 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplicable Composition
Apr 12, 2026Replicability requires that algorithmic conclusions remain consistent when rerun on independently drawn data. A central structural question is composition: given $k$ problems each admitting a $ρ$-replicable algorithm with sample complexity $n$, how many samples are needed to solve all jointly while preserving replicability? The naive analysis yields $\widetilde{O}(nk^2)$ samples, and Bun et al. (STOC'23) observed that reductions through differential privacy give an alternative $\widetilde{O}(n^2k)$ bound, leaving open whether the optimal $\widetilde{O}(nk)$ scaling is achievable. We resolve this open problem and, more generally, show that problems with sample complexities $n_1,\ldots,n_k$ can be jointly solved with $\widetilde{O}(\sum_i n_i)$ samples while preserving constant replicability. Our approach converts each replicable algorithm into a perfectly generalizing one, composes them via a privacy-style analysis, and maps back via correlated sampling. This yields the first advanced composition theorem for replicability. En route, we obtain new bounds for the composition of perfectly generalizing algorithms with heterogeneous parameters. As part of our results, we provide a boosting theorem for the success probability of replicable algorithms. For a broad class of problems, the failure probability appears as a separate additive term independent of $ρ$, immediately yielding improved sample complexity bounds for several problems. Finally, we prove an $Ω(nk^2)$ lower bound for adaptive composition, establishing a quadratic separation from the non-adaptive setting. The key technique, which we call the phantom run, yields structural results of independent interest.
Chamfer-Linkage for Hierarchical Agglomerative Clustering
Feb 11, 2026Hierarchical Agglomerative Clustering (HAC) is a widely-used clustering method based on repeatedly merging the closest pair of clusters, where inter-cluster distances are determined by a linkage function. Unlike many clustering methods, HAC does not optimize a single explicit global objective; clustering quality is therefore primarily evaluated empirically, and the choice of linkage function plays a crucial role in practice. However, popular classical linkages, such as single-linkage, average-linkage and Ward's method show high variability across real-world datasets and do not consistently produce high-quality clusterings in practice. In this paper, we propose \emph{Chamfer-linkage}, a novel linkage function that measures the distance between clusters using the Chamfer distance, a popular notion of distance between point-clouds in machine learning and computer vision. We argue that Chamfer-linkage satisfies desirable concept representation properties that other popular measures struggle to satisfy. Theoretically, we show that Chamfer-linkage HAC can be implemented in $O(n^2)$ time, matching the efficiency of classical linkage functions. Experimentally, we find that Chamfer-linkage consistently yields higher-quality clusterings than classical linkages such as average-linkage and Ward's method across a diverse collection of datasets. Our results establish Chamfer-linkage as a practical drop-in replacement for classical linkage functions, broadening the toolkit for hierarchical clustering in both theory and practice.
Accelerating Scientific Research with Gemini: Case Studies and Common Techniques
Feb 03, 2026Recent advances in large language models (LLMs) have opened new avenues for accelerating scientific research. While models are increasingly capable of assisting with routine tasks, their ability to contribute to novel, expert-level mathematical discovery is less understood. We present a collection of case studies demonstrating how researchers have successfully collaborated with advanced AI models, specifically Google's Gemini-based models (in particular Gemini Deep Think and its advanced variants), to solve open problems, refute conjectures, and generate new proofs across diverse areas in theoretical computer science, as well as other areas such as economics, optimization, and physics. Based on these experiences, we extract common techniques for effective human-AI collaboration in theoretical research, such as iterative refinement, problem decomposition, and cross-disciplinary knowledge transfer. While the majority of our results stem from this interactive, conversational methodology, we also highlight specific instances that push beyond standard chat interfaces. These include deploying the model as a rigorous adversarial reviewer to detect subtle flaws in existing proofs, and embedding it within a "neuro-symbolic" loop that autonomously writes and executes code to verify complex derivations. Together, these examples highlight the potential of AI not just as a tool for automation, but as a versatile, genuine partner in the creative process of scientific discovery.
