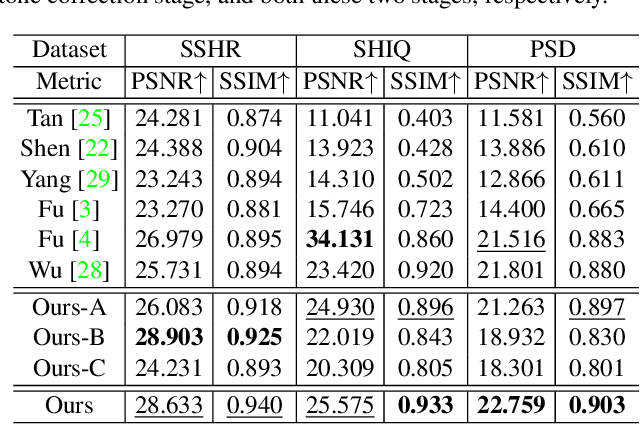
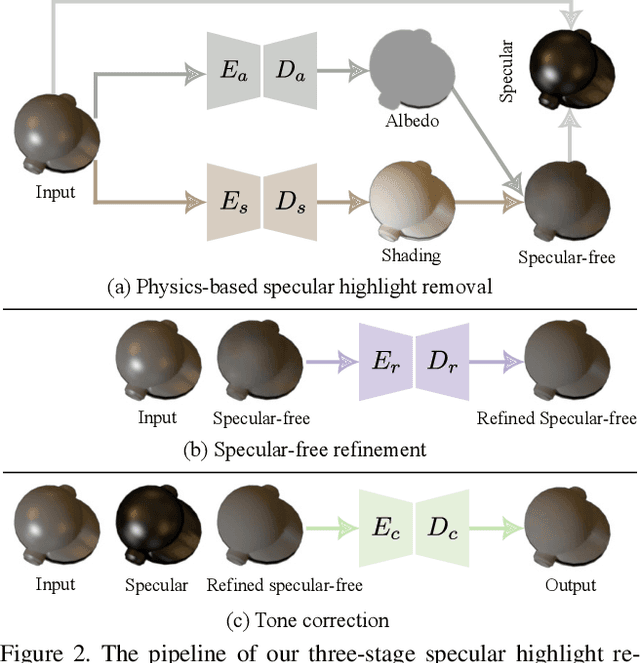

This paper aims to remove specular highlights from a single object-level image. Although previous methods have made some progresses, their performance remains somewhat limited, particularly for real images with complex specular highlights. To this end, we propose a three-stage network to address them. Specifically, given an input image, we first decompose it into the albedo, shading, and specular residue components to estimate a coarse specular-free image. Then, we further refine the coarse result to alleviate its visual artifacts such as color distortion. Finally, we adjust the tone of the refined result to match that of the input as closely as possible. In addition, to facilitate network training and quantitative evaluation, we present a large-scale synthetic dataset of object-level images, covering diverse objects and illumination conditions. Extensive experiments illustrate that our network is able to generalize well to unseen real object-level images, and even produce good results for scene-level images with multiple background objects and complex lighting.