 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Complexity of 1-Center in Various Metrics
Dec 06, 2021We consider the classic 1-center problem: Given a set P of n points in a metric space find the point in P that minimizes the maximum distance to the other points of P. We study the complexity of this problem in d-dimensional $\ell_p$-metrics and in edit and Ulam metrics over strings of length d. Our results for the 1-center problem may be classified based on d as follows. $\bullet$ Small d: We provide the first linear-time algorithm for 1-center problem in fixed-dimensional $\ell_1$ metrics. On the other hand, assuming the hitting set conjecture (HSC), we show that when $d=\omega(\log n)$, no subquadratic algorithm can solve 1-center problem in any of the $\ell_p$-metrics, or in edit or Ulam metrics. $\bullet$ Large d. When $d=\Omega(n)$, we extend our conditional lower bound to rule out sub quartic algorithms for 1-center problem in edit metric (assuming Quantified SETH). On the other hand, we give a $(1+\epsilon)$-approximation for 1-center in Ulam metric with running time $\tilde{O_{\epsilon}}(nd+n^2\sqrt{d})$. We also strengthen some of the above lower bounds by allowing approximations or by reducing the dimension d, but only against a weaker class of algorithms which list all requisite solutions. Moreover, we extend one of our hardness results to rule out subquartic algorithms for the well-studied 1-median problem in the edit metric, where given a set of n strings each of length n, the goal is to find a string in the set that minimizes the sum of the edit distances to the rest of the strings in the set.
Learning Complexity of Simulated Annealing
Mar 06, 2020
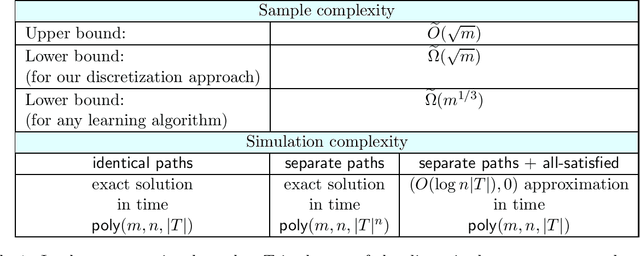
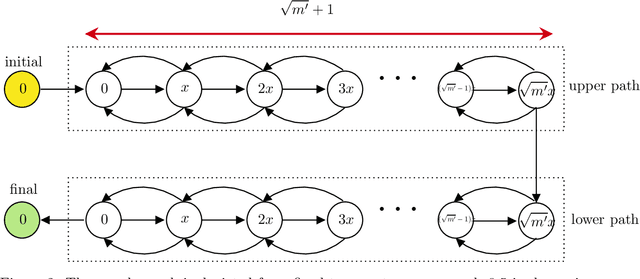
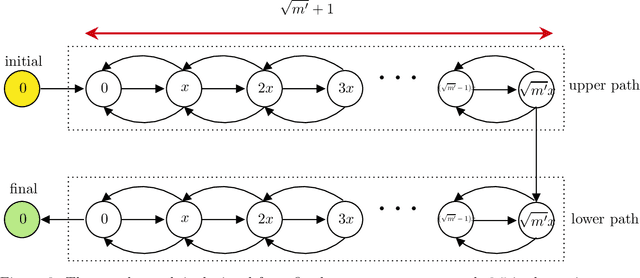
Simulated annealing is an effective and general means of optimization. It is in fact inspired by metallurgy, where the temperature of a material determines its behavior in thermodynamics. Likewise, in simulated annealing, the actions that the algorithm takes depend entirely on the value of a variable which captures the notion of temperature. Typically, simulated annealing starts with a high temperature, which makes the algorithm pretty unpredictable, and gradually cools the temperature down to become more stable. A key component that plays a crucial role in the performance of simulated annealing is the criteria under which the temperature changes namely, the cooling schedule. Motivated by this, we study the following question in this work: "Given enough samples to the instances of a specific class of optimization problems, can we design optimal (or approximately optimal) cooling schedules that minimize the runtime or maximize the success rate of the algorithm on average when the underlying problem is drawn uniformly at random from the same class?" We provide positive results both in terms of sample complexity and simulation complexity. For sample complexity, we show that $\tilde O(\sqrt{m})$ samples suffice to find an approximately optimal cooling schedule of length $m$. We complement this result by giving a lower bound of $\tilde \Omega(m^{1/3})$ on the sample complexity of any learning algorithm that provides an almost optimal cooling schedule. These results are general and rely on no assumption. For simulation complexity, however, we make additional assumptions to measure the success rate of an algorithm. To this end, we introduce the monotone stationary graph that models the performance of simulated annealing. Based on this model, we present polynomial time algorithms with provable guarantees for the learning problem.