DeepCrossAttention: Supercharging Transformer Residual Connections
Feb 10, 2025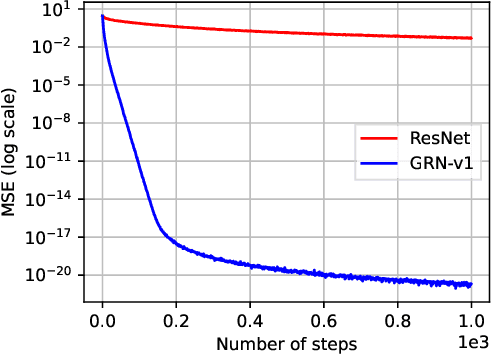
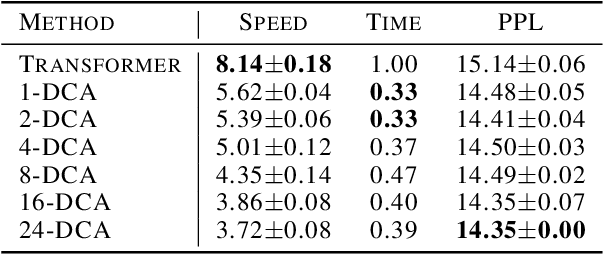
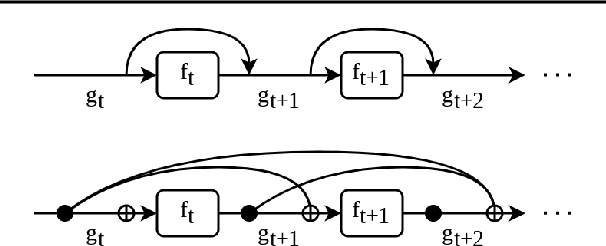
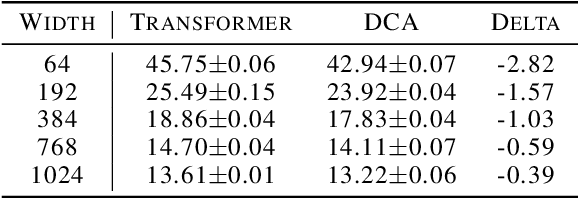
Transformer networks have achieved remarkable success across diverse domains, leveraging a variety of architectural innovations, including residual connections. However, traditional residual connections, which simply sum the outputs of previous layers, can dilute crucial information. This work introduces DeepCrossAttention (DCA), an approach that enhances residual learning in transformers. DCA employs learnable, input-dependent weights to dynamically combine layer outputs, enabling the model to selectively focus on the most relevant information in any of the previous layers. Furthermore, DCA incorporates depth-wise cross-attention, allowing for richer interactions between layers at different depths. Our language modeling experiments show that DCA achieves improved perplexity for a given training time. Moreover, DCA obtains the same model quality up to 3x faster while adding a negligible number of parameters. Theoretical analysis confirms that DCA provides an improved trade-off between accuracy and model size when the ratio of collective layer ranks to the ambient dimension falls below a critical threshold.
SequentialAttention++ for Block Sparsification: Differentiable Pruning Meets Combinatorial Optimization
Feb 27, 2024



Neural network pruning is a key technique towards engineering large yet scalable, interpretable, and generalizable models. Prior work on the subject has developed largely along two orthogonal directions: (1) differentiable pruning for efficiently and accurately scoring the importance of parameters, and (2) combinatorial optimization for efficiently searching over the space of sparse models. We unite the two approaches, both theoretically and empirically, to produce a coherent framework for structured neural network pruning in which differentiable pruning guides combinatorial optimization algorithms to select the most important sparse set of parameters. Theoretically, we show how many existing differentiable pruning techniques can be understood as nonconvex regularization for group sparse optimization, and prove that for a wide class of nonconvex regularizers, the global optimum is unique, group-sparse, and provably yields an approximate solution to a sparse convex optimization problem. The resulting algorithm that we propose, SequentialAttention++, advances the state of the art in large-scale neural network block-wise pruning tasks on the ImageNet and Criteo datasets.
A Scalable Algorithm for Individually Fair K-means Clustering
Feb 09, 2024



We present a scalable algorithm for the individually fair ($p$, $k$)-clustering problem introduced by Jung et al. and Mahabadi et al. Given $n$ points $P$ in a metric space, let $\delta(x)$ for $x\in P$ be the radius of the smallest ball around $x$ containing at least $n / k$ points. A clustering is then called individually fair if it has centers within distance $\delta(x)$ of $x$ for each $x\in P$. While good approximation algorithms are known for this problem no efficient practical algorithms with good theoretical guarantees have been presented. We design the first fast local-search algorithm that runs in ~$O(nk^2)$ time and obtains a bicriteria $(O(1), 6)$ approximation. Then we show empirically that not only is our algorithm much faster than prior work, but it also produces lower-cost solutions.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Agile Modeling: Image Classification with Domain Experts in the Loop
Feb 25, 2023

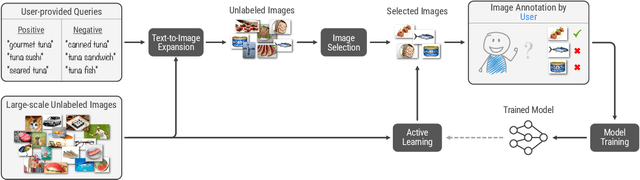
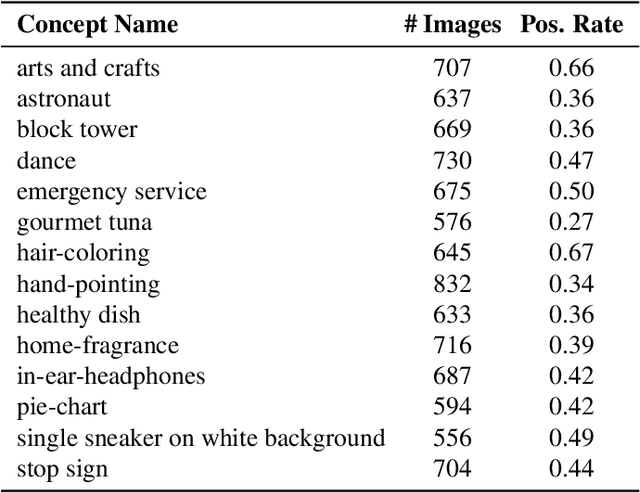
Machine learning is not readily accessible to domain experts from many fields, blocked by issues ranging from data mining to model training. We argue that domain experts should be at the center of the modeling process, and we introduce the "Agile Modeling" problem: the process of turning any visual concept from an idea into a well-trained ML classifier through a human-in-the-loop interaction driven by the domain expert in a way that minimizes domain expert time. We propose a solution to the problem that enables domain experts to create classifiers in real-time and build upon recent advances in image-text co-embeddings such as CLIP or ALIGN to implement it. We show the feasibility of this solution through live experiments with 14 domain experts, each modeling their own concept. Finally, we compare a domain expert driven process with the traditional crowdsourcing paradigm and find that difficult concepts see pronounced improvements with domain experts.
Sequential Attention for Feature Selection
Sep 29, 2022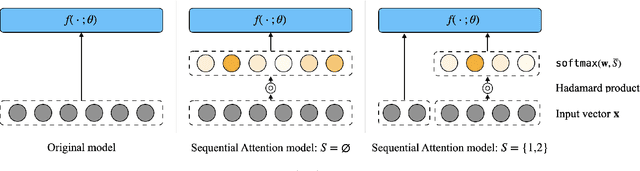
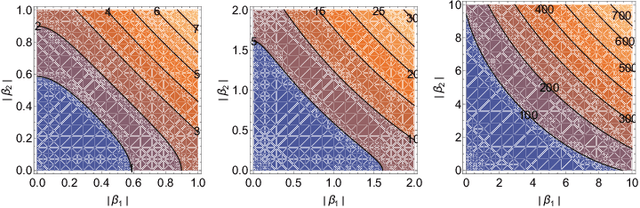
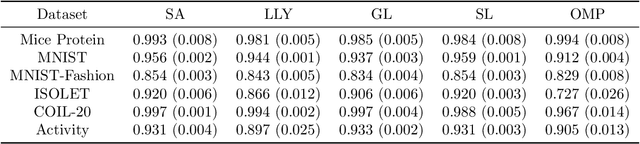
Feature selection is the problem of selecting a subset of features for a machine learning model that maximizes model quality subject to a resource budget constraint. For neural networks, prior methods, including those based on $\ell_1$ regularization, attention, and stochastic gates, typically select all of the features in one evaluation round, ignoring the residual value of the features during selection (i.e., the marginal contribution of a feature conditioned on the previously selected features). We propose a feature selection algorithm called Sequential Attention that achieves state-of-the-art empirical results for neural networks. This algorithm is based on an efficient implementation of greedy forward selection and uses attention weights at each step as a proxy for marginal feature importance. We provide theoretical insights into our Sequential Attention algorithm for linear regression models by showing that an adaptation to this setting is equivalent to the classical Orthogonal Matching Pursuit algorithm [PRK1993], and thus inherits all of its provable guarantees. Lastly, our theoretical and empirical analyses provide new explanations towards the effectiveness of attention and its connections to overparameterization, which might be of independent interest.
Tackling Provably Hard Representative Selection via Graph Neural Networks
May 20, 2022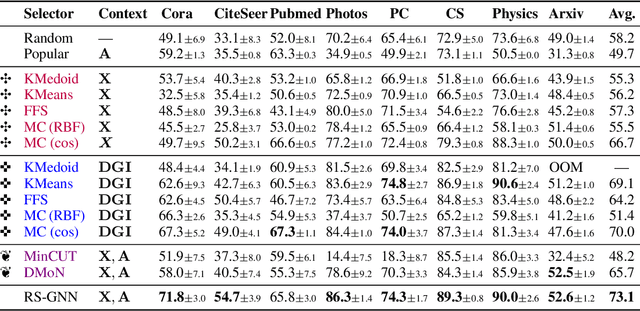
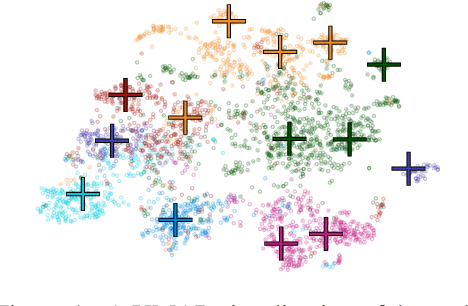
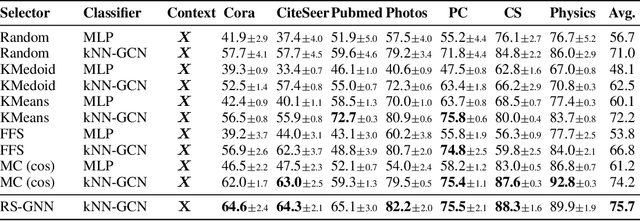
Representative selection (RS) is the problem of finding a small subset of exemplars from an unlabeled dataset, and has numerous applications in summarization, active learning, data compression and many other domains. In this paper, we focus on finding representatives that optimize the accuracy of a model trained on the selected representatives. We study RS for data represented as attributed graphs. We develop RS-GNN, a representation learning-based RS model based on Graph Neural Networks. Empirically, we demonstrate the effectiveness of RS-GNN on problems with predefined graph structures as well as problems with graphs induced from node feature similarities, by showing that RS-GNN achieves significant improvements over established baselines that optimize surrogate functions. Theoretically, we establish a new hardness result for RS by proving that RS is hard to approximate in polynomial time within any reasonable factor, which implies a significant gap between the optimum solution of widely-used surrogate functions and the actual accuracy of the model, and provides justification for the superiority of representation learning-based approaches such as RS-GNN over surrogate functions.