 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCrossAttention: Supercharging Transformer Residual Connections
Paper and Code
Feb 10, 2025
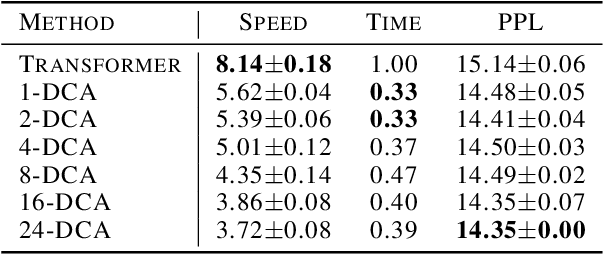
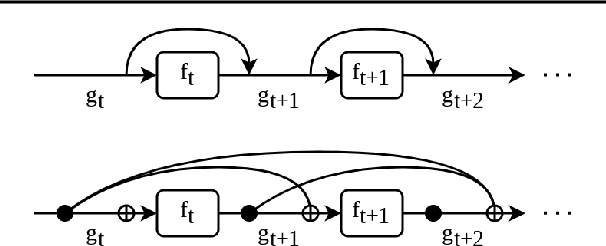
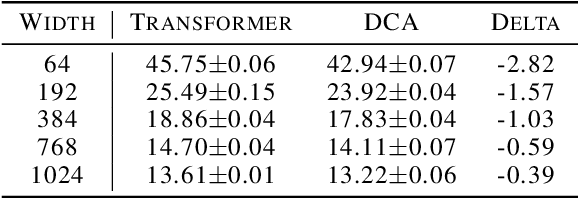
Transformer networks have achieved remarkable success across diverse domains, leveraging a variety of architectural innovations, including residual connections. However, traditional residual connections, which simply sum the outputs of previous layers, can dilute crucial information. This work introduces DeepCrossAttention (DCA), an approach that enhances residual learning in transformers. DCA employs learnable, input-dependent weights to dynamically combine layer outputs, enabling the model to selectively focus on the most relevant information in any of the previous layers. Furthermore, DCA incorporates depth-wise cross-attention, allowing for richer interactions between layers at different depths. Our language modeling experiments show that DCA achieves improved perplexity for a given training time. Moreover, DCA obtains the same model quality up to 3x faster while adding a negligible number of parameters. Theoretical analysis confirms that DCA provides an improved trade-off between accuracy and model size when the ratio of collective layer ranks to the ambient dimension falls below a critical threshold